Go语言GMP模型
前言
- 线程的代价
- Golang协程模型概念-GMP
- 代码结构GMP
帝国时代
线程的代价
使用过C++/Java的同学应该都知道在做服务端开发的时候,对于多线程的使用,繁琐程度,以及对于多线程情况下异常情况的分析,是何等头疼,如果线上流量过大,对于这种多线程的操作更是得慎重,当然对于机器资源的消耗也是随之增加的,其实对于程序员来说最主要就是简单,高效~
- 空间大小:一般情况下一个thread的创建大小默认占用栈空间1M,而goroutine默认则是2kb
- 切换开销:thread的切换是需要通过用户态达到内核态,会设计到上下文的切换开销,对应资源的耗费会很大
- 线程通信:常见的线程通信有三种方式(C++),使用起来相对比较复杂,最棘手的问题就是共享内存,一般会使用锁,使用到锁,就会引申各种锁的问题,比如死锁。
- 资源回收:创建线程相对简单,回收线程资源会麻烦很多,常见有detached和join俩种方式,对于无法大量创建线程的时候,会考虑多路复用方式,这样的麻烦就是另个层次了。
线程并不是不好, 设计理念也并没有出问题. 只是在Go语言中我们针对并发的需求, 并没有这么庞大且全面, 我们也许只是并发的去发一个request, 也许只是并行的计算个什么东西, 很多时候并不是一些很难的东西, 我们也不需要去内核态中切换, 也不需要进程掩码. 在Go语言中我们希望它写起来很简单, 不要复杂, 很小, 我能在我的机器上创建一大堆出来最好, 也别搞多路复用.
Golang协程模型概念-GMP
- G:G是Goroutine的缩写,在这里就是Goroutine的控制结构,是对Goroutine的抽象。其中包括执行的函数指令及参数;G保存的任务对象;线程上下文切换,现场保护和现场恢复需要的寄存器(SP、IP)等信息。在 Go 语言中使用 runtime.g 结构表示。
// Go1.11版本默认stack大小为2KB
_StackMin = 2048
// 创建一个g对象,然后放到g队列
// 等待被执行
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
_g_ := getg()
_g_.m.locks++
siz := narg
siz = (siz + 7) &^ 7
_p_ := _g_.m.p.ptr()
newg := gfget(_p_)
if newg == nil {
// 初始化g stack大小
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg)
}
// 以下省略}
- M:表示操作系统线程也可以成为内核线程,由操作系统调度以及管理,调度器最多可以创建 10000 个线程,在 Go 语言中使用 runtime.m 结构表示。
- P:逻辑处理器,但不代表真正的CPU的数量,真正决定并发程度的是P,初始化的时候一般会去读取GOMAXPROCS对应的值,如果没有显示设置,则会读取默认值,在Go1.5之后GOMAXPROCS被默认设置可用的核数,而之前则默认为1,在 Go 语言中使用 runtime.p 结构表示。
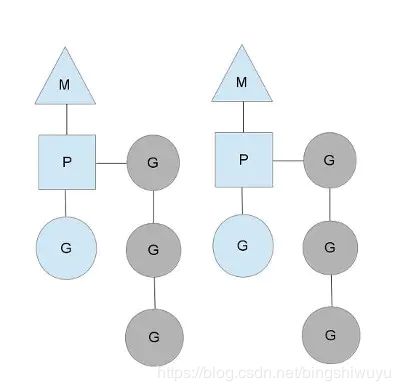
两个线程(M),每一个都持有自己的局部调度器§, 运行着一个G(蓝色). 同时还有一个等待运行的本地G队列(灰色). 下面换一张更详细的图, 说明白GMP三者的关系:
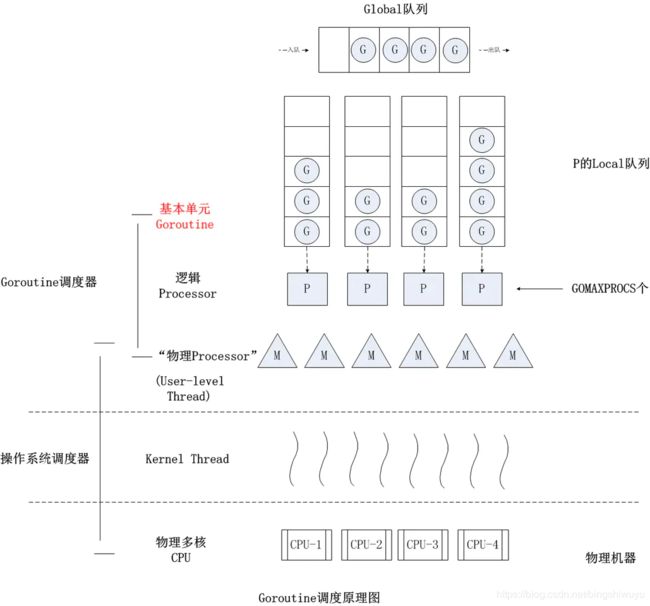
调度过程如下
- 全局队列:存放等待执行的G
- P的本地队列:当创建一个新的G之后优先加入本地队列,如果本地队列满了,会将本地队列的一般G移动到全局队列里面,本地队列保存G数量默认不超过256个
- P的列表:在初始化的时候根据GOMAXPROCS来设置
- M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队列,或从其他 P 的本地队列偷一半放到自己 P 的本地队列。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
Goroutine 调度器P和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行
特殊的 M0 和 G0
M0:是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
G0: 是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
调度过程
首先创建一个G对象,G对象保存到P本地队列或者是全局队列。P此时去唤醒一个M。P继续执行它的执行序。M寻找是否有空闲的P,如果有则将该G对象移动到它本身。接下来M执行一个调度循环(调用G对象->执行->清理线程→继续找新的Goroutine执行)。
M执行过程中,随时会发生上下文切换。当发生上线文切换时,需要对执行现场进行保护,以便下次被调度执行时进行现场恢复。Go调度器M的栈保存在G对象上,只需要将M所需要的寄存器(SP、PC等)保存到G对象上就可以实现现场保护。当这些寄存器数据被保护起来,就随时可以做上下文切换了,在中断之前把现场保存起来。如果此时G任务还没有执行完,M可以将任务重新丢到P的任务队列,等待下一次被调度执行。当再次被调度执行时,M通过访问G的vdsoSP、vdsoPC寄存器进行现场恢复(从上次中断位置继续执行)。
代码结构GMP
G: 代表一个goroutine对象,每次go调用的时候,都会创建一个G对象,它包括栈、指令指针以及对于调用goroutines很重要的其它信息,比如阻塞它的任何channel,其主要数据结构:
type g struct {
stack stack // 描述了真实的栈内存,包括上下界
m *m // 当前的m
sched gobuf // goroutine切换时,用于保存g的上下文
param unsafe.Pointer // 用于传递参数,睡眠时其他goroutine可以设置param,唤醒时该goroutine可以获取
atomicstatus uint32
stackLock uint32
goid int64 // goroutine的ID
waitsince int64 // g被阻塞的大体时间
lockedm *m // G被锁定只在这个m上运行
}
其中最主要的当然是sched了,保存了goroutine的上下文。goroutine切换的时候不同于线程有OS来负责这部分数据,而是由一个gobuf对象来保存,这样能够更加轻量级,再来看看gobuf的结构:
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret sys.Uintreg
lr uintptr
bp uintptr // for GOEXPERIMENT=framepointer
}
其实就是保存了当前的栈指针,计数器,当然还有g自身,这里记录自身g的指针是为了能快速的访问到goroutine中的信息。
M:代表一个线程,每次创建一个M的时候,都会有一个底层线程创建;所有的G任务,最终还是在M上执行,其主要数据结构:
type m struct {
g0 *g // 带有调度栈的goroutine
gsignal *g // 处理信号的goroutine
tls [6]uintptr // thread-local storage
mstartfn func()
curg *g // 当前运行的goroutine
caughtsig guintptr
p puintptr // 关联p和执行的go代码
nextp puintptr
id int32
mallocing int32 // 状态
spinning bool // m是否out of work
blocked bool // m是否被阻塞
inwb bool // m是否在执行写屏蔽
printlock int8
incgo bool // m在执行cgo吗
fastrand uint32
ncgocall uint64 // cgo调用的总数
ncgo int32 // 当前cgo调用的数目
park note
alllink *m // 用于链接allm
schedlink muintptr
mcache *mcache // 当前m的内存缓存
lockedg *g // 锁定g在当前m上执行,而不会切换到其他m
createstack [32]uintptr // thread创建的栈
}
结构体M中有两个G是需要关注一下的,一个是curg,代表结构体M当前绑定的结构体G。另一个是g0,是带有调度栈的goroutine,这是一个比较特殊的goroutine。普通的goroutine的栈是在堆上分配的可增长的栈,而g0的栈是M对应的线程的栈。所有调度相关的代码,会先切换到该goroutine的栈中再执行。也就是说线程的栈也是用的g实现,而不是使用的OS的。
P:代表一个处理器,每一个运行的M都必须绑定一个P,就像线程必须在么一个CPU核上执行一样,由P来调度G在M上的运行,P的个数就是GOMAXPROCS(最大256),启动时固定的,一般不修改;M的个数和P的个数不一定一样多(会有休眠的M或者不需要太多的M)(最大10000);每一个P保存着本地G任务队列,也有一个全局G任务队列。P的数据结构:
type p struct {
lock mutex
id int32
status uint32 // 状态,可以为pidle/prunning/...
link puintptr
schedtick uint32 // 每调度一次加1
syscalltick uint32 // 每一次系统调用加1
sysmontick sysmontick
m muintptr // 回链到关联的m
mcache *mcache
racectx uintptr
goidcache uint64 // goroutine的ID的缓存
goidcacheend uint64
// 可运行的goroutine的队列
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr // 下一个运行的g
sudogcache []*sudog
sudogbuf [128]*sudog
palloc persistentAlloc // per-P to avoid mutex
pad [sys.CacheLineSize]byte
其中P的状态有Pidle, Prunning, Psyscall, Pgcstop, Pdead;在其内部队列runqhead里面有可运行的goroutine,P优先从内部获取执行的g,这样能够提高效率。
除此之外,还有一个数据结构需要在这里提及,就是schedt,可以看做是一个全局的调度者:
type schedt struct {
goidgen uint64
lastpoll uint64
lock mutex
midle muintptr // idle状态的m
nmidle int32 // idle状态的m个数
nmidlelocked int32 // lockde状态的m个数
mcount int32 // 创建的m的总数
maxmcount int32 // m允许的最大个数
ngsys uint32 // 系统中goroutine的数目,会自动更新
pidle puintptr // idle的p
npidle uint32
nmspinning uint32
// 全局的可运行的g队列
runqhead guintptr
runqtail guintptr
runqsize int32
// dead的G的全局缓存
gflock mutex
gfreeStack *g
gfreeNoStack *g
ngfree int32
// sudog的缓存中心
sudoglock mutex
sudogcache *sudog
}
大多数需要的信息都已放在了结构体M、G和P中,schedt结构体只是一个壳。可以看到,其中有M的idle队列,P的idle队列,以及一个全局的就绪的G队列。schedt结构体中的Lock是非常必须的,如果M或P等做一些非局部的操作,它们一般需要先锁住调度器。