pxc与haproxy参数详解
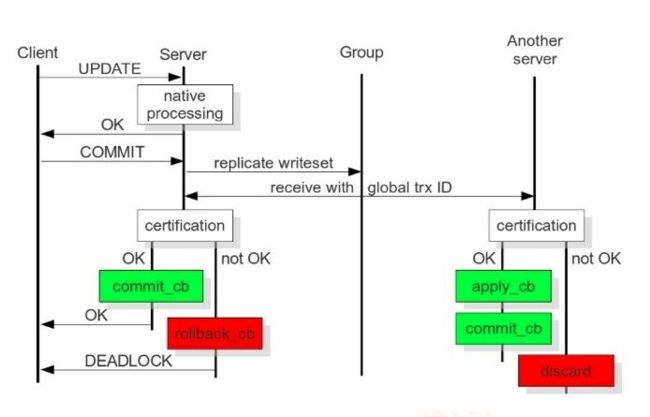
用户发起Commit,在收到Ok之前
集群每次发起一个动作,都会有一个唯一的编号
PXC独有的Global Trx Id
动作发起者: commit_cb
其它节点多了一个动作: apply_cb
上面的这些动作,是通过那个端号交互的?
4567
4568端口 IST 只是在节点下线,重启加入那一个时间有用
4444 只会在新节点加入进来时起作用
pxc结构里面
如果主节点写入过大
apply_cb 时间会不会跟不上
wsrep_slave_threads参数 解决apply_cb跟不上问题 配置成和CPU的个数相等或是1.5倍
当前节点commit_cb 后就可以返回了
推过去之后,验证通过就行了可以返回客户端了
cb==commit block 提交数据块
SST和IST
State Snapshot Transfer(SST) 全量传输
Incremental state Transfer(IST)增量传输
每个节点都有一份独立的数据
我们通过SST和IST说一下PXC的启动关闭流程
当我们启动第一个节点, bootstrap-pxc
当前集群没有其它成员,你就是老大了。
在第一个节点上可以把帐号初始化, 基本初始化,都搞定了。
初始化的时间,随便那个节点都可以。
其它节点再起来就是要加入进来的。 joining node
wsrep_cluster_address = gcomm://xxxx,,xxxx,xxx
你是新成员,你没有ID
第一个节点 把自已备份一下(snapshot) 传给加入的新节点: SST
socat.x86_64
perl-IO_Socket
nc
另一个节点是死的还是活的?
这时两个节点会进行一个投票
当第三个节点要加入的时间
wsrep_cluster_address = gcomm://xxxx,,xxxx,xxx
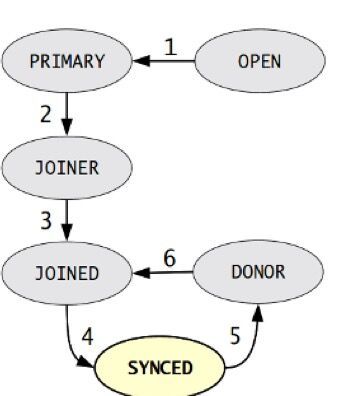
给贡献数据者
Donor
新启动的节点-> open ->primary
4567 端口沟通
joiner 我是新加入的
joined
需要有一个人能给他提供一份全量的数据
SST 发生的者的身上就是donor
donor 需要发起innobackupex
传输SST有几种方法:
1. xtrabackup
2. mysqldump mysql库也会传输
3. rsync 对innodb整个库进行锁定来拷贝,保证一致性
如果node3 需要停一下机
reboot , 加点内存,换个硬盘的
node3 希望说能不能把增量传给我
IST
Galera 2.X之前只能传全量
node3能停多长时间,可以传IST
gcache.size
wsrep_provider_options 默认128M
wsrep_provider_options="gcache.size=1G"
gid : 1000
1200 > gcache.size .id
gralea.cache
gcache.size到底分配多大合适呢
1个小时
可以算一个小时的binlog量大概多大
一般预留2-3小时,gcache.size大小2-4G
假设我们三个节点都关闭了,会发生什么呢
发现一个可怕的事情
全部传SST
没有做到最后关闭的节点,最先启动
建议滚动关闭
1. node1 先闭 修复完毕
加回来了
2. 再关node2 ,修复完毕
加回来了
3. 再关node3 ,修复完毕
加回来了
原则要保持Group里最少一个成员活着
滚动升级,先升级集群里的一个节点,再下一个节点再下一个节点
Gcache 数据没了。
数据库关闭之后,会保存一个last Txid
node1 1000
node2 1001
node3 1002
node1 是整个集群的老大
其它节点加进来发现数据不一致,以老大为准
会有丢数据风险
所有节点全关闭了
第一个用bootstrap-pxc启动的节点,他就为自已是老大了
第二节点加来了,还在老大的关系吗
兄弟两个是平起平座的
面临一个丢数据问题
mysqld —wsrep_recover —bootstrap-pxc 使用mysqld —wsrep_recover参数启动mysqld
—wsrep_recover
When server is started with this variable, it will parse Global Transaction ID (GTID) from log, and if the GTID is found, assign it as initial position for actual server start. This option is used to recover GTID.
[mysqld_safe]
wsrep_recover=1
wsrep_recover=on
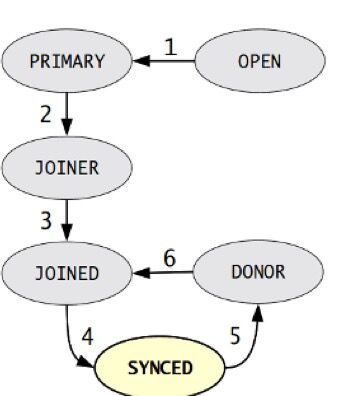
node3 1002
node3 bootstrap-pxc
gcache 最小的GTID是多少呢
1002
node2加入 : 1001
SST
node1加入 一样的传输 SST
怎么避免gcache丢失这件事情呢
1. 所有的节点中最少有一个在线,进行滚动重启
2. 利用主从的概念,把一个从节点转化成PXC里的节点
PXC集群的脑裂问题
输入任何命令都显示unkown command
推荐是三个节点
假设变成了两个节点
突然出现了两集群之间连不通了
模拟
iptables Start 4567端口连不通了。
kill -9 mysqld
忽略脑裂的命令
SET GLOBAL wsrep_provider_options="pc.ignore_sb=true";
PXC使用中的特点 和注意事项
PXC里任何节点都可以读写
他的ID增长顺序是什么样的
show global variables like "%auto%";
offset 是节点数
起始值有啥区别吗
1,2,3
node1, 1 node2: 2 node3: 3 offset: 3
1,4, 7,10 node1
5, 8, 11 … node2
6, 9, 12 …. node3
跟双主一样,通过控制步长和起始值来避免自增主键冲突
update tb set col3=col3-100 where id=10;
native 处理 node1,node2, node3 理论可以同时处理这个SQL
在PXC里同时更新到同一行记录是可能存在这个风险的
乐观并发控制
只锁本地的行记录,不锁别人的,不锁全局,本地处理完再发给别人,那么就有可能大家同时更新同一行记录
Error: 1213 SQLSTATE: 40001
考虑单节点写入
DDL操作
在某成员上做DDL操作,atler table 操作时间可以长一点。
会把整个集群锁着
ptcc做一个大表来模拟
metadata lock 搞定
在PXC结里,不可能不做表结构变更呀
解决:使用pt-online-schema-change
开发建个表告诉你数据不能复制
MyISAM引擎不能被复制,PXC只支持Innodb
mysql库全是MyISAM人家咋复制呢
DCL语句 Create user, drop user, grant ,revoke
pxc结构里面每个表必须有主键
如果没有主建,有可能会造成集群中每个节点的Data page里的数据不一样
node1 data page 6 rows
node2 data page : 7rows
select * from tb limit 100;
不支持表级的锁 lock /unlock tables
pxc里只能把slow log ,query log 放到File里,不能放到table里
不支持XA事务
三个节点。假设其中有一个节点 SSD,其它节点是HDD,整个集群的硬件配置要一样
木桶理论 :一个木桶打多少水以木桶里最短的那块木板决定,水太多会溢出
整个集群数最好为3,最多是8个
其中一个节点死掉了,还有2个节点
发现整个集群还能活
writeSet最大是多呢
wsrep_max_ws_rows
wsrep_max_ws_size 不要超过16KB
pxc的监控
clustercheck
wsrep_slave_threads:建议每个CORE启动4个复制线程,这个参数很大程度上受到I/O能力的影响,一般可以通过观察
wsrep_cert_deps_distance这个状态变量来获取当前最佳的线程数,
参数实际上表示单位时间平均多少个writesets能被执行掉
监控要点:
wsrep_flow_control_paused:这个变量标识当前节点落后于集群的程度,0.0表示没有落后,1.0为flow_control已经停止了,应该尽量保证这个变量值为0.0
如果落后厉害,则应该适当增加复制线程数wsrep_slave_threads
wsrep_cert_deps_distance:这个变量标识当前节点平均时间内并行执行的事务数,这个数据可以用来作为wsrep_slave_threads的参考
同时当并发量很高的时候,这个值也会很大
wsrep_flow_control_sent:表示flow_contro发出FC_PAUSE事件的次数,暂停的次数越多,表示接受到的请求频繁堵满SLAVE队列
,这种情况下不是队列长度不足,就是机器性能太差
wsrep_local_recv_queue_avg:这个表示本地节点平均的接收队列长度,如果不为0.0,则表示接收来的数据不能被及时应用
wsrep_local_send_q_avg:表示本地节点发送数据的队列长度,如果不为0.0,则表示向外发送数据的速度比较慢,有堆积。
高负载引起宕机风险的防治
1、参考建议的监控数据,严格控制
2、对应用的入口SQL详细审核,避免不正常的SQL运行
3、使用一些策略,例如IPTABLES 限制单位时间内的并发量,包个数,来避免宕机
节点故障-故障
1、任何的硬件故障、软件奔溃、网络接近异常,都将造成节点故障。判断故障节点的依据,是根据他是否能够连接
PC(Primary component),而PC是从当前集群中随机选择的,因此不能简单的根据服务器是否能够PING通等外部的方式来判断,需要根据各个节点的wsrep_local_state.
2、故障侦测节点每隔evs.inactive_check_period接收一次数据。
3、一旦节点发生故障,分不同的情况,如果无法进行IST,则需要做SST,代价非常巨大
4、Donor选择,有自动选择和手动指定两种方式,通过wsrep_sst_donor=DONOR_NAME来指定,不指定则在当前集群中随机选择。
5、当某个node选为Donor时,如果使用rsync或者DUMP,这个节点是不能提供客户端服务的,即使使用xtra这个点的性能和稳定性也会受到很大影响,基于这种情况,手动
设置一个,避免高负载的机器被用来做donor
节点故障--恢复
1、节点故障后获取GTID的方法
执行mysqld 加--wsrep-recover参数可获取GTID,如:mysqld --defaults-file=/etc/my.cnf --log_error=/dev/stdout --wsrep-recover
然后调用--wsrep_start_position=设置GTID,启动MYSQL
2、默认情况下,会自动从innodb redolog记录的checkpoint里获取GTID
HAPROXY

Queue
Cur: current queued requests //当前的队列请求数量
Max:max queued requests //最大的队列请求数量
Limit: //队列限制数量
Session rate(每秒的连接回话)列表:
scur: current sessions //每秒的当前回话的限制数量
smax: max sessions //每秒的新的最大的回话量
slim: sessions limit //每秒的新回话的限制数量
Sessions
Total: //总共回话量
Cur: //当前的回话
Max: //最大回话
Limit: //回话限制
Lbtot: total number of times a server was selected //选中一台服务器所用的总时间
Bytes
In: //网络的字节数输入总量
Out: //网络的字节数输出总量
Denied
Req: denied requests//拒绝请求量
Resp:denied responses //拒绝回应
Errors
Req:request errors //错误请求
Conn:connection errors //错误的连接
Resp: response errors (among which srv_abrt) ///错误的回应
Warnings
Retr: retries (warning) //重新尝试
Redis:redispatches (warning) //再次发送
Server列表:
Status:状态,包括up(后端机活动)和down(后端机挂掉)两种状态
LastChk: 持续检查后端服务器的时间
Wght: (weight) : 权重
Act: server is active (server), number of active servers (backend) //活动链接数量
Bck: server is backup (server), number of backup servers (backend) //backup:备份的服务器数量
Down: //后端服务器连接后都是down的数量
Downtime: downtime: total downtime (in seconds) //总的downtime 时间
Throttle: warm up status //设备变热状态