Feature Pyramid Networks
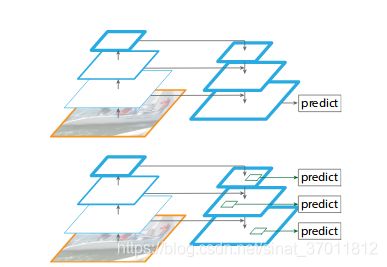
构建特征金字塔,利用一次网络前向传播计算不同大小的feature map,在不同的feature map 上做prediction
网络前向传播,feature map大小逐渐变小,特征从local到global变化。
到最顶层之后用一个1*1的conv进行降维之后,开始predict。
从上至下依次upsample并且连接之前从下到上提取的feature map,结合更多特征
'''FPN in PyTorch.
See the paper "Feature Pyramid Networks for Object Detection" for more details.
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
# This is a residual block
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class FPN(nn.Module):
def __init__(self, block, num_blocks):
super(FPN, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
# Bottom-up layers
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
# Top layer
self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
# Smooth layers
self.smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.latlayer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.latlayer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
print(strides)
layers = []
print(strides)
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
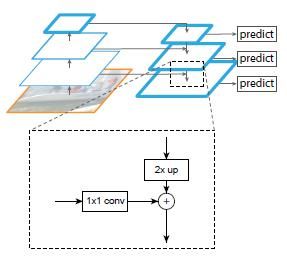
def _upsample_add(self, x, y):
'''Upsample and add two feature maps.
Args:
x: (Variable) top feature map to be upsampled.
y: (Variable) lateral feature map.
Returns:
(Variable) added feature map.
Note in PyTorch, when input size is odd, the upsampled feature map
with `F.upsample(..., scale_factor=2, mode='nearest')`
maybe not equal to the lateral feature map size.
e.g.
original input size: [N,_,15,15] ->
conv2d feature map size: [N,_,8,8] ->
upsampled feature map size: [N,_,16,16]
So we choose bilinear upsample which supports arbitrary output sizes.
'''
_,_,H,W = y.size()
return F.interpolate(x, size=(H,W), mode='bilinear', align_corners= False) + y
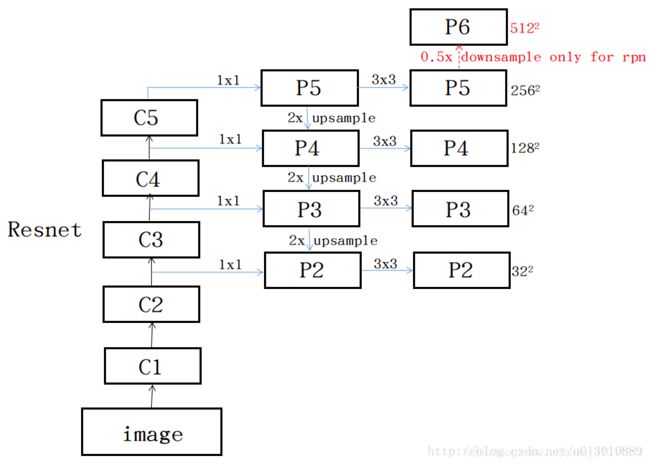
def forward(self, x):
# Bottom-up
c1 = F.relu(self.bn1(self.conv1(x)))
c1 = F.max_pool2d(c1, kernel_size=3, stride=2, padding=1)
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
# Top-down
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
# Smooth
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p5
def FPN101():
#return FPN(Bottleneck, [2,4,23,3])
return FPN(Bottleneck, [2,2,2,2])
def test():
net = FPN101()
fms = net(Variable(torch.randn(1,3,600,900)))
for fm in fms:
print(fm.size())
test()
lateral layers 就是横向连接的层
upsample_add 连接两个特征层
make_layer构造residual block
Reference
https://arxiv.org/pdf/1612.03144.pdf
https://blog.csdn.net/xiamentingtao/article/details/78598027
https://github.com/kuangliu/pytorch-fpn