机器学习面试重点知识点笔记
微信公众号:小白算法
关注可了解更多算法,并能领取免费资料。问题或建议,请公众号留言;
小白算法,一个人人都能懂的知识公众号。
目录
AI算法解决安全问题:
物联网环境下的网络安全
yolo v3
深度学习中的技巧:
卷积神经网络(CNN)中的独有技巧:
谈谈如何调参:
损失函数(Loss Function):是定义在单个样本上的,是指一个样本的误差。
代价函数(Cost Function):是定义在整个训练集上的,是所有样本误差的平均,也就是所有损失函数值的平均。
1.交叉熵损失函数是一个平滑函数,其本质是信息理论(information theory)中的交叉熵(cross entropy)在分类问题中的应用。由交叉熵的定义可知,最小化交叉熵等价于最小化观测值和估计值的相对熵;
均方误差:回归问题的损失函数
![]()
2.对于回归问题,我们可以选用均方误差(mean squared error),绝对误差(absolute Loss),决定系数(coefficient of determination )以及Huber Loss来度量模型的性能;
分类问题,我们可以用准确率,错误率,或者得到混淆矩阵,进一步得到查准率(precision)、查全率(recall)以及P-R曲线和ROC曲线。
3.softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类;
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
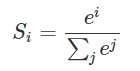
4.神经网络为什么会产生梯度消失现象?
只要是sigmoid函数的神经网络都会造成梯度更新的时候极其不稳定,产生梯度消失或者激增问题。
sigmoid 函数导数的图像
sigmoid函数在0附近时候,才会得到较大程度的激活;且小于1,导数<0.25。在前向传播时候,后面的模型参数是在前面参数的基础上得到的;在反向传播更新参数时候,前面的层上的梯度是来自后面的层上项的乘积,所以神经网络非常不稳定。
解决办法:relu激活函数。ReLU函数只能在隐藏层中使用
AI算法解决安全问题:
1.在网络安全中,它可以用于诸如用户行为分析以及欺诈检测等任务。网络流量分析是使用机器学习的另一个好选择。至于回归的技术方面,各种类型的递归神经网络效果最好。
2.对于网络层,我们可以将其应用于入侵检测系统(IDS),并识别不同类别的网络攻击,如扫描,欺骗等。在应用层,我们可以将它应用于WAF并检测OWASP top 10攻击。在终点层,我们可以将软件分为恶意软件,间谍软件和勒索软件等类别。最后,在用户级别上,它可以应用于反钓鱼解决方案,告诉我们特定的电子邮件是否合法。从技术上讲,SVM或随机森林等算法以及更好的简单的人工神经网络或卷积神经网络都可以解决这些任务。
3.我觉得聚类最好的任务之一就是取证分析——当我们不知道发生了什么事情并将所有活动分类以找出异常值时,恶意软件分析解决方案(即恶意软件防护)可以实施它来将合法文件与异常值分开。聚类可应用的另一个有趣的领域是用户行为分析。在这种情况下,应用程序用户聚集在一起,并且可以查看它们是否属于特定的组。根据他们所在的组,提供相应的有效的网络安全解决方案。
4.推荐系统是互联网时代非常出名的系统。例如,我们都使用Netflix和SoundCloud时,他们会根据你的电影或音乐偏好给你推荐他们认为你喜欢的电影或歌曲。这种思想同样也可以应用于网络安全,其中它主要可以用于事件响应。如果一家公司面临一系列事件并提出各种类型的响应,系统可以了解应针对特定事件推荐哪种类型的响应。风险管理解决方案还可以从中受益,因为它们可以自动为新漏洞分配风险值或基于其描述构建错误配置
物联网环境下的网络安全
深信服通过长期的实践总结出,网络安全的AI实践有三方面需要考虑::
1. 人工智能要与其他算法相融合
而人工智能算法并非适用于所有场景。在这样的情况下,基于规则、特征、统计的方法要和AI形成互补的关系
2. 人工智能要有持续进化的能力
人工智能算法要能够持续的检测新型威胁,需要不断被训练,靠的是不断的加入新的数据,以及攻防专家也不断对算法和模型进行调优。而拥有持续进化的能力,才是网络安全领域人工智能的灵魂。
3. 人工智能应当和人来协作分工,实现人机共智
yolo v3
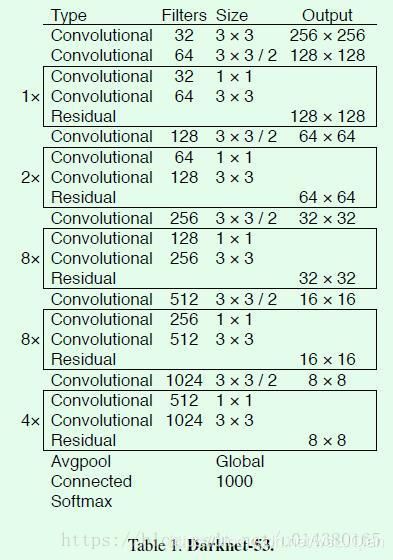
1.Darknet-53)一方面基本采用全卷积(YOLO v2中采用pooling层做feature map的sample,这里都换成卷积层来做了)
2.另一方面引入了residual结构.训深层网络难度大大减小,因此这里可以将网络做到53层,精度提升比较明显
3.bounding box的初始尺寸还是采用YOLO v2中的k-means聚类的方式来做
4.YOLO v3采用多个scale融合的方式做预测,提高对小目标检测的精确度
5.不再用softmax分类,Softmax类依赖于类是互斥的假设,或者简单地说,如果一个对象属于一个类,那么它就不属于另一个类。 这在COCO数据集中工作正常。但是,当我们在数据集中有Person和Women等类时,上述假设就失败了。 这就是为什么YOLO的作者没有采用softmax类的原因。 相反,使用逻辑回归预测每个类别分数,并且使用阈值来预测对象的多个标签。 分数高于此阈值的类将分配给该框。复合标签的方法能对数据进行更好的建模。(当图片中存在物体相互遮挡的情形时,一个box可能属于好几个物体,而不是单单的属于这个不属于那个,这时使用2分类的损失函数就更有优势)
该系列持续更新中,想get更多有趣的算法知识,或者提出宝贵意见,请关注微信公众号“小白算法”并联系我们
深度学习中的技巧:
- 初始化参数尽量小一些,这样 softmax 的回归输出更加接近均匀分布,使得刚开始网络并不确信数据属于哪一类;另一方面从数值优化上看我们希望我们的参数具有一致的方差(一致的数量级),这样我们的梯度下降法下降也会更快。同时为了使每一层的激励值保持一定的方差,我们在初始化参数(不包括偏置项)的方差可以与输入神经元的平方根成反比。
- 学习率(learning rate)的设置应该随着迭代次数的增加而减小,个人比较喜欢每迭代完一次epoch也就是整个数据过一遍,然后对学习率进行变化,这样能够保证每个样本得到了公平的对待;
- 滑动平均模型,在训练的过程中不断的对参数求滑动平均这样能够更有效的保持稳定性,使其对当前参数更新不敏感。例如加动量项的随机梯度下降法就是在学习率上应用滑动平均模型。
- 在验证集上微小的提升未必可信,一个常用的准则是增加了30个以上的正确样本,能够比较确信算法有了一定的提升;
- 不要太相信模型开始的学习速度,这与最终的结果基本没有什么关系。一个低的学习速率往往能得到较好的模型。
- 在深度学习中,常用的防止过拟合的方法除了正则化,dropout和pooling之外,还有提前停止训练的方法——就是看到我们在验证集的上的正确率开始下降就停止训练。
- 当激活函数是RELU时,我们在初始化偏置项时,为了避免过多的死亡节点(激活值为0)一般可以初始化为一个较小的正值。
- 基于随机梯度下降的改进优化算法有很多种,在不熟悉调参的情况,建议使用Adam方法。
- 如果我们设计的网络不work,在训练集的正确率也很低的话,我们可以减小样本数量同时去掉正则化项,然后进行调参,如果正确率还是不高的话,就说明我们设计的网络结果可能有问题。
- fine-tuning的时候,可以把新加层的学习率调高,重用层的学习率可以设置的相对较低。
- 在隐藏层的激活函数,tanh往往比sigmoid表现更好。
卷积神经网络(CNN)中的独有技巧:
- CNN中将一个大尺寸的卷积核可以分解为多层的小尺寸卷积核或者分成多层的一维卷积。这样能够减少参数增加非线性
- CNN中的网络设计应该是逐渐减小图像尺寸,同时增加通道数,让空间信息转化为高阶抽象的特征信息。
- CNN中可以利用Inception方法来提取不同抽象程度的高阶特征,用ResNet(残差)的思想来加深网络的层数。
- CNN处理图像时,常常会对原图进行旋转、裁剪、亮度、色度、饱和度等变化以增大数据集增加鲁棒性。
谈谈如何调参:
这些参数其实有一些是现在大家默认选择的,比如激活函数我们现在基本上都是采用Relu,而momentum一般我们会选择0.9-0.95之间,weight decay我们一般会选择0.005, filter的个数为奇数,而dropout现在也是标配的存在。这些都是近年来论文中通用的数值,也是公认出好结果的搭配。所以这些参数我们就没有必要太多的调整。下面是我们需要注意和调整的参数。
1. 完全不收敛:
请检测自己的数据是否存在可以学习的信息,这个数据集中的数值是否泛化(防止过大或过小的数值破坏学习)。
如果是错误的数据则你需要去再次获得正确的数据,
2. 部分收敛:
- underfitting:
增加网络的复杂度(深度),
降低learning rate,
优化数据集,
增加网络的非线性度(ReLu),
采用batch normalization,
- overfitting:
丰富数据,
增加网络的稀疏度,
降低网络的复杂度(深度),
L1 regularization,
L2 regulariztion,
添加Dropout,
Early stopping,
适当降低Learning rate,
适当减少epoch的次数,
3. 全部收敛:
调整方法就是保持其他参数不变,只调整一个参数。这里需要调整的参数会有:
learning rate,
minibatch size,
epoch,
filter size,
number of filter
参考文章:
原文:https://blog.csdn.net/h4565445654/article/details/70477979
原文:https://blog.csdn.net/qq_20259459/article/details/70316511
该系列持续更新中,想get更多有趣的算法知识,或者提出宝贵意见,请关注微信公众号“小白算法”并联系我们
