transformer算法详解
一、背景
NLP作为AI的子领域,一直以来被认为比较难的学科。特征抽取一直以来都作为NLP的核心任务。概况来说在深度学习为基础的体系中,特征抽取经历了以下几个阶段:DNN->CNN->RNN->Transformer。自从2017年6月份《Attention is all you need》论文作为机器翻译算法提出后,transform已经逐步替代了以CNN和RNN为首的特征抽取,特别是2018年bert一战成名后,目前所有的主流方法几乎都是transformer系的变体。
二、架构
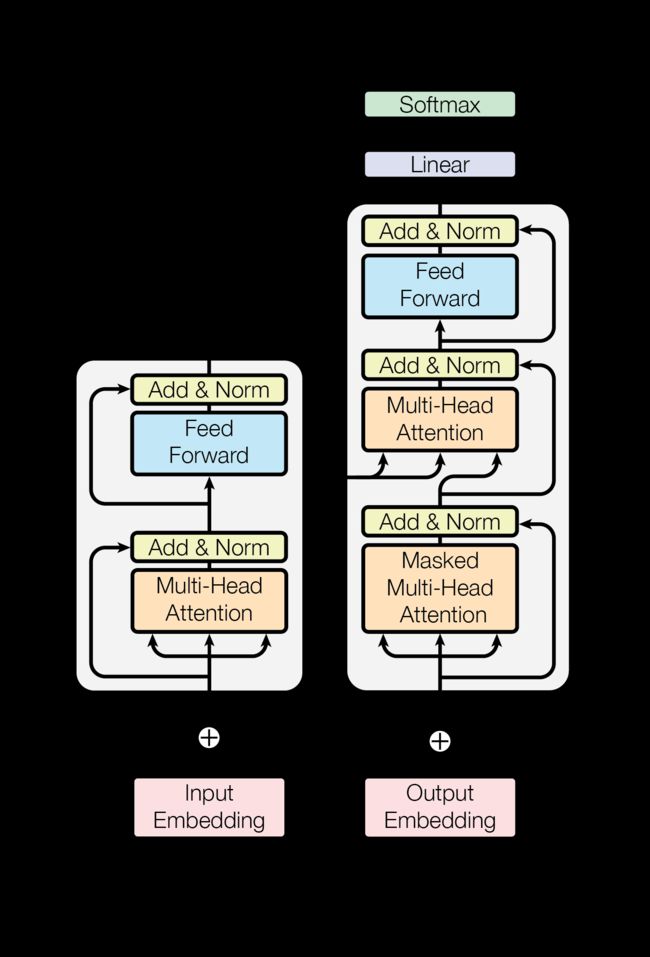
- 1.和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
- 2.我们可以将transformer看做黑盒,例如将 I love you ->黑盒->我爱你。
- 3.在张量层面的黑盒理解,比如batch为N,每句话word个数为L,每个word的的embedding长度为D,字典中单词个数为V。(N,L,D)->transformer-> (N1,L1,D1)。然后用 ( N 1 , L 1 , D 1 ) ∗ ( V , D ) T (N1,L1,D1)*(V,D)^T (N1,L1,D1)∗(V,D)T得到(N1,L1,V),最后通过softmax((N1,L1,V))得到在最后一维度V中,概率最大的字。
三、架构的理解
transformer可以分为两个模块Encode模块和Decode模块。Encode模块可以分为两个子模块,Decode模块可以分为三个子模块,其中第二和第三个和Encode的两个子模块相同。
1.Encode模块 *N
每个模型前面要加上 Input Embedding + Postional Embedding
- (1)Multi-Head Attention:多头注意力机制
add & norm - (2)Feed Forward:前馈网络
add & norm
2.Decode模块 *N
每个模型前面要加上 Input Embedding + Postional Embedding
- (1) Masked Multi-Head Attention:遮蔽多头注意力机制
add & norm - (2)Multi-Head Attention:多头注意力机制
add & norm - (3)Feed Forward:前馈网络
add & norm
四、Encode层
1. Input Embedding
根据输入input ,初始化词典的每个字的Embedding,可以按照正态分布或者其他的方式
2. Postional Embedding
位置信息可以用两种方式来定义:
1.归纳偏置和一些经验得出的函数
2.向Bert一样学习得到
transformer是用的第一种,原因可以参考:
https://www.zhihu.com/question/347678607/answer/864217252
3. Multi-Head Attention
这是创新的重点:
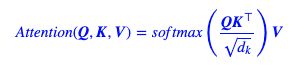
我们对这个式子做直观上的解释:
1.首先,Q、K、V都是(N,L,D)的张量,对于第第一维N主要是做并行计算的,我们暂且去掉,那么Q、K、V都是(L,D)的矩阵了。
2.那么 Q K T = ( L q , L k ) QK^T=(L_q,L_k) QKT=(Lq,Lk)的矩阵了,这样每个字就能看到其他字的意思了,就能知道这个字所在的前后语境了。
3.其中因子 √ d k √d_k √dk起到调节作用,使得内积不至于太大(太大的话softmax后就非0即1了,不够“soft”了)
4.通过softmax做归一化,权重调节,让当前词语知道前后此所占的权重,然后乘V
4. add & norm
1.add:这个是每个子模块都有的操作,意思是每个环节的特征变换之后都加上这个环节变换之前的值,目的是防止模型跑偏。
2.layer Normalization
对特征做标准化:减去均值/标准差
5. Feed Forward
加个前馈神经网络
三、Decode层
和Encoder相同的模型不在讲解了,直讲解不同 的模块
1、Output Embedding
注意,output输入的内容,输入的内容包含了两层含义:
1.输入label
2.输入特征
这里要注意,输入的output前面会加入 < s > <s>标志位。标志位只占一个字符
输入label容易理解,输入特征不好理解。我们以英文翻译为中文为例。
则input 输入为: I love you.
output输入为: < s > <s> 我 爱 你
2、Masked Multi-Head Attention
为什么要加入标志位 < s > <s>呢?我们在做翻译任务的时候,都是一句话东第一个字开始翻译,逐渐到最后一个字。在翻译第一个字我的时候是根据标志位 < s > <s>的输入开始的。
注意:
我们在做翻译任务的时候,并不是完全根据英文直接翻译成中文的。而是根据整个英文+已经翻译出来的中文来预测下一个要翻译的中文。
例如:
预测 “我”是根据: “I love you ” + "" 预测 “我”
预测 “爱”是根据: “I love you ” + "我" 预测 “爱”
预测 “你”是根据: “I love you ” + "我爱" 预测 “你”
- 结论:所以说我们预测中文的输入output也会输入特征。
- 原理:
如何实现这种方式呢,就通过 Masked Multi-Head Attention。
其实原理和Multi-Head Attention一样,只不过把要预测的部分masked掉。
如何masked
这个子模块的输入依然是Q、K、V,计算到:那么 Q K T = ( L q , L k ) QK^T=(L_q,L_k) QKT=(Lq,Lk)的矩阵的时候如下:
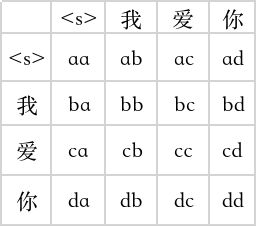
行:Q
列:V
我们的目标是让当前的字,不能看到后面的字的意思,所有要把后面的字masked掉。
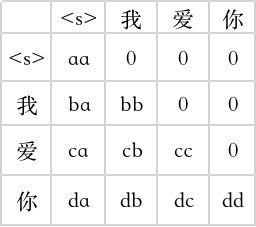
形成一个下三角矩阵。
这样在 Q K T = ( L q , L k ) QK^T=(L_q,L_k) QKT=(Lq,Lk)之后形成一个下三角矩阵,那么整个Attention就无法获取到后面的信息了。