mac安装Hadoop3.2.1教程(超详细)
由于课程需要和工具限制,需要在mac上安装Hadoop,参考了网上的教程,总结了用terminal安装Hadoop3.2.1以及运行第一个Wordcount程序的过程。这里默认mac的terminal已经安装了homebrew软件管理工具、JDK环境,如果没安装homebrew、JDK环境的小伙伴请自行搜索mac终端安装homebrew、JDK教程。下面是安装Hadoop的具体流程,分三步:
一、设置ssh免密码登录
因为Hadoop是分布式平台,需要多个机器之间协作,设置ssh免密码登录可以减少每次登陆主机输入密码的繁琐流程。
1)在mac的系统偏好设置-->共享中打开远程登录:

2)在terminal中输入 ssh-keygen -t rsa -P ,生成rsa公钥,接下来一路按回车键或者y就行了:
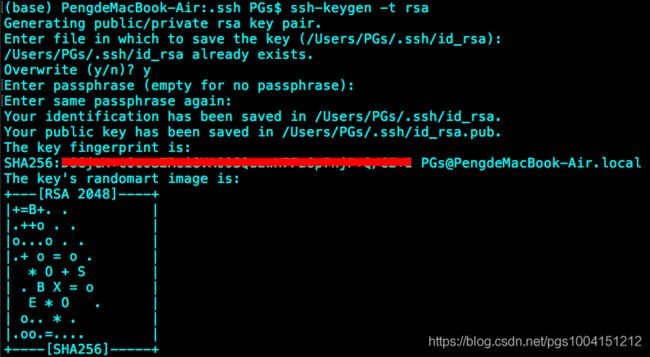
注释(大佬可以直接跳过):RSA和MD5是常用的加密算法,生成的RSA公钥和私钥放在了~/.ssh路径下面,id_rsa是私钥文件,id_rsa.pub是公钥文件,用cat命令可以查看文件里面的具体内容。

3)在terminal中输入 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ,将公钥的内容写入到authorized_keys文件中。
4)在terminal中输入 ssh localhost ,不需要密码也能登录,说明设置成功。

二、用brew下载Hadoop,并进行配置
1)在terminal中输入brew install hadoop,下载Hadoop:
注意:由于用homebrew下载软件时,它会默认先更新自己的软件包,而有时候更新会非常慢,甚至更换镜像源也不行。这时可以按一次组合键command+c先中断这次更新,然后开始直接下载Hadoop。具体参见https://learnku.com/articles/18908这篇文章。下载完成后,出现以下提示,说明安装成功:
/usr/local/Cellar/hadoop/3.2.1: 22,397 files, 815.7MB, built in 4 minutes 51 seconds
2)修改Hadoop配置文件之一:
首先,在terminal中输入vim /usr/local/Cellar/hadoop/3.2.1/libexec/etc/hadoop/core-site.xml ,用vim编辑器编辑core-site.xml配置文件的内容,也指明了配置文件的存放路径。这里我用的是sublime编辑器:
![]()
然后在文件的
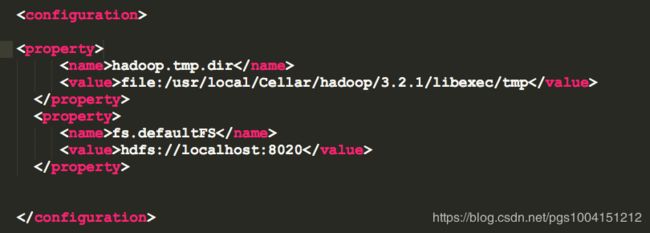
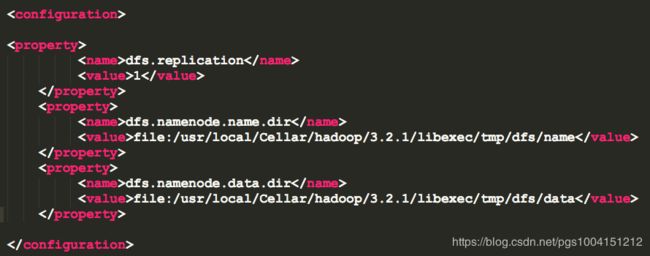
3)修改Hadoop配置文件之二:
在terminal中输入vim /usr/local/Cellar/hadoop/3.2.1/libexec/etc/hadoop/hdfs-site.xml,用vim编辑器打开hdfs-site.xml配置文件的内容。然后在文件的
4)配置Hadoop环境变量:
在terminal输入vi ~/.bash_profile ,对环境变量文件进行编辑,添加以下信息:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_131.jdk/Contents/Home
export CLASSPAHT=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/Cellar/hadoop/3.2.1/libexec
export HADOOP_COMMON_HOME=$HADOOP_HOME
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:/usr/local/Cellar/scala/bin

注释(大佬请跳过):环境变量的作用就类似于定义一个特殊的变量,用这个变量来代指某个路径,这样在运行软件或者输入命令行命令时,机器知道某些命令应该从哪里开始执行。比如定义JAVA_HOME环境变量,在terminal下输入/usr/libexec/java_home ,可以查看Java的安装路径如下:
![]()
然后把JAVA_HOME的环境变量定义为上述路径,用export语句导入。这样在执行javac、java等命令时,机器就知道从哪个路径开始执行了。HADOOP_HOME环境变量定义的作用也类似,不同机器、不同安装路径,定义的环境变量内容也可能不同。关于环境变量添加和修改的格式参考https://blog.csdn.net/pgs1004151212/article/details/104348015。
5)在terminal输入source ~/.bash_profile ,使刚刚修改的环境变量生效:
![]()
到这里,Hadoop的安装和配置就完成啦!下面是运行第一个Hadoop程序的过程。
三、运行第一个Hadoop程序
1)初始化(仅初次安装时需要)。在terminal上输入 cd /usr/local/Cellar/hadoop/3.2.1/bin ,
回车后输入 ./hdfs namenode -format
2)启动。在terminal上输入 cd /usr/local/Cellar/hadoop/3.2.1/sbin
回车后输入 ./start-dfs.sh

3)查看是否启动。在terminal上输入 jps (JavaVirtualMachineProcessStatus,查看运行的Java进程),如下所示:

4)查看namenode。在浏览器上输入http://localhost:9870/dfshealth.html#tab-overview

5)修改yarn配置文件。修改配置文件/usr/local/Cellar/hadoop/3.2.1/libexec/etc/hadoop/mapred-site.xml,添加以下内容:

6)修改配置文件 /usr/local/Cellar/hadoop/3.2.1/libexec/etc/hadoop/yarn-site.xml ,添加以下内容:

7)启动yarn。在terminal上输入cd /usr/local/Cellar/hadoop/3.2.1/sbin (如果已经在这个目录下就不用转换了)
回车后输入./start-yarn.sh

启动成功后可以在浏览器输入 http://localhost:8088/cluster ,出现如下界面:

8)运行Hadoop自带的Wordcount程序,统计字符出现的个数。首先在terminal输入 hadoop fs -mkdir /input ,这是在hadoop文件系统的根目录下新建一个input文件夹。类似的,也可以新建其他的文件或文件夹。
查看hadoop下面的所有目录,在terminal输入 hadoop fs -ls /

然后,在terminal上输入 hadoop jar /usr/local/Cellar/hadoop/3.2.1/libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input /output 。最后三个参数的意思是:wordcount是测试用例的名称,/input表示输入文件的目录,/output表示输出文件的目录。运行结果如下:

(注意⚠️:输出文件必须是一个不存在的文件,如果指定一个已有目录作为hadoop作业输出的话,作业将无法运行。如果想让hadoop将输出存储到一个目录,它必须是不存在的目录,应该是hadoop的一种安全机制,防止hadoop重写有用的文件)
最后,查看程序输出结果及存放位置。在terminal上输入 hadoop fs -ls /output ,可以看到:

结果就存放在part-r-00000文件中,在terminal上输入 hadoop fs -cat /output/part-r-00000 ,结果就出来啦:
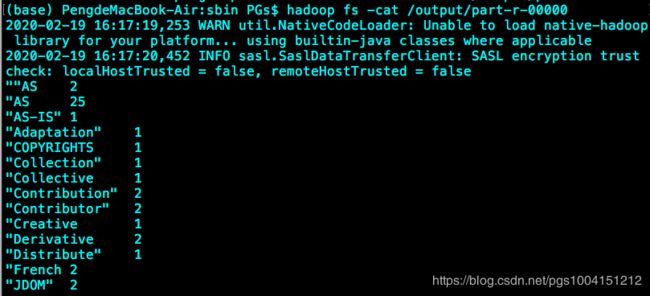
Congratulation!第一个Hadoop程序就完成啦。