爬取拉勾网招聘信息
标题爬取拉勾网招聘信息
本内容仅作个人研究使用,不作为商业用途
本人学识浅薄,写的不好还请见谅
#导入库以及创建表格
import requests
import xlwt
#url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'#全国招聘
#urls='https://www.lagou.com/jobs/list_python?labelWords=sug&fromSearch=true&suginput=py'
#创建表格
w=xlwt.Workbook(encoding='utf-8')
ws=w.add_sheet('python',cell_overwrite_ok=True)
ws.write(0,0,'序号')
ws.write(0,1,'公司')
ws.write(0,2,'城市')
ws.write(0,3,'职位')
ws.write(0,4,'薪资')
ws.write(0,5,'学历要求')
ws.write(0,6,'工作经验')
ws.write(0,7,'职位优点')
通过解析网页可以知道为动态加载

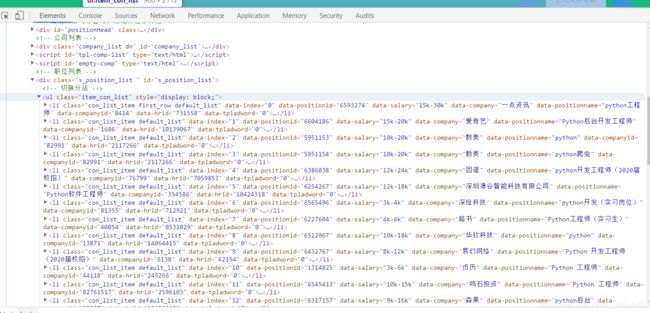 解析网页得到了数据的动态地址
解析网页得到了数据的动态地址


由此可以看到我们需要的内容都在这里
代码为:
urls='https://www.lagou.com/jobs/list_python?isSchoolJob=1'#校园招聘
url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=1'
#实验headers包含user-agent后发现不能访问,出现访问频繁稍后再试等字样所以把headers全部内容复制
#headers = {
# 'Accept': 'application/json,text/javascript,*/*;q=0.01',
# 'Accept-Encoding': 'gzip,deflate,br',
# 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
# 'Cache-Control': 'max-age=0',
# 'Connection': 'keep-alive',
# 'Content-Length': '25',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
# 'Cookie': 'JSESSIONID=ABAAABAAAGGABCB1B008A4CE726755A356D26C62CDF8682; _ga=GA1.2.2125033291.1529067719; user_trace_token=20180615210155-47c46dd3-709c-11e8-9642-5254005c3644; LGSID=20180615214357-26f030b8-70a2-11e8-9643-5254005c3644; LGRID=20180615214357-26f0325f-70a2-11e8-9643-5254005c3644; LGUID=20180615210155-47c4714d-709c-11e8-9642-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=search_code; SEARCH_ID=e03b7df96b544c96ab10e0f5fa878e08; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Dtlz5eF6VtDDmGVyeuPECp4PAP6-D80st6n12koGsSsm%26ck%3D5605.4.94.275.120.494.111.442%26shh%3Dwww.baidu.com%26sht%3Dmonline_dg%26wd%3D%26eqid%3Da25faec40002af21000000025b23b8bc; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F',
# 'Host': 'www.lagou.com',
# 'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=sug&fromSearch=true&suginput=p',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0',
# 'X-Anit-Forge-Code': '0',
# 'X-Anit-Forge-Token': 'None',
# 'X-Requested-With': 'XMLHttpRequest'
#}
#全部内容复制后发现还是显示访问频繁(拉钩的反扒机制)通过一次次实验得出包含下面三个参数即可访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=sug&fromSearch=true&suginput=p',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
#data为控制页数以及职位的参数
data = {
'first': 'false',
'kd': 'Python',
'pn': 1
}
#使用cookie模拟
cookie='复制cookie信息'
cookies={}
for line in cookie.split(';'):
key,value = line.split('=',1)
cookies[key]=value
#为了有效可以使用geturl来获取cookies
s = requests.Session()
# 获取搜索页的cookies
s.get(urls, headers=headers, timeout=2)
# 为此次获取的cookies
cookie = s.cookies
# 获取此次文本(因为url访问方式为post所以使用post访问)
result = s.post(url, data=data, headers=headers, cookies=cookie, timeout=4)
#得到html内容
#info = result.text
#通过分析发现,转换成json比html更有层次感
info = result.json()
得到了info后,我们需要的数据也就有了,下面就是保存了
#取出需要的内容
info =info['content']['positionResult']['result']
row=1
for n in range(0, len(info)):
ws.write(row,0,row)
ws.write(row,1,info[n]['companyFullName'])
ws.write(row,2,info[n]['city'])
ws.write(row,3,info[n]['positionName'])
ws.write(row,4,info[n]['salary'])
ws.write(row,5,info[n]['education'])
ws.write(row,6,info[n]['workYear'])
ws.write(row,7,info[n]['positionAdvantage'])
row+=1
w.save('拉钩.xls')
print('已完成')
下面给出整合后的完整代码:
import requests
import xlwt
def base(jos, page):
urls='https://www.lagou.com/jobs/list_python?isSchoolJob=1'
url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=sug&fromSearch=true&suginput=p',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
url_info(url,urls,headers,jos,page)
return
def url_info(url,urls,headers,jos,page):
info_list=[]
for i in range(1,page+1):
data = {
'first': 'false',
'kd': jos,
'pn': i
}
s=requests.session()
s.get(urls,headers=headers,timeout=2)
cookie=s.cookies
result=s.post(url,data=data,headers=headers,cookies=cookie,timeout=4)
info=result.json()
info_list.append(info['content']['positionResult']['result'])
Download(info_list,jos)
def Download(infolist,jos):
w=xlwt.Workbook(encoding='utf-8')
ws=w.add_sheet(jos,cell_overwrite_ok=True)
ws.write(0,0,'序号')
ws.write(0,1,'公司')
ws.write(0,2,'城市')
ws.write(0,3,'职位')
ws.write(0,4,'薪资')
ws.write(0,5,'学历要求')
ws.write(0,6,'工作经验')
ws.write(0,7,'职位优点')
row=1
for info in infolist:
for n in range(0,len(info)):
ws.write(row,0,row)
ws.write(row,1,info[n]['companyFullName'])
ws.write(row,2,info[n]['city'])
ws.write(row,3,info[n]['positionName'])
ws.write(row,4,info[n]['salary'])
ws.write(row,5,info[n]['education'])
ws.write(row,6,info[n]['workYear'])
ws.write(row,7,info[n]['positionAdvantage'])
row+=1
w.save('拉勾网.xls')
print('已完成')
return row
if __name__ == '__main__':
position=input('请输入要查询的职位:')
pg=input('请输入要爬取的页数<=30:')
page=eval(pg)
base(position,page)