python平行(3):【parallel python】与【sklearn joblib的parallel和delayed】性能对比
随机森林的并行写完了。大致采用了两种方法:
1)一种是 python并行(1)中提到的joblib的parallel和delayed方法(具体实现是直接使用sklearn.externals.joblib,因为sklearn优化得很好)
2)第二种是采用http://www.parallelpython.com/的SMP
两者编程都很简单,但效率相差还是挺大的,这里大概贴出三者的编程及时间对比。
首先结论是:parallel python 好于 sklearn joblib的parallel和delayed 好于 sequential的训练。
如果你发现parallel python时间还要多于sequential的训练,那就是实现的有问题,下面我会给出一种错误实现的方式。
首先sequential的训练:
trees=[]
start_time=time.time()
for i in range(n_more_estimator):
tree=MY_TreeClassifier(
criterion=self.criterion,
max_depth=self.max_depth,
min_leaf_split=self.min_leaf_split,
max_feature=self.max_feature,
bootstrap=self.bootstrap,
seed=self.seed,
n_jobs=self.n_jobs
)
tree=tree.fit(X, y)
trees.append(tree)
sequential_time=time.time() - start_time其次sklearn joblib的parallel和delayed 的训练:
from sklearn.externals.joblib import Parallel, delayed
trees_pp=[]
start_time=time.time()
for i in range(n_more_estimator):
tree=MY_TreeClassifier(
criterion=self.criterion,
max_depth=self.max_depth,
min_leaf_split=self.min_leaf_split,
max_feature=self.max_feature,
bootstrap=self.bootstrap,
seed=self.seed,
n_jobs=self.n_jobs
)
trees_pp.append(tree)
trees_pp=Parallel(n_jobs=16)( # do not use backend="threading"
delayed(_parallel_build_trees)(tree, X, y, i, len(trees_pp))
for i, tree in enumerate(trees_pp))
pallal_time_1=time.time() - start_time最后parallel python的训练:
# tuple of all parallel python servers to connect with
ppservers = () # ppservers = ("localhost",)
job_server=pp.Server(ppservers=ppservers)
print "Starting pp with", job_server.get_ncpus(), "workers"
trees_pppp=[]
start_time=time.time()
for i in range(n_more_estimator):
tree=MY_TreeClassifier(
criterion=self.criterion,
max_depth=self.max_depth,
min_leaf_split=self.min_leaf_split,
max_feature=self.max_feature,
bootstrap=self.bootstrap,
seed=self.seed,
n_jobs=self.n_jobs
)
trees_pppp.append(tree)
trees_pppp=[
job_server.submit(func=_parallel_build_trees, args=(t, X, y, i, len(trees_pppp),), depfuncs=(), modules=()) \
for i, t in enumerate(trees_pppp) ]
pallal_time_2=time.time() - start_time
print "sequential fit tree ==> time elapsed: ", sequential_time, "s", "^_^"*10
print "pallal fit tree ==> time elapsed: ", pallal_time_1, "s", "^_^"*10
print "pallal fit tree ==> time elapsed: ", pallal_time_2, "s", "^_^"*10
#wait for jobs in all groups to finish
job_server.wait()
job_server.print_stats()下面是训练100个树的时间:
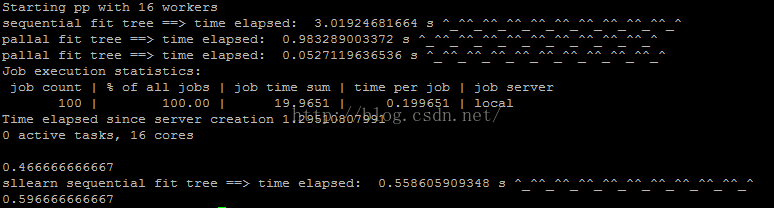
parallel python 用时略多于 sklearn joblib的parallel和delayed,这主要是因为前者需要启动server,但随着任务的增多(需要训练的树的增多),前者的用时逐渐少于后者,下面的时间对比说明了这一点。。。。
下面是训练200个树的时间:

可以看出:parallel python 好于 sklearn joblib的parallel和delayed 好于 sequential的训练
下面是训练500个树的时间:
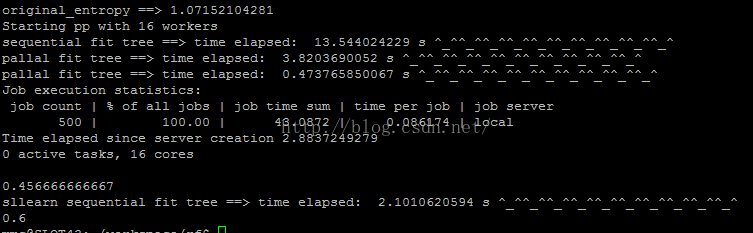
可以看到:sklearn joblib的parallel和delayed 及 sequential的训练,时间翻倍;但parallel python 虽然也增加了不少时间,但相对还较好。所以选择parallel python 绝对是不错的选择。
下面是训练1000个树的时间,结论类似:
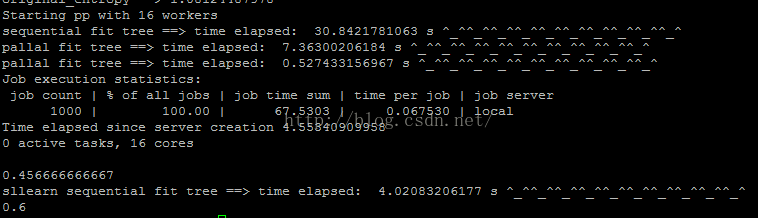
下面给出错误使用parallel python 的代码,这会使时间比顺序训练还要长。。。
ppservers = () # ppservers = ("localhost",)
job_server=pp.Server(ppservers=ppservers)
print "Starting pp with", job_server.get_ncpus(), "workers"
trees_pppp=[]
start_time=time.time()
for i in range(n_more_estimator):
tree=MY_TreeClassifier(
criterion=self.criterion,
max_depth=self.max_depth,
min_leaf_split=self.min_leaf_split,
max_feature=self.max_feature,
bootstrap=self.bootstrap,
seed=self.seed,
n_jobs=self.n_jobs
)
tree=job_server.submit(func=_parallel_build_trees, args=(tree, X, y, i, len(trees_pppp),), depfuncs=(), modules=())
trees_pppp.append(tree)最终结论:任务较少时,使用sklearn joblib的parallel和delayed训练加好;随着任务的增多(需要训练的树的增多),parallel python的优势逐渐体现出来。。。