TOPSIS法(优劣解距离法)笔记
TOPSIS法 什么时候用?
TOPSIS法 是根据有限个评价对象与理想化目标的接近程度进行排序的方法,是在现有的对象中进行相对优劣的评价
【其中最优解的各指标值都达到各评价指标的最优值,最劣解的各指标值都达到各评价指标的最差值】
TOPSIS法 特别适合具有多组评价对象时,要求通过检测评价对象与最优解、最劣解的距离来进行排序
作业解答
如何改编代码,使用户能选择是否加入指标的权重计算?
% % % % % % % % % % % % % % % % % % % % % % % 举个例子 % % % % % % % % % % % % % % % % % % % % % % %
% 假如原始数据为:
A = [1, 2, 3;
2, 4, 6]
% 权重矩阵为:
B = [ 0.2, 0.5 ,0.3 ]
% 加权后输出:
0.2000 1.0000 0.9000
0.4000 2.0000 1.8000 % 加权后的矩阵 C
% 简约的代码如下:
C = A;
for i = 1: size(A,2)
C(:,i) = C(:,i) .* B(i);
end
disp(C)
% % % % % % % % % % % % % % % % % % % % % % % 正式代码 % % % % % % % % % % % % % % % % % % % % % % %
disp('请输入是否需要增加权重向量,需要输入1,不需要输入0')
Judge = input('请输入是否需要增加权重: ');
if Judge == 1
disp(['如果你有3个指标,你就需要输入3个权重,例如它们分别为0.25,0.25,0.5, 则你需要输入[0.25,0.25,0.5]']);
weigh = input(['你需要输入' num2str(m) '个权数。' '请以行向量的形式输入这' num2str(m) '个权重: ']);
OK = 0; % 用来判断用户的输入格式是否正确
while OK == 0
if abs(sum(weigh) - 1)<0.000001 && size(weigh,1) == 1 && size(weigh,2) == m % 这里要注意浮点数
OK =1;
else
weigh = input('你输入的有误,请重新输入权重行向量: ');
end
end
else
weigh = ones(1,m) ./ m ; %如果不需要加权重就默认权重都相同,即都为1/m
end
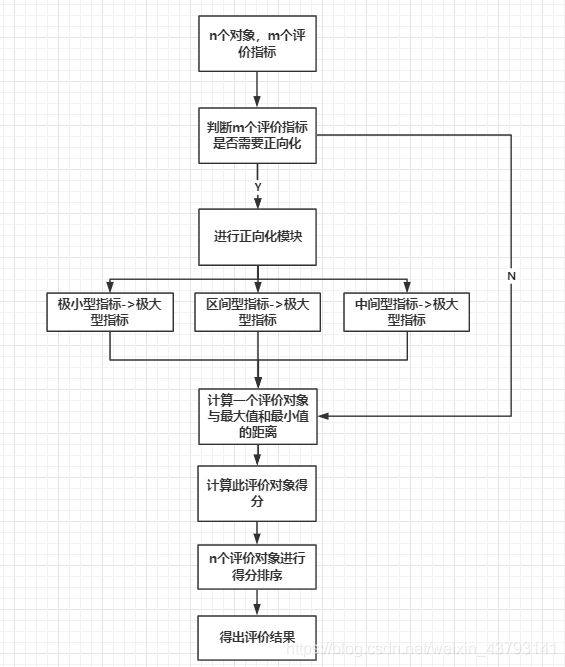
TOPSIS法的顺序
① 正向化(每一列都转为极大型)
② 标准化(每一个元素都被标准化处理)
③ 归一化(每一列的和都为 1 )
④ 计算权重(求每一行的和)
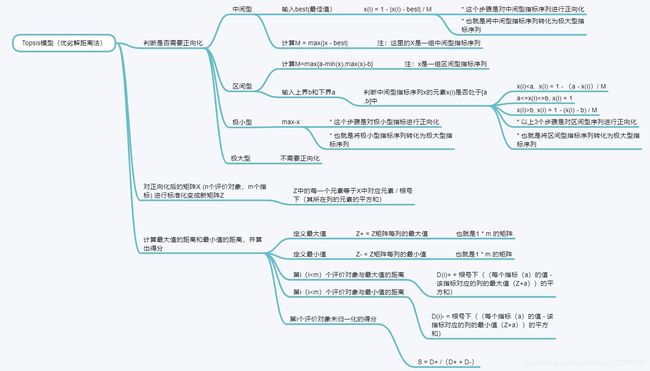
下图引用自 数学建模优劣解距离算法——Topsis模型
什么时候用熵权法?
可以用熵值来判断某个指标的离散程度,其信息熵值越小,指标的离散程度越大, 该指标对综合评价的影响(即权重)就越大,因此,可利用信息熵这个工具,计算出各个指标的权重【如果某项指标的值全部相等,则该指标在综合评价中不起作用】
对于一些数据容易获取的分析,个人觉得熵值法可靠一些
对于数据比较难获取且存在相关及共线性问题的话建议采取主成分分析法(第14讲学)
TOPSIS法的代码部分
%% 第一步:把数据复制到工作区,并将这个矩阵命名为 X
load data_water_quality.mat % 数据的名字叫 data_water_quality
%% 第二步:判断是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']);
if Judge == 1
Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: ');%[2,3,4]
disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ')
Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: '); % [2,1,3]
for i = 1 : size(Position,2)
X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));
end
disp('正向化后的矩阵 X = ')
disp(X)
end
%% 第三步:对正向化后的矩阵进行标准化
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)
%% 第四步:让用户判断是否需要增加权重(可以自己决定权重,也可以用熵权法确定权重)
disp("请输入是否需要增加权重向量,需要输入1,不需要输入0")
Judge = input('请输入是否需要增加权重: ');
if Judge == 1
Judge = input('使用熵权法确定权重请输入1,否则输入0: ');
if Judge == 1
if sum(sum(Z<0)) >0 % 如果之前标准化后的Z矩阵中存在负数,则重新对X进行标准化
disp('原来标准化得到的Z矩阵中存在负数,所以需要对X重新标准化')
for i = 1:n
for j = 1:m
Z(i,j) = [X(i,j) - min(X(:,j))] / [max(X(:,j)) - min(X(:,j))];
end
end
disp('X重新进行标准化得到的标准化矩阵Z为: ')
disp(Z)
end
weight = Entropy_Method(Z);
disp('熵权法确定的权重为:')
disp(weight)
else
disp(['如果你有3个指标,你就需要输入3个权重,例如它们分别为0.25,0.25,0.5, 则你需要输入[0.25,0.25,0.5]']);
weight = input(['你需要输入' num2str(m) '个权数。' '请以行向量的形式输入这' num2str(m) '个权重: ']);
OK = 0; % 用来判断用户的输入格式是否正确
while OK == 0
if abs(sum(weight) -1)<0.000001 && size(weight,1) == 1 && size(weight,2) == m % 注意浮点数
OK =1;
else
weight = input('你输入的有误,请重新输入权重行向量: ');
end
end
end
else
weight = ones(1,m) ./ m ; %如果不需要加权重就默认权重都相同,即都为1/m
end
%% 第五步:计算与最大值的距离和最小值的距离,并算出得分
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ] .* repmat(weight,n,1) ,2) .^ 0.5; % D+ 与最大值的距离向量
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ] .* repmat(weight,n,1) ,2) .^ 0.5; % D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S)
[sorted_S,index] = sort(stand_S ,'descend')
切记不能直接用于论文中,要根据题目适当的修改,避免查重
TOPSIS法的评估
Topsis法 的优点:
(1) 避免了数据的主观性,不需要目标函数,不用通过检验,而且能够很好的刻画多个影响指标的综合影响力度
(2) 对于数据分布及样本量、指标多少无严格限制,既适于小样本资料,也适于多评价单元、多指标的大系统,较为灵活、方便
Topsis法 的缺点:
(1) 需要的每个指标的数据,对应的量化指标选取会有一定难度
(2) 不确定指标的选取个数为多少适宜,才能够去很好刻画指标的影响力度
(3) 必须有两个以上的研究对象才可以进行使用
其他文件
%% Entropy_Method.m % 是熵权法计算权重的函数
function [W] = Entropy_Method(Z)
[n,m] = size(Z);
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:m
x = Z(:,i); % 取出第i列的指标
p = x / sum(x);
% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以这里我们自己定义一个函数
e = -sum(p .* mylog(p)) / log(n); % 计算信息熵
D(i) = 1- e; % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
end
%% mylog.m % 用于替代MATLAB中的log函数,因为计算熵权法时需要判断 p = 0
function [lnp] = mylog(p)
n = length(p); % 向量的长度
lnp = zeros(n,1); % 初始化最后的结果
for i = 1:n % 开始循环
if p(i) == 0 % 如果第i个元素为0
lnp(i) = 0; % 那么返回的第i个结果也为0
else
lnp(i) = log(p(i));
end
end
end
%% Positivization.m % 是处理矩阵正向化的函数
function [posit_x] = Positivization(x,type,i)
if type == 1 %极小型
disp(['第' num2str(i) '列是极小型,正在正向化'] )
posit_x = Min2Max(x); %调用Min2Max函数来正向化
disp(['第' num2str(i) '列极小型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
elseif type == 2 %中间型
disp(['第' num2str(i) '列是中间型'] )
best = input('请输入最佳的那一个值: ');
posit_x = Mid2Max(x,best);
disp(['第' num2str(i) '列中间型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
elseif type == 3 %区间型
disp(['第' num2str(i) '列是区间型'] )
a = input('请输入区间的下界: ');
b = input('请输入区间的上界: ');
posit_x = Inter2Max(x,a,b);
disp(['第' num2str(i) '列区间型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
else
disp('没有这种类型的指标,请检查Type向量中是否有除了1、2、3之外的其他值')
end
end
%% Min2Max.m 、Mid2Max.m 、Inter2Max.m % 处理极小型、中间型、区间型的函数
function [posit_x] = Min2Max(x) % 极小型
posit_x = max(x) - x;
end
function [posit_x] = Mid2Max(x,best) % 中间型
M = max(abs(x-best));
posit_x = 1 - abs(x-best) / M;
end
function [posit_x] = Inter2Max(x,a,b) % 区间型
r_x = size(x,1); % row of x
M = max([a-min(x),max(x)-b]);
posit_x = zeros(r_x,1);
% 初始化posit_x全为0
for i = 1: r_x
if x(i) < a
posit_x(i) = 1-(a-x(i))/M;
elseif x(i) > b
posit_x(i) = 1-(x(i)-b)/M;
else
posit_x(i) = 1;
end
end
end