RocketMQ学习笔记【一】RocketMQ简介
一、为什么选用RocketMQ
目前主流的MQ有RocketMQ、Kafka、RabbitMQ、ActiveMQ等,那么开发者应该如何选用合适的MQ中间件呢?(面试官可能也会问为什么你们公司使用某个MQ)。个人觉得以下几个方面都是在MQ选择需要考虑的:
1、目前来看,每种MQ都有自身的优缺点,要结合这些MQ的特性比对我们的实际业务场景,选出最适合业务的。有的业务可能追求高吞吐量,可靠性要求低一些,比如日志系统;有的业务可能追求高可靠性,数据不能丢失,吞吐量可以小一些,比如交易系统。要明确不是根据技术选择,而是根据实际业务场景选择;
2、所选MQ的可维护性和可拓展性。小公司的话,如果是服务部署在云服务器上,现在基本云服务厂商都会提供配套的MQ中间件,比如阿里云的ons、华为云DMS,成本可以承受的话,可以直接配套使用,界面友好,维护简单。大厂的话,因为上述MQ可能与实际的业务匹配度还是不够以及自身技术储备足够,会选择自己开发或者对开源产品进行二次开发,这就需要考虑可拓展性。如果二次开发对开源产品进行定制,需要考虑选取MQ的开发语言。比如,Kafka是用Scala开发的,RabbitMQ是用的Erlang语言,这就对使用者的相关开发语言能力提出了要求,你如果想改造Kafka更贴合实际业务,最基本的必须要熟练掌握Scala才行吧;
3、选择开源MQ的话,也要考虑社区的活跃性。社区的力量是巨大的,社区越活跃,能提供的支持就越多,使用中发现了问题也能推动产品迭代版本解决。选择一个小众冷门的MQ,如果出了问题,可能得到的支持有限,难以排查问题。
讲了这么多,看一下RocketMQ官网上是如何说为什么选用RocketMQ的?
“Based on our research, with increased queues and virtual topics in use, ActiveMQ IO module reaches a bottleneck. We tried our best to solve this problem through throttling, circuit breaker or degradation, but it did not work well. So we begin to focus on the popular messaging solution Kafka at that time. Unfortunately, Kafka can not meet our requirements especially in terms of low latency and high reliability, see here for details.”
RocketMQ官网链接:http://rocketmq.apache.org/docs/motivation/
大致就是说基于研究,随着消息队列queue的增加以及virtual topic的使用,ActiveMQ IO模块遇到了瓶颈。虽然做了种种努力尝试进行解决,但是效果并不理想。于是,开始关注流行的消息传递解决方案Kafka。不幸的是,Kafka不能满足我们的要求,特别是在低延迟和高可靠性方面。在附的链接中,提到了
“Kafka是一个分布式流媒体平台,它源自于日志聚合案例。它不需要太高的并发性。在阿里巴巴的一些大型案例中,我们发现原来的模式已经不能满足我们的实际需求。因此,我们开发了一个名为rocketmq的消息传递中间件,它可以处理广泛的用例,从传统的发布/订阅场景到要求高容量、不允许消息丢失的实时事务系统。现在,在阿里巴巴,Rocketmq集群每天处理超过5000亿个事件,为超过3000个核心应用程序提供服务。”
并且给出了为什么Kafka不能支持更多分区(Partition)的原因:
1、Kafka每个分区Partition存储整个消息数据。虽然每个分区都是有序地写入磁盘的,但是随着同时写入分区的数量增加,从操作系统的角度来看,写入变得随机。
2、由于数据文件分散,很难使用LinuxIO组提交机制。
这里要简单介绍一下Kafka的一点知识,Kafka中每个Topic会对应多个分区Partition(至少有一个Partition),同一个Topic下的不同Partition包含的消息是不同的,并且同一Topic的不同分区会分配在不同的Broker(可以简单认为是一台物理服务器)上。Partition在逻辑上对应一个Log,Log是一个逻辑概念,可以对应到磁盘上的一个文件夹。在 Kafka中,生产者发送消息,实际上是把消息写入分区Partition对应的Log中。Log由多个Segment段组成,每个Segment对应一个日志文件和索引文件。正如第一点所说的,虽然 Kafka采用顺序I/O,每次只向最新的Segment追加消息数据,但这只是每个Partition内部的写入,同时有多个Partition进行写入操作,在操作系统来看就是随机写入了。因为上面Topic、Log和Segment的设计,消息数据文件确实是分散的。
再来看看RocketMQ是如何支持多分区的:
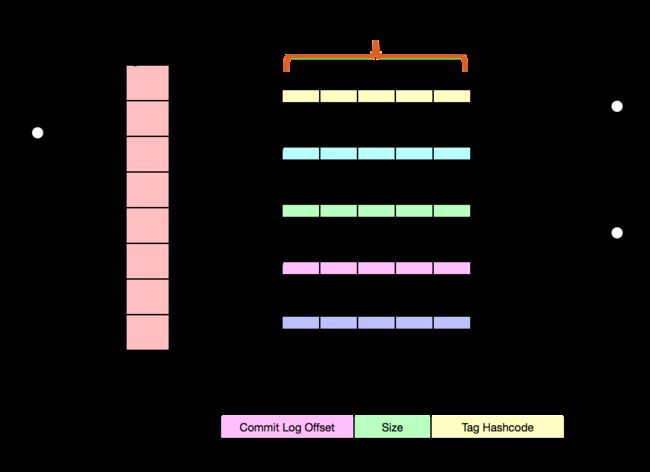
图片来自官网
1、所有消息数据都存储在提交日志文件中。所有写入都是完全连续的,而读取是随机的;
2、消息队列(ConsumeQueue)存储实际的用户消费位置信息(Offset in CommitLog),这些信息也按顺序刷新到磁盘。
每个消费队列都是轻量级的,并且包含有限数量的元数据。
对磁盘的访问是完全连续的,这样可以避免磁盘锁争用,并且在创建大量队列时不会导致很高磁盘IO等待。
RocketMQ中写虽然是顺序写,但是读却变成了随机读。(消费者)消息消费时将首先读取ConsumeQueue,然后再读Commit Log。这样在最坏的情况下,这个过程会带来一定的成本。
因为要保证Commit Log 与 Consume Queue完全的一致,这会给编程带来额外的复杂性。
设计动机:
1、随机读取。尽可能多地读取以增加页面缓存命中率,并减少读取IO操作。所以大内存还是比较可取的。如果累积了大量的消息,读取性能会严重下降吗?答案是否定的,原因如下:
即使消息的大小只有1KB,系统也会提前读取更多的数据,参考pagecache prefetch。这意味着,对于后续数据读取,将执行对主内存的访问,而不是缓慢的磁盘IO读取。
从磁盘随机访问确认。如果在SSD的情况下将I/O调度程序设置为NOOP,则读取QPS将大大加快,因此比其他电梯调度程序算法快得多。
2、由于ConsumeQueue只存储固定大小的元数据,主要用于记录消费进度,因此支持随机读取。利用页面缓存预取,访问ConsumeQueue的速度与访问主内存的速度一样快,即使它是在大量消息累积的情况下。因此,Consumeue不会对读取性能带来明显的惩罚。
3、CommitLog几乎存储所有信息,包括消息数据。与关系数据库的重放日志类似,只要存在提交日志,就可以完全恢复使用队列、消息键索引和所有其他必需的数据。
RocketMQ官网上还附了一个Rocketmq与activemq与kafka对比的表格,感兴趣的可以看一下。需要额外说的一点是,时间早一些的资料还在说Kafka不支持事务,但Kafka大概在0.11版本之后开始支持事务了:https://archive.apache.org/dist/kafka/0.11.0.0/RELEASE_NOTES.html,Kafka最近版本迭代得也很快,截至本文今日,已经到2.3.0版本了,增加了很多特性和功能。