【Yolo系列】YOLO-NANO
链接:https://arxiv.org/abs/1910.01271
开源代码:https://github.com/liux0614/yolo_nano/issues/5
YOLO Nano 大小只有 4.0MB 左右,比 Tiny YOLOv2 和 Tiny YOLOv3 分别小了 15.1 倍和 8.3 倍,性能却有较为显著的提升。

目标检测在计算机视觉领域是一个活跃的研究分支,而深度学习已经成为这一领域最前沿也是最成功的解决方案。但是,在边缘和移动设备中广泛部署神经网络模型需要大量的计算算力和内存。因此,近来研究领域主要在解决适合以上设备的神经网络。
本文便是这些研究中的一个,研究者提出了名为 YOLO Nano 的网络。这一模型的大小在 4.0MB 左右,比 Tiny YOLOv2 和 Tiny YOLOv3 分别小了 15.1 倍和 8.3 倍。在计算上需要 4.57B 次推断运算,比后两个网络分别少了 34% 和 17%。
在性能表现上,在 VOC2007 数据集取得了 69.1% 的 mAP,准确率比后两者分别提升了 12 个点和 10.7 个点。研究者还在 Jetson AGX Xavier 嵌入式模块上,用不同的能源预算进行了测试,进一步说明 YOLO Nano 非常适合边缘设备与移动端。
从两阶段目标检测开始的故事
目标检测任务目前有两种通行的解决方案,一种是两阶段目标检测,另一种是单阶段的。对于两阶段目标检测,首先需要神经网络识别目标(如在目标上打上定位框),然后对识别出的目标进行分类。另一种则是单阶段,直接使用网络对目标进行检测。两阶段的好处在于实现容易,但下游的分类任务依赖上游识别定位任务的表现。而单阶段方法尽管不需要首先识别目标,但加大了端到端实现目标检测的难度。
一般而言,两阶段目标检测方法准确性高,但速度不快;而单阶段的检测器速度快,准确率并达不到最高。不过随着基于关键点的方法越来越流行,单阶段不仅快,同时效果也不错。
在单阶段目标检测方法中,围绕效率而生的 YOLO 神经网络是一个非常有趣的存在,我们最常调用的检测器也是它了。YOLO 可以在 GPU 实现实时目标检测,而且效果还挺好。
然而,这些网络架构对于很多边缘和移动场景而言太大了(例如,YOLOv3 网络的大小为 240MB),而且因为计算复杂度(YOLOv3 需要多达 65B 的运算量)过高,在这些设备上的推断速度会很慢。为了解决这些问题,Redmon 等提出了 Tiny YOLO 家族的网络架构,可以在一定程度上牺牲目标检测性能,换取模型规模的极大缩小。
本研究中,研究者通过人机协作设计策略(human-machine collaborative design)的方法进行构建。在构建的过程中,首先设计主要的网络原型,原型基于 YOLO 网络家族中的单阶段目标检测网络架构。然后,将原型和机器驱动的设计探索策略结合,创建一个紧凑的网络。这个网络是高度定制化的,在模块级别上有着宏架构(macro-architecture)和微架构(micro-architecture),可用于嵌入式目标检测任务。
YOLO Nano 设计思路
YOLO Nano 在架构设计的中经过了两个阶段:首先设计一个原型网络,形成网络的主要设计架构;然后,使用机器驱动的方法进行探索设计。
原型主体网络设计
首先是设计主要的网络原型,研究者创建了一个原始的架构(表示为ϕ),用于引导机器进行后续的探索设计。具体而言,研究者设计的网络基于 YOLO 家族中的单阶段目标检测架构。
YOLO 家族的网络架构最明显的特征是,它们不像基于「候选框」的网络那样需要构建一个 RPN,该网络会生成一系列定位目标的候选边界框,然后对生成的边界框进行分类。YOLO 家族的网络可以直接对输入的图像进行处理,然后生成输出结果。
这样一来,所有目标检测的预测都是将一张图像输入,直接得到输出,相比于 RPN 那种需要成百上千次的计算来得到最终结果而言省去了很多计算步骤,这使得 YOLO 家族的网络在运算上非常快,对于嵌入式目标检测任务而言也是最合适的。
机器驱动的探索设计
在这一阶段,研究者让机器使用最初的原型网络、数据和人类提出的设计的要求做为指引,然后机器驱动的探索设计会决定模块级别的宏架构和微架构,用于最终的 YOLO Nano 网络。
具体来说,机器驱动的探索设计是通过生成式整合来实现的。这一方法可以决定最优的网络宏架构和微架构,并符合人类的要求。
生成式整合的总体目标是学习生成式的机器,用于生成符合设计要求、限制等条件的深度神经网络。决定生成器 G 可以形式化为一个带约束的最优化问题,即在给定一系列种子 S 的情形下,生成网络 {N_s|s ∈ S} 以最大化全局性能函数 U。在最大化过程中需要满足指示函数 1_r(·),1r(·) 被定义来表示人类提出的需求和限制条件。
![]()
YOLO Nano 架构设计
了解了 YOLO Nano 的设计思路后,我们再看看它的架构是什么样的。如下图 1 所示,YOLO Nano 主要可以分为三部分,其中会有便捷连接连通不同抽象程度的特征图。
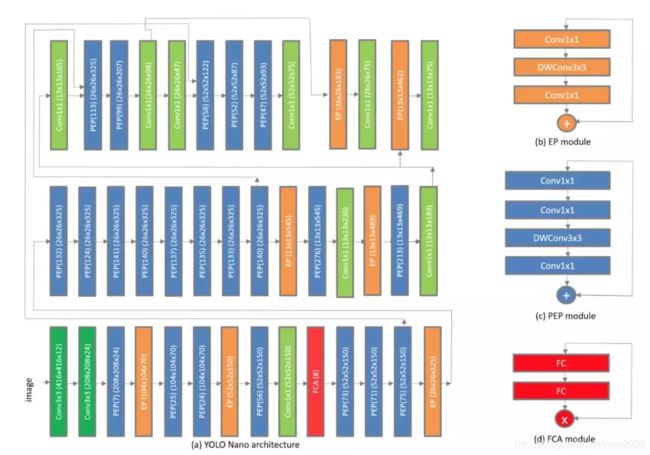
图 1:YOLO Nano 神经网络架构。注意其中 PEP(x) 表示残差 PEP 模块第一个映射层的 x 通道,FCA(x) 表示降维率为 x。
值得注意的是,YOLO Nano 有三种比较高效的模块,它们共同提升了整体建模的参数效率和运算效率。
残差映射-扩张-映射宏架构
YOLO Nano 网络架构第一个非常值得关注的模块就是残差映射-扩张—映射(PEP)宏架构(Macro-architecture),它和原来 YOLO 家族的模块有一些不同。
残差 PEP 宏架构主要由以下四部分组成:
一个 1*1 卷积的映射层,它将输入的特征图映射到较低维度的张量;
一个 1*1 卷积的扩张层,它会将特征图的通道再扩张到高一些的维度;
一个逐深度(depth-wise)的卷积层,它会通过不同滤波器对不同的扩张层输出通道执行空间卷积;
一个 1*1 卷积的映射层,它将前一层的输出通道映射到较低维度。
残差 PEP 宏架构的使用可以显著降低架构和计算上的复杂度,同时还能保证模型的表征能力。
全连接注意力宏架构
YOLO Nano 第二个值得注意的模块是,通过机器驱动设计的探索过程,研究者在神经网络引入了轻量级的全连接注意力(FCA)模块。FCA 宏架构由两个全连接层组成,它们可以学习通道之间的动态、非线性内部依赖关系,并通过通道级的乘法重新加权通道的重要性。
FCA 的使用有助于基于全局信息关注更加具有信息量的特征,因为它再校准了一遍动态特征。这可以更有效利用神经网络的能力,即在有限参数量下尽可能表达重要信息。因此,该模块可以在修剪模型架构、降低模型复杂度、增加模型表征力之间做更好的权衡。
宏架构和微架构的异质性
对于第三点,YOLO Nano 不仅在宏架构(PEP 模块、EP 模块、FCA 以及各个 3×3 和 1×1 卷积层的多样化组合)方面存在高度异质性,同样在独立特征表征模块和层级这些微架构之间也会存在异质性。
YOLO Nano 架构具有高度异质性的优势在于,它可以使网络架构的每个模块都经过特定的设计,从而在模型架构、计算复杂度和表征能力之间实现更优的权衡。YOLO Nano 这种架构多样性还展示了机器驱动设计探索策略和生成式组合一样灵活,因为人类设计者或其它设计探索方法无法在如此细粒度的层级上自定义架构。
实验效果
为了研究 YOLO Nano 在嵌入式目标检测上的性能,研究者在 PASCAL VOC 数据集上检测了模型大小、目标检测准确率、计算成本三大指标。为了体现对比,流行的 Tiny YOLOv2 和 Tiny YOLOv3 网络会作为基线模型。
如下表 1 展示了 YOLO Nano 、Tiny YOLOv2 和 Tiny YOLOv3 的模型大小与准确率。
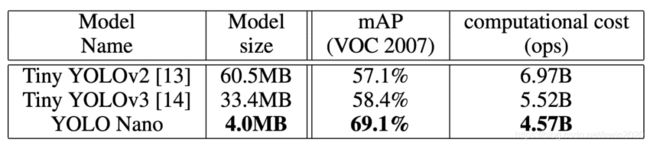
表 1:紧凑网络在 VOC 2007 测试集上的目标检测准确率结果,输入图像大小为 416*416,最优结果用加粗展示。
最后,为了探索 YOLO Nano 在现实世界中的性能,尤其是在边缘设备中的表现,研究者在 Jetson AGX Xavier 嵌入式模块测试了 YOLO Nano 的推断速度与能源效率。在 15W 和 30W 能源预算下,YOLO Nano 分别能实现∼26.9 FPS 和 ∼48.2 的推断速度。
这些实验都表明这篇论文提出来的 YOLO Nano 网络在准确率、模型大小和计算复杂度上提供了非常好的权衡,这种优势主要是通过人机协作的设计策略获得的,而且 YOLO Nano 在这种优势下也非常适合边缘和移动设备。
参考:
https://mp.weixin.qq.com/s/I-pBXgxG_nvWXnKTs78j8w