2018全国高校大数据应用创新大赛(技能赛)

描述
- 训练阶段:组委会提供25000条数据作为训练数据,参赛队伍报名后可从大赛官网下载训练数据集,并进行算法设计、训练和优化。
- 预赛阶段:组委会提供10万条数据作为预赛数据集。参赛队伍使用自己的算法,对这10万条数据进行“优化等级”标注。本竞赛将以优化等级标注的准确率作为选手预赛的得分。
- 分赛区决赛和全国总决赛阶段。组委会提供100万条正式比赛数据,参赛队伍使用自己的算法,对这100万条数据进行“优化等级”标注。本竞赛将以优化等级标注的准确率作为选手决赛的技术得分,结合决赛答辩评出最终名次。
- 详情见 http://117.50.29.62/pc/competition_topic.jsp
环境
| 环境 | 版本 | Python模块 | 版本 |
|---|---|---|---|
| Ubuntu | 16.04 | tensorflow | 1.8 |
| Anaconda | 5.1 | numpy | |
| Python | 3.6 | pandas | |
| Jupyter lab | 0.31.5 | matplotlib |
数据预处理
- 标签列为数字特征,不做处理。
- 数据中特征列有花色,牌面等信息为字母标注,将其替换成数字特征,模型相对比较容易处理。比如C替换成1,D替换成2等。如下列代码所示:
NAMES = ['col'+str(e) for e in range(11)]
df_train = pd.read_csv('data/train.csv',names=NAMES,index_col=False)
huase_to_num = {'C':1,'D':2,'H':3,'S':4}
paimian_to_num = {'J':11,'Q':12,'K':13}
df_train=df_train.replace(huase_to_num).replace(paimian_to_num)
特征提取
- 前10列特阵列的数字特征
- 可以考虑使用交叉列输入神经网络
代码示例如下:
feature_columns = []
for col in NAMES[:-1]:
feature_columns.append(tf.feature_column.numeric_column(key=col))
feature_columns
模型选择
- 神经网络采用三层隐藏层,神经元个数分别是1536,768,384
- 优化函数采用
ProximalAdagradOptimizer - 学习率0.005
- L1正则化率0.001
- L2正则化率0.001
具体代码如下:
cls = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[1536,768,384],
n_classes=numClasses,
optimizer=tf.train.ProximalAdagradOptimizer(
learning_rate=0.005,
l1_regularization_strength=0.001,
l2_regularization_strength=0.001
))
模型训练与预测
对已有的数据进行2000次训练,准确率如下图,20分钟训练模型2000次准确率99.5%

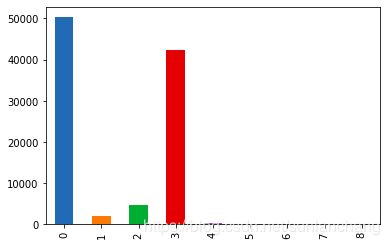
查看训练数据和预测数据分布
- 对数据进行预测并画出柱形图对比分布,如下图
- 大体可以看出分布是相同的

PyTorch 1.0 版本代码
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
NAMES = ['col'+str(e) for e in range(11)]
NAMES_TEST = ['col'+str(e) for e in range(10)]
df_train = pd.read_csv('data/train.csv',names=NAMES,index_col=False)
df_test = pd.read_csv('data/ftest.csv',names=NAMES_TEST,index_col=False)
suit_num = {'C':1,'D':2,'H':3,'S':4} #将花色转成数值
poker_num = {'J':11,'Q':12,'K':13} #将牌面转成数值
df_train=df_train.replace(suit_num).replace(poker_num)
df_test=df_test.replace(suit_num).replace(poker_num)
训练初始化
df_train=df_train.apply(pd.to_numeric)
for col in NAMES[:-1]:
df_train[col] = df_train[col]-1
data_x = df_train[df_train.columns[:-1]]
# data_y = df_train[df_train.columns[-1]]
data_y = pd.DataFrame(df_train['col10']).applymap(str)['col10']
assert data_x.shape[0]==data_y.shape[0]
预测初始化
df_test=df_test.apply(pd.to_numeric)
for col in NAMES_TEST:
df_test[col] = df_test[col]-1
x_test = df_test
构造数据集
import torch
from torch.utils.data import Dataset, DataLoader
class PokerDataset(Dataset):
def __init__(self, x_dataframe, y_dataframe, transform=None):
self.x_tensor = torch.tensor(x_dataframe.values.astype('float')).float()
self.y_tensor = torch.tensor(y_dataframe.values.astype('float')).long()
def __len__(self):
return len(self.x_tensor)
def __getitem__(self, idx):
one_sample_x = self.x_tensor[idx]
one_sample_y = self.y_tensor[idx]
# sample = {'one_sample_x': one_sample_x, 'one_sample_y': one_sample_y}
return one_sample_x, one_sample_y
设置超参数
# GPU加速
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper parameters
num_epochs = 5
num_classes = 10
batch_size = 100
learning_rate = 0.0001
dataset构造、dataloader构造
poker_dataset = PokerDataset(x_dataframe=data_x, y_dataframe=data_y)
poker_dataloader = DataLoader(poker_dataset, batch_size=batch_size,
shuffle=True)
# 测试数据集
it = iter(poker_dataset)
next(it)
定义模型
poker_dataset = PokerDataset(x_dataframe=data_x, y_dataframe=data_y)
poker_dataloader = DataLoader(poker_dataset, batch_size=batch_size,
shuffle=True)
# 测试数据集
it = iter(poker_dataset)
next(it)
定义误差函数和优化器
from torch import optim
critirion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
model = PokerNet()
# print(loss(model(xb), yb))
训练
import pdb
for epoch in range(20):
# running_loss = 0.0
for i, data in enumerate(poker_dataloader, 0):
# get the inputs
inputs, labels = data
# 将图模型梯度置0
optimizer.zero_grad()
# forward + backward + optimize
# pdb.set_trace()
outputs = net(inputs)
loss = critirion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
print(loss.item())
print('Finished Training')