CodeReview常见代码问题
CodeReview常见代码问题
路线图
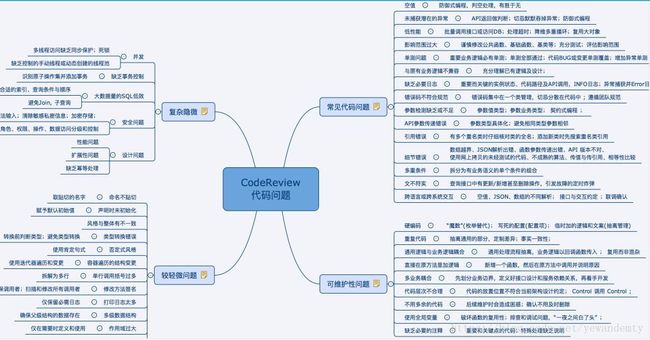
常见的问题
常见的潜在代码问题是当前直接会导致BUG、故障或者产品功能不能正常工作的类别。
空值:
空值恐怕是最容易出现的地方之一。 常见错误有: a. 值为NULL导致空指针异常; b. 参数字符串含有前导或后缀空格没有Trim导致查询为空。 导致以上结果的原因主要有: 无此记录、有此记录但由于SQL访问异常而没查到、网络调用失败、记录中有脏数据、参数没传。
原则上,对于任何异常, 希望能够打印出具体的错误信息,根据错误信息很快明白是什么原因, 而不是一个 null ,还要在代码里去推敲为什么为空。这样我们必须识别出程序中可能的null, 并及时检测、捕获和抛出异常。
对于空值,最好的防护是“防御式编程”。当获取到对象之后, 使用之前总是判断是否为空,并适当抛出异常、打错误日志或做其它处理。 有的人嫌检测为空的 if 语句充斥在代码里会破坏代码的可维护性, 对此我的建议是:
- 空值检测一定要有, 有胜于无。
- 在空值检测总是存在的前提下, 可以优化空值检测的方法和存在形式。 比如集中于一个类 NullChecker 中管理,并与系统的整体错误处理设计保持一致。集中管理和处理一致性原则可以作为系统设计的一个准则。 这样主流程中只要增加一行调用即可, 既可以天网恢恢疏而不漏地检测对象为空, 也不会让代码显得难看。
class NullChecker {
public static void checkNull(Object obj, Error error) {
if (obj == null) { throw new BizException(error); }
}
}- 在参数入口处统一做 trim。 如果在业务逻辑里做 trim , 就会导致有的业务逻辑做了 trim , 有的没做, 体现在产品上就会有令用户困惑的事情发生。 比如搜索和导出业务, 搜索能搜索出来, 导出却没有。
未捕获潜在的异常:
第二个容易出错的地方是未捕获潜在的异常。调用API接口、库函数或系统服务等,只顾着享受便利却不做防护,常导致因为局部失败而影响整体的功能。最好的防护依然是“防御式编程”。 要么在当前方法捕获异常并返回合适的空值或空对象,要么抛给高层处理。
切不可默默”吞掉错误和异常”。 如果这样做了, 出问题了等着加班和耗费大量脑细胞吧!
在CodeReview的时候一定要仔细询问:这里是否可能会抛出异常?如果抛异常会怎么处理?是否会影响整体服务和返回结果?
低性能:
低性能会导致产品功能不好用、不可用,甚至导致产品失败。
常见情况有:a. 循环地逐个调用单个接口获取数据或访问数据库; b. 重复创建几乎完全相同的(开销大的)对象;c. 数据库访问、网络调用等服务未处理超时的情况; d. 多重循环对于大数据量处理的算法性能低;e. 大量字符串拼接时使用了String而非StringBuilder.
对于 a,最好提供批量接口或批量并发获取数据; 对于 b, 将可复用对象抽离出循环,一次创建多次使用; 对于 c,设置合理的超时时间并捕获超时异常处理; 对于 d,使用预排序或预处理, 构造合适的数据结构, 使得算法平均性能在 O(n) 或 O(nlogn) ; 对于 e, 记住: 少量字符串拼接使用String, 大量字符串拼接使用 StringBuilder, 通常不会使用到 StringBuffer.
影响范围过大:
对多个模块依赖的公共函数的修改,容易造成影响范围超过当前业务改动,无意识地破坏依赖于该公共函数的其他业务。要特别慎重。可靠的方式是:先查看该公共函数的调用, 如果只有自己的业务用,可适当大胆一些; 如果有多个地方依赖,抽离一个新的函数,抽离原函数里的可复用部分,然后基于可复用部分构建新的函数。修改原则遵循“开闭”原则,才能尽可能使改动影响降低到最小化。
基类及实例字段和方法也属于公共函数的范畴。 尽量不要修改基类的东西。
单测问题:
单测是保证工程质量的第一道重要防线。单测问题一般包括: a. 单测未全部通过; b. 重要业务逻辑缺乏单测; c. 缺乏异常单测; d. 代码变更或BUG修复缺乏单测。
单测全部通过应当是提交代码到代码库以及代码Review的前提条件。代码提交者应当保证单测全部通过。没有捷径可走。仅当单测全部通过才提交到代码库, 可以通过工具自动化实现。 对于 maven 管理的工程, 只需一个命令: mvn test && git push origin branch_name 。 单测应当更注重质,而非单纯追求覆盖率。
缺乏单测的重要业务逻辑就像裸露在空气中的电线一样,虽然能跑起来,却是很容易“触电”的。 方法: 增加覆盖比较全面的单测。
缺乏异常单测也是代码提交者常忽略的问题。 异常也是一种实际的业务场景,反映系统的健壮性和友好性。异常应该有相应的单元测试覆盖。创建条件使之抛出异常,并判断异常是否是指定异常;若没有抛出异常或者不是指定异常,则应该 AssertFailed 而不是通过。
对于代码变更和BUG修复,如果当时由于时间紧而没有写,后续应当补上。对于每个代码变更和BUG,都可以抽离出相应的代码部分, 并有相应单测覆盖,并注明原因。
与原有业务逻辑不兼容:
改动针对当前需求是合理的,却与原有业务逻辑不兼容,也是常见的问题。比如增加一个搜索条件, 却不能与原有条件联合查询。
与原有业务不兼容, 一般出现在:
- 一对一与一对多的变化。 比如原来的关系是一个订单对应一个物流信息, 后来变化为一个订单可能对应多个物流信息; 原来的逻辑是一个订单显示多个物流信息可以更改,后来要求一个订单只展示最近一次的物流信息可以修改。
- 多个业务组合。 业务 A 与业务 B 原来是分开发展的, 后来开展一种活动,将业务A与业务B进行一种组合营销。 此时,多半会出现很多 if-else 语句。
业务逻辑的兼容问题一般体现在系统的复用性和可扩展机制上。良好的系统可复用性和可扩展性可以更容易地做到业务逻辑兼容。 主要有如下几种级别:
- 自动兼容。 增加一种类型, 只是 biz_type 的值多了一种, 系统自动将已有功能适配给新的 biz_type;
- 一点改动。增加一个分支语句, 对 biz_type 的某个特性进行扩展;
- 一些改动。 需要见缝插针地增加一个单独的分支判断和逻辑处理模块, 对整体可扩展性没有影响, 但会造成局部的复杂化;
- 一部分功能改动。 只需要对其中一个功能模块做个扩展;
- 多处改动。 需要对多个功能模块做相应的改造,不过更多是新增而不是修改;
- 难以改动。 需要深入到功能模块内部做艰难的修改, 并要保证原有功能不受影响。
如何应对呢?
- 针对关联关系, 在项目之初, 可以询问清楚: 将来在产品上是否有可扩展的变化? 及早预留空间, 或者确定产品上的对策; 在代码实现上, 兼顾考虑一对一到一对多,或一对多到一对一的关联变化。比如使用列表来表达单个信息, 使用索引从列表中获取单个信息。
- 针对业务组合, 明确各业务的核心部分, 抽离出业务的可复用的部分,形成 API ; 考虑组合模式和装饰器模式来进行扩展。
缺乏必要日志:
对于重要而关键的实例状态、代码路径及API调用,应当添加适当的INFO日志;对于异常,应当捕获并添加Error日志。缺乏日志并不会影响业务功能,但出现问题排查时,就会非常不方便,甚至错失极宝贵的机会(不易重现的情况尤其如此)。此外,缺乏日志也会导致可控性差,难以做数据统计和分析。
错误码不符合规范:
错误码本身不算是代码问题,不过基于整个组织和工程的可维护性来说,可以将错误码不符合规范作为一种错误加以避免。方法: 对错误码进行可控的管理和遵循规范使用。可以使用公共文档维护, 也可以开发错误码管理系统来避免相同的错误码。
参数检测缺乏或不足:
参数检测是对业务处理的第一层重要过滤。如果参数检测不足够,就会导致脏数据进入服务处理,轻则导致异常,重则插入脏数据到数据库,对后续维护都会造成很多维护成本。方法: 采用“契约式编程”,规定前置条件,并使用单测进行覆盖。
对于复杂的业务应用, 优雅的参数检测处理尤为重要。 根据 “集中管理和处理一致性原则”, 可以建立一个 paramchecker 包, 设计一个可复用的微框架来对应用中所有的参数进行统一集中化检测。参数检测主要包括: (1) 参数的值类型, 可以根据不同值类型做基础的检测; (2) 参数的业务类型, 有基础非业务参数, 基础业务参数和具体业务参数。 不同的参数业务类型有不同的处理。 将参数值类型与参数业务类型结合起来, 结合一致性的异常捕获处理, 就可以实现一个可复用的参数检测框架。参数检测既可以采用普通的分支语句,也可以采用注解方式。采用注解方式更可读,不过单测编写更具技巧。
引用错误:
对于动态语言, 由于缺乏强大的静态代码检测,修改了类引用的地方尤其要注意,很可能导致依赖的其他业务出错; 尤其是修改重名引用时。有线上故障教训。PHP工程中含有两个 Format 类, 一个基础的一个业务相关的, 被改动的类文件里开始没有指明引用,默认采用了基础 Format 类的实现, 然后提交者在改动文件头增加了对业务 Format 的引用, 导致依赖于基础Format类的其他业务不能正常工作。避免引用错误的方法: 当要在文件里增加新的类引用时, 先在文件里搜索是否有重名类的引用。如果有, 就要格外小心了。
细节错误:
比如数组越界、JSON解析出错、函数参数传递出错、API 版本不对、使用网上拷贝的未经测试的代码、不成熟的算法、传值与传引用、相等性比较等。
对于数组越界错误, 通常要对空数组、针对数组大小的边界值+1和-1写单测来避免; 使用网上拷贝的代码,诚然可节省时间,也一定要加工一下并用单测覆盖; 传值和传引用可通过单测来避免错误; 对象的相等性比较切忌使用等号=。
多重条件:
类似 if ((!A || !B) && C || (D && E)) 的多重条件要仔细推敲。方法: 最好拆分成多个有含义变量。 isNotDelay = !A || !B ; isNormal = C ; isAllow = D && E ; cond = isNotDelay && isNormal || isAllow 。
文不符实:
文不符实是一种可能导致线上故障的错误。比如一个 getXXX 的函数,结果里面还做了 add, update 的操作。对问题排查、产品运维等都有非常大的杀伤力。因此命名一定要用实质内容相符,除非是故意搞破坏。
跨语言或跨系统交互:
稍具规模的互联网创业公司通常会采用多语言开发,比如PHP作为前端,Java作为后台服务。当动态类型语言与静态类型语言交互时,会有一些问题产生。比如PHP的对象通常是一个Map, 如果是空对象就会写成 [], 然而 [] 会被 Java 解析成列表。这样, 如果数据库的值是通过 PHP 写入,那么这个值既有可能是JSON对象字符串,也可能是空数组字符串, Java 来解析就有点尴尬了。 同样,当 Java 调用 PHP 接口时, 不规范的PHP接口既可能返回列表,也可能返回 true or false , Java 解析返回结果也会比较尴尬。 因此, 在跨语言交互的边界处,要特别注意这些类型转换的差异。
跨系统交互则主要是接口设计与约定的问题。同一个项目里不同业务团队之间的业务接口设计与约定, 不同企业里开放接口的设计与约定, 要在最初深思熟虑,一旦开放,在后期很少有接口设计改动的空间。开放接口设计要符合小而美、正交的特性, 命名要贴切一致, 参数取值要指明约束,枚举参数要给出列表, 结果返回要规范一致,可以采用通用的 {“code”:200, “msg”: “success”, “data”: xxx} 。跨系统交互也要统一对术语和接口的理解的一致。
可维护性问题
可维护性问题是“在当前业务变更的范围内通常不会导致BUG、故障,却会在日后埋下地雷,引发BUG、故障、维护成本大幅增加”的类别。
硬编码:
硬编码主要有三种情况: a. “魔数”; b. 写死的配置; c. 临时加的逻辑和文案。
“魔数”与重复代码类似,当前或许不会引发问题,时间一长,为了弄清楚其代表的含义,增加很多沟通维护成本,且分散在各处很容易导致修改的时候遗漏不一致。务必清清除。方法也比较简单:定义含义明显的枚举或常量,代表这个魔数在代码中发言。
“写死的配置”不会影响业务功能, 不过在环境变更或系统调优的时候,就显得很不方便了。 方法: 尽量将配置抽离出来做成配置项放到配置文件里。
“临时加的逻辑和文案”也是一种破坏系统可维护性的做法。方法: 抽离出来放在单独的函数或方法里,并特别加以注释。
重复代码:
重复代码在当前可能不会造成 BUG,但上线后,需要维护多处的事实一致性;时间一长,后续修改的时候就特别容易遗漏或处理不一致导致 BUG;重复代码是公认的“代码坏味”,必当尽力清除。方法: 抽离通用的部分,定制差异。重复代码还有一种情况出现,即创造新函数时,先看看是否既有方法已经实现过。
通用逻辑与定制业务逻辑耦合
这大概是每个媛猿们在开发生涯中遇到的最恶心的事情之一了。通用逻辑与具体的各种业务逻辑混杂交错,想插根针都难。遇到这种情况,只能先祈福,然后抽离一个新的函数,严格判断相应条件满足后去调用它。
如果是新创建逻辑,可以使用函数式编程或基于接口的编程,将通用处理流程抽离出来,而将具体业务逻辑以回调函数的形式传入处理。
不要让不同的业务共用相同的函数,然后在函数里一堆 if-else plus switch , 而是每个业务都有各自的函数, 并可复用相同的通用逻辑和流程处理; 或者各个业务可以覆写同样命名的函数。
直接在原方法里加逻辑:
有业务改动时,猿媛们图方便倾向于直接在原方法里加判断和逻辑。这样做是很不好的习惯。一方面,增加了原方法的长度,破坏了其可维护性;另一方面,有可能对原方法的既有逻辑造成破坏。 可靠的方式是: 新增一个函数,然后在原方法中调用并说明原因。
多业务耦合:
在业务边界未仔细划分清晰的情况下出现,一个业务过多深入和掺杂另一个非相关业务的实现细节。在项目和系统设计之初,特别要注意先划分业务边界,定义好接口设计和服务依赖关系,再着手开发;否则,延迟到后期做这些工作,很可能会导致重复的工作量,含糊复杂的交互、增加后期系统维护和问题排查的许多成本。磨刀不误砍柴工。划分清晰的业务、服务、接口边界就属于磨刀的功夫。
代码层次不合理:
代码改动逻辑是正确的,然而代码的放置位置不符合当前架构设计约定,导致后续维护成本增加。
代码层次不合理可能导致重复代码。比如获取操作人和操作记录,如果写在类 XController 里, 那么类 YController 就面临尴尬局面: 如果写在 YController , 就会导致重复代码; 如果跨层去调用 XController 方法,又是非常不推荐的做法。因此, 获取操作人和操作记录,最好写在 Service 层, Controller 层只负责参数传入、检测和结果转译、返回。
不用多余的代码:
工程中常常会有一些不用的代码。或者是一些暂时未用到的Util工具或库函数,或者是由于业务变更导致已经废弃不用的代码,或者是由于一时写出后来又重写的代码。尽量清除掉不用多余的代码,对系统可维护性是一种很好的改善,同时也有利于CodeReview。
使用全局变量:
使用全局变量并没有“错”,错的是,一旦出现问题,排查和调试问题起来,真的会让人“一夜之间白了头”,耗费数个小时是轻微惩罚。此外,全局变量还能“顺手牵羊”地破坏函数的通用性,导致可维护性变差。务必消除全局变量的使用。当然,全局常量是可以的。
缺乏必要的注释:
对重要和关键点的代码缺乏必要的注释,使用到的重要算法缺乏必要的引用出处,对特别的处理缺乏必要的说明。
原则上, 每个方法至少要用一个简短的单行注释, 适宜地描述了方法的用途、业务逻辑、作者及日期。对于特殊甚至奇葩的需求的特别实现,要加一些注释。 这样后续维护时有个基础。
更难发现的错误
更难发现的错误是指“复杂并发场景下的有一定技术难度的、需要丰富开发与设计经验才能看出来的错误”。
并发:
并发的问题更难检测、复现和调试。常见的问题有:a. 在可能由多线程并发访问的对象中含有共享变量却没有同步保护;b. 在代码中手动创建缺乏控制的线程或线程池;c. 并发访问数据库时没有做任何同步措施;d. 多个线程对同一对象的互斥操作没有同步保护。
对于 a, 在大部分Java应用中,通常由Spring框架来控制和创建请求和服务实例,因此,保证“Controller, Service 类中的实例变量只允许 Service, DAO 的单例,不允许业务变量实例”基本确保没有并发不正确更新的问题;不过,包含缓存策略的对象要特别注意多线程并发访问的问题,出于性能考量, 尽量只对共享实例部分加锁。
对于 b, 禁止在应用中手动创建线程或线程池,失控的线程池很容易导致应用崩溃(有线上应用崩溃的教训)。
对于 c, 并发访问数据库时,要特别注意时序和状态同步。如果时序控制不对,会导致状态同步和更新出错。
对于 d, 对同一对象的互斥操作需要加分布式锁同步。
使用线程池、并发库、并发类、同步工具而不是线程对象、并发原语。在复杂并发场景下,还需注意多个同步对象上的锁是否按合适的顺序获得和释放以避免死锁,相应的错误处理代码是否合理。
事务:
事务方面常出现的问题是:多个紧密关联的业务操作和 SQL 语句没有事务保证。 在资金业务操作或数据强一致性要求的业务操作中,要注意使用事务,保证数据更新的一致性和完整性。
SQL问题
SQL的正确性通常可以通过 DAO 测试来保证。 SQL问题主要是指潜在的性能问题和安全问题。
要避免SQL性能问题, 在表设计的时候就要做好索引工作。在表数据量非常大的情况下,SQL语句编写要非常小心。查询SQL需要添加必要索引,添加合适的查询条件和查询顺序,加快查询效率, 避免慢查; 尽量避免使用 Join, 子查询;避免SQL注入。
安全问题:
安全问题一向是互联网产品研发中极容易被忽视、而在爆发后又极引发热议的议题。安全和隐私是用户的心理红线之一。应用、数据、资金的安全性应当仅次于产品功能的准确性和使用体验。
安全问题的CodeReview可参见检查点清单:信息安全 。主要是如下措施: a. 严格检查和屏蔽非法输入; b. 对含敏感信息的请求加密通信; c. 业务处理后消除任何敏感私密信息的任何痕迹; d. 结果返回前在反序列化中清除敏感私密信息; e. 敏感私密信息在数据存储设备中应当加密存储; f. 应用有严格的角色、权限、操作、数据访问分级和控制; g. 切忌暴露服务器的重要的安全性信息,防止服务器被攻击影响正常服务运行。
设计问题:
设计问题通常体现在: a. 是否有潜在的性能问题; b. 是否有安全问题; c. 业务变化时是否容易扩展; d. 是否有遗漏的点。
较轻的问题
较轻微问题是指“没有技术难度、通过良好习惯即可避免的问题”。
较轻微问题一般不会造成负面影响的BUG或故障,不过建立一些好的习惯,主动使用代码检测工具,消除这些较轻微错误,也是一种修行。
命名不贴切:
命名不贴切不会影响功能实现,却会误导理解或增加理解难度。
方法:先查查字典,找个通俗易懂而且比较贴近的名字。可以参考 jdk 的命名、通用词汇和行业词汇; 作用域小的采用短命名,作用域大的采用长命名。取名字是一种重要技能,—— 多少父母为此愁灰了头!
声明时未初始化:
声明时未初始化通常情况下都不会是问题,因为后面会进行赋值。不过,如果赋值的过程中出现异常,那么可能会返回空值,从而导致空值异常。通常,变量声明时赋予默认初始值是个好习惯。
风格与整体有不一致:
工程通常求稳,一致性能更好地维护。在工程项目中,最好能够遵循工程约定的风格,在个人项目中可以凸显个性风格。Java编程一般要遵循《Java编程规范》,有追求的程序猿媛还会追求更高层次的,比如《Google Java 规范》等。
类型转换错误:
编程语言的类型系统是非常重要的。如何在不同类型之间可靠地互转,尤其是在父子类型之间相互赋值,也是一个微技能。滥用类型转换,也会导致BUG 。
Java 中容易出现的错误是:a. 字符串转数值,字符串含有非数字部分;b. JSON字符串转对象,某个字段含有不兼容的值类型导致解析出错;c. 子类型转不兼容的父类型,滋生运行时异常 ClassCastException;d. 相同特质的类型不兼容。比如 Long 与 Integer 都是数值型,却不能互转。
类型转换中最容易出BUG的地方是非布尔类型取反。受C语言的影响,很多高级语言支持各种数据类型转布尔类型,比如 PHP 字符串、数组、数字等都可以转布尔类型,相应的就喜欢写 if (!notBoolVar) 这种表达式, 容易隐藏看不出的BUG甚至错误。
否定式风格:
变量含义、表达式语句倾向于使用否定式风格,可能不知不觉耗费大量脑细胞,因为每次理解的时候都要绕个弯子。 比如 isNoExpress 是否无需物流, 就有点绕。 为什么呢? 无需物流是针对快递发货的, 如果快递发货占发货的90%, 无需物流只占10%,那么, isNoExpress = false 几乎总为真。 涉及到判断的时候,可能不得不写 if (!isNoExpress) , 双重否定足够弄晕你。
容器遍历的结构变更: API参数传递错误: 单行调用括号过多: 修改方法签名: 打印日志太多: 多级数据结构: 作用域过大: 分支与循环: 注:本文转载自下面链接
绝大多数语言都承袭了 C 语言的 for(int i=0;i
如果API参数有多个,而且相邻参数的类型相同,那么要特别留意是否参数顺序是正确的,而不会张冠李戴。
当然,在设计API参数的时候,就可以仔细用更精准类型进行区分,并将相同类型的参数错开。比如 calc(int accountNo, int pay, int timestamp) , 就容易传错,比较可靠的是 calc(int accountNo, Currency pay, Timestamp now) ,这样是不可能将参数传递错误的。
为了简便,常常会写出 wapper(calc(now, String.format(“%s\n”, new BufferedFileReader(filename, “UTF-8″).readLines() ))) 的语句 , 嗯,你得好好瞧瞧和算算右边的括号数量是否正确了。更糟糕的时候,结合API参数传递错误,IDE 可能没有报错, 而你很可能没有意识到自己的参数传递错误了。 可靠的方式是, 拆出一部分变量,并将调用之间的括号用空格隔开,显示出层次感。String fileContent = new BufferedFileReader(filename, "UTF-8").readLines();
wapper( calc( now, String.format("%s\n", fileContent) ) )
对某个方法有业务改动时,程序猿媛们倾向直接修改原方法的签名。这时,要特别注意:a. 不要修改原方法的参数顺序; b. 在最后面增加可选参数。 从另一个角度来看,复杂的业务方法应当分两层: 最外层负责调度,方法参数具有包容性,里面包含的字段比较多 ; 内层方法负责特定业务逻辑的实现,方法参数少而精。
修改原方法签名本身就是容易产生问题的习惯, 篡改原方法的参数顺序更是大忌。 最好的方法是新建一个方法去复用原方法, 然后调用新的方法。代码变更始终铭记“开闭”原则。
打印过多的日志并不好。一方面遮掩真正需要的信息,导致排查耗费时间, 另一方面造成服务器空间浪费、影响性能。生产环境日志一般只开放 INFO及以上级别的日志; Debug 日志只在调试或排错的时候使用,生产环境可以禁止debug日志。
使用多级数据结构时,要确定父级数据一定有值,或者进行检测。比如 order[′baole′][′ump′][′money′],必须确保 o r d e r [ ′ b a o l e ′ ] [ ′ u m p ′ ] [ ′ m o n e y ′ ] , 必 须 确 保 order[‘baole’], $order[‘baole’][‘money’] 一定有值或做非空检测。
由于C语言的影响,猿媛们会在开头就定义好一些变量或要返回的对象,在很靠后的地方才使用到。不必要的过大的作用域对变量和对象的变化产生不可测的影响,并增大理解的成本。可靠的方法是,仅当在使用时才定义,并尽快返回结果。
另一种情况是,暴露的访问域过大,比如 public 字段。 尽可能地缩小可访问的范围,可以增大变更和重构的空间; 减少可变性,则可以自然地获得并发安全性,降低CodeReview的理解成本。
比如,不可变的类和字段定义成 final , 最小化包,类,接口,方法和域的可访问性,默认为 private , 若需要继承,可定义为 protected , 仅当需要作为 API 服务暴露出去时,使用 public.
条件与循环偶尔也会导致错误, 不过通常错误可以在发布前解决掉。
对于 if-else 嵌套条件, 需要仔细检查是否符合业务逻辑; 如果嵌套太深,是否可以使用另一种方式“解结” ; 对于 switch 语句, 大多数语言的 case 有 fall through 问题, 要注意加上 break ; 最好加上 default 的处理。
对于 for 循环, 编写合理的结束条件避免死循环; 对于循环变量的控制, 避免出现 -1或 +1 错误, 消除越界错误; for 循环也要特别注意对空值和空容器的处理,避免抛出空值异常。可以通过单测来确保 for 循环的准确性。
https://mp.weixin.qq.com/s/Q11i5ZiZNs287zBIiYw1EQ