python爬取中国大学排名信息
运行环境:python3.6.0
功能:爬取个中国大学排名玩玩,网页链接:http://gaokao.afanti100.com/university.html。
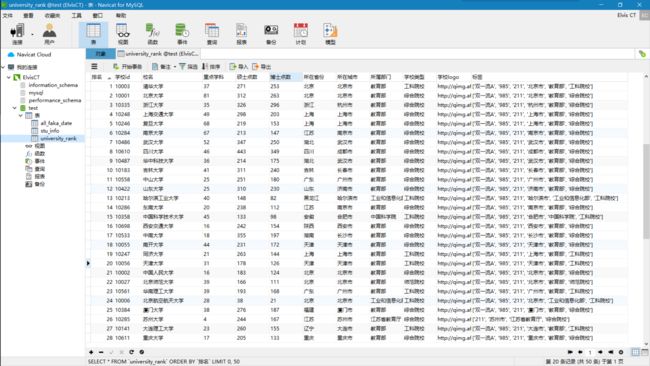
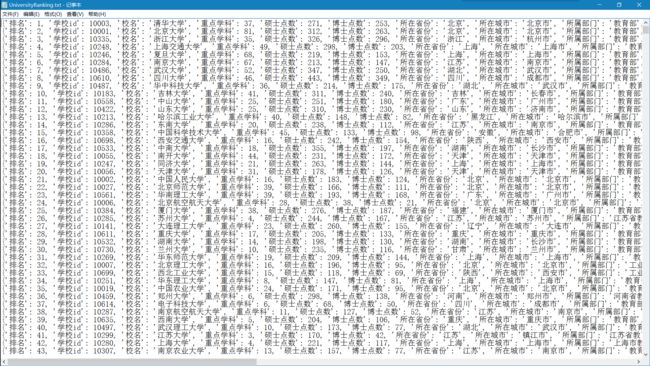
将爬取的结果保存至文本,上传至数据库,保存各院校校徽。
注意:
因为该网站收录了部分信息,所以信息可能不是很完整,但是一个信息都不放过。
内容仅供参考。
运行截图:
运行程序:
# -*- coding: utf-8 -*-
# Author: ElvisCT
# Function: 爬取中国大学排名,网页链接:http://gaokao.afanti100.com/university.html
# 将爬取的结果保存至文本,上传至数据库,保存各院校校徽
# Time: 2019年6月6日
import requests
from urllib.request import urlretrieve
import os
import pymysql
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
}
base_url = "http://gaokao.afanti100.com/api/v1/universities/?degree_level=0&directed_by=0&university_type=0&location_province=0&speciality=0&page={offset}"
num = 0 # 排名计数,因为发现后面的除了400强都没有统计,所以只能自己一下子了
# 爬去大学排名
class GetUniversityRanking(object):
def __init__(self, offset, f, db, cursor):
self.offset = offset # 页码
self.url = base_url.format(offset=self.offset) # 爬去的url
self.headers = headers
self.f = f # 数据保存
self.db = db
self.cursor = cursor
self.logo_path = "save_logo" # logo路径
if not os.path.exists(self.logo_path): # 判断logo路径是否存在
os.mkdir(self.logo_path)
def get_page(self):
"""
拿到每页大学的json源码
:return: 每页大学的json源码
"""
try:
response = requests.request(method="get", url=self.url, headers=self.headers, timeout=5)
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.json()
else:
print("Request Error", response.status_code)
return None
except requests.RequestException as e:
print("Request Exception", e.args)
return None
def save_info(self, info):
"""
保存提取后的大学信息
:param info: 提取后的大学信息
:return: None
"""
self.f.write(str(info))
self.f.write("\n")
self.f.flush()
def save_logo(self, logo_url, logo_name):
"""
保存logo图片
:param logo_url: logo的url
:param logo_name: logo名字
:return: None
"""
urlretrieve(logo_url, '%s/%s.jpg' % (self.logo_path, logo_name))
def save_db(self, info):
"""
保存采集的信息至数据库
:param info: 保存的信息
:return: None
"""
db_attr = ('排名', '学校id', '校名', '重点学科', '硕士点数', '博士点数', '所在省份', '所在城市', '所属部门', '学校类型', '学校logo', '标签')
item = list(info.values())
item[-1] = str(item[-1])
table = 'university_rank'
keys = ', '.join(db_attr)
values = ', '.join(['%s'] * len(db_attr))
# sql = 'INSERT INTO {table} ({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
sql = 'INSERT INTO {table} ({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE'.format(table=table, keys=keys, values=values)
update = ','.join([' {key} = %s'.format(key=key) for key in db_attr])
sql += update
try:
self.cursor.execute(sql, tuple(item)*2)
self.db.commit()
except Exception as e:
print(sql)
print(type(item), item)
print('error', e.args)
self.db.rollback()
def parse_page(self):
"""
json文件数据解析
:return: None
"""
html_json = self.get_page()
if html_json:
university_infos = html_json.get("data").get("university_lst")
info = dict()
for item in university_infos:
info["排名"] = item.get("ranking")
info["学校id"] = item.get("university_id")
info["校名"] = item.get("name")
info["重点学科"] = item.get("key_major_count")
info["硕士点数"] = item.get("graduate_program_count")
info["博士点数"] = item.get("doctoral_program_count")
info["所在省份"] = item.get("location_province")
info["所在城市"] = item.get("location_city")
info["所属部门"] = item.get("directed_by")
info["学校类型"] = item.get("university_type")
info["学校logo"] = item.get("logo_url")
info["标签"] = item.get("tag_lst")
global num
num += 1
info["排名"] = num
# self.save_logo(logo_url=info["学校logo"], logo_name=info["校名"])
self.save_logo(logo_url=item.get("logo_url"), logo_name=item.get("name")) # logo地址,logo名称
self.save_info(info=info)
self.save_db(info=info)
print(info)
def run(self):
"""
运行程序
:return: None
"""
self.parse_page()
def main():
"""
主函数
:return: None
"""
MIN_PAGE = 1
MAX_PAGE = 188
f = open("UniversityRanking.txt", "w", encoding="utf-8")
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='test')
cursor = db.cursor()
for offset in range(MIN_PAGE, MAX_PAGE+1):
university = GetUniversityRanking(offset, f, db, cursor)
university.run()
cursor.close()
db.close()
f.close()
if __name__ == '__main__':
main()