基于webmagic框架爬取九九小说网小说资源
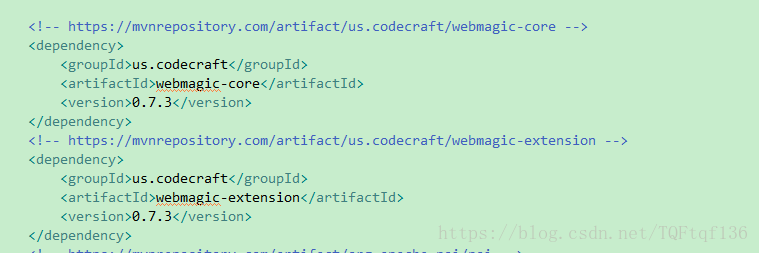
1.首先导入webmagic maven相关配置
目前我是在http://mvnrepository.com/ 官网上查询的最新的jar包
2.新建 JiujiuProcessor类实现PageProcessor接口,其中需要重写两个方法,getSite()和process(Page page),其中主要是重写process(Page page)方法,主要代码如下
JiujiuProcessor 类:
package test;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import common.util.HttpClientUtils;
import common.util.HttpClientUtils.HttpClientDownLoadProgress;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* 九九小说网小说爬虫
*
* @author qinfangtu
* @date 2018年7月18日
*/
public class JiujiuProcessor implements PageProcessor {
// 抓取网站的相关配置,包括:编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
// 文章数量
private static int size = 0;
private static List bookUrls = new ArrayList<>();
private static List trueBookUrls = new ArrayList<>();
private static String[] typeName = new String[] { "武侠仙侠", "言情小说", "玄幻小说", "现代都市", "穿越小说", "科幻小说", "网游竞技", "美文同人",
"惊悚悬疑", "管理哲学", "学习资料", "文学经典", "剧情剧本" };
private static int[] type = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 };
@Override
public Site getSite() {
return site;
}
@Override
public void process(Page page) {
List list1 = page.getHtml().xpath("//div[@id='catalog']/div[@class='listbg']/a").links().all();
// 去重复URL
list1 = list1.stream().distinct().collect(Collectors.toList());
// 获取唯一标识
for (String string : list1) {
String temp = string.substring(string.lastIndexOf("/"), string.lastIndexOf("."));
String bookUrl = "http://www.jjxsw.org/home/down/txt/id" + temp;
bookUrls.add(bookUrl);
}
size = bookUrls.size();
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
String url = null;
for (int i = 0; i < 13; i++) {
JiujiuProcessor.bookUrls.clear();
JiujiuProcessor.trueBookUrls.clear();
for (int j = 0; j < 10; j++) {//目前爬取10页的小说,一种类型前一百篇小说
url = "http://www.jjxsw.org/txt/list"+type[i]+"-"+j+".html";
Spider.create(new JiujiuProcessor()).addUrl(url).thread(10).run();
}
for (String bookUrl : JiujiuProcessor.bookUrls) {
//拿到真正的小说下载地址
String trueUrl = HttpClientUtils.httpDownloadFile1(bookUrl);
if (!trueUrl.contains("[")) {
trueBookUrls.add(trueUrl);
}
}
for (String trueUrl : JiujiuProcessor.trueBookUrls) {
String bookName = trueUrl.substring(trueUrl.lastIndexOf("/"));
System.out.println(trueUrl);
HttpClientUtils.getInstance().download(
trueUrl, "D:/books2/"+typeName[i], bookName,
new HttpClientDownLoadProgress() {
@Override
public void onProgress(int progress) {
}
});
}
}
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了" + size + "条记录");
}
}
HttpClientUtils 请求工具类:
package common.util;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Scanner;
import java.util.Set;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
public class HttpClientUtils {
/**
* 最大线程池
*/
public static final int THREAD_POOL_SIZE = 5;
public interface HttpClientDownLoadProgress {
public void onProgress(int progress);
}
private static HttpClientUtils httpClientDownload;
private ExecutorService downloadExcutorService;
private HttpClientUtils() {
downloadExcutorService = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
}
public static HttpClientUtils getInstance() {
if (httpClientDownload == null) {
httpClientDownload = new HttpClientUtils();
}
return httpClientDownload;
}
/**
* 下载文件
*
* @param url
* @param filePath
* @param httpClientDownLoadProgress
* @param bookName
*/
public void download(final String url, final String filePath, String bookName, HttpClientDownLoadProgress httpClientDownLoadProgress) {
downloadExcutorService.execute(new Runnable() {
@Override
public void run() {
httpDownloadFile(url, filePath,bookName, null, null);
}
});
}
/**
* 下载文件
*
* @param url
* @param filePath
*/
public static String httpDownloadFile1(String url) {
CloseableHttpClient httpclient = HttpClients.createDefault();
String text = "";
try {
HttpPost httpPost = new HttpPost(url);
CloseableHttpResponse response1 = httpclient.execute(httpPost);
try {
System.out.println(response1.getStatusLine());
HttpEntity httpEntity = response1.getEntity();
InputStream is = httpEntity.getContent();
// 根据InputStream 下载文件
Scanner scan = new Scanner(is);
while(scan.hasNext()){
text += scan.next();
}
EntityUtils.consume(httpEntity);
} finally {
response1.close();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return text.substring(text.indexOf("http"),text.indexOf("txt")+3);
}
private void httpDownloadFile(String url, String filePath,
String bookName, HttpClientDownLoadProgress progress, Map headMap) {
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
HttpGet httpGet = new HttpGet(url);
setGetHead(httpGet, headMap);
CloseableHttpResponse response1 = httpclient.execute(httpGet);
try {
HttpEntity httpEntity = response1.getEntity();
long contentLength = httpEntity.getContentLength();
InputStream is = httpEntity.getContent();
// 根据InputStream 下载文件
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[8192];
int r = 0;
long totalRead = 0;
while ((r = is.read(buffer)) > 0) {
output.write(buffer, 0, r);
totalRead += r;
if (progress != null) {// 回调进度
progress.onProgress((int) (totalRead * 100 / contentLength));
}
}
File file = new File(filePath);
if (!file.exists()) {
file.mkdirs();
}
FileOutputStream fos = new FileOutputStream(filePath + bookName);
output.writeTo(fos);
output.flush();
output.close();
fos.close();
EntityUtils.consume(httpEntity);
} finally {
response1.close();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* get请求
*
* @param url
* @return
*/
public String httpGet(String url) {
return httpGet(url, null);
}
/**
* http get请求
*
* @param url
* @return
*/
public String httpGet(String url, Map headMap) {
String responseContent = null;
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response1 = httpclient.execute(httpGet);
setGetHead(httpGet, headMap);
try {
System.out.println(response1.getStatusLine());
HttpEntity entity = response1.getEntity();
responseContent = getRespString(entity);
System.out.println("debug:" + responseContent);
EntityUtils.consume(entity);
} finally {
response1.close();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return responseContent;
}
public String httpPost(String url, Map paramsMap) {
return httpPost(url, paramsMap, null);
}
/**
* http的post请求
*
* @param url
* @param paramsMap
* @return
*/
public String httpPost(String url, Map paramsMap,
Map headMap) {
String responseContent = null;
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
HttpPost httpPost = new HttpPost(url);
setPostHead(httpPost, headMap);
setPostParams(httpPost, paramsMap);
CloseableHttpResponse response = httpclient.execute(httpPost);
try {
System.out.println(response.getStatusLine());
HttpEntity entity = response.getEntity();
responseContent = getRespString(entity);
EntityUtils.consume(entity);
} finally {
response.close();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("responseContent = " + responseContent);
return responseContent;
}
/**
* 设置POST的参数
*
* @param httpPost
* @param paramsMap
* @throws Exception
*/
private void setPostParams(HttpPost httpPost, Map paramsMap)
throws Exception {
if (paramsMap != null && paramsMap.size() > 0) {
List nvps = new ArrayList();
Set keySet = paramsMap.keySet();
for (String key : keySet) {
nvps.add(new BasicNameValuePair(key, paramsMap.get(key)));
}
httpPost.setEntity(new UrlEncodedFormEntity(nvps));
}
}
/**
* 设置http的HEAD
*
* @param httpPost
* @param headMap
*/
private void setPostHead(HttpPost httpPost, Map headMap) {
if (headMap != null && headMap.size() > 0) {
Set keySet = headMap.keySet();
for (String key : keySet) {
httpPost.addHeader(key, headMap.get(key));
}
}
}
/**
* 设置http的HEAD
*
* @param httpGet
* @param headMap
*/
private void setGetHead(HttpGet httpGet, Map headMap) {
if (headMap != null && headMap.size() > 0) {
Set keySet = headMap.keySet();
for (String key : keySet) {
httpGet.addHeader(key, headMap.get(key));
}
}
}
/**
* 将返回结果转化为String
*
* @param entity
* @return
* @throws Exception
*/
private String getRespString(HttpEntity entity) throws Exception {
if (entity == null) {
return null;
}
InputStream is = entity.getContent();
StringBuffer strBuf = new StringBuffer();
byte[] buffer = new byte[4096];
int r = 0;
while ((r = is.read(buffer)) > 0) {
strBuf.append(new String(buffer, 0, r, "UTF-8"));
}
return strBuf.toString();
}
}
3.最后爬取的小说如下,我进行的文件夹分隔处理
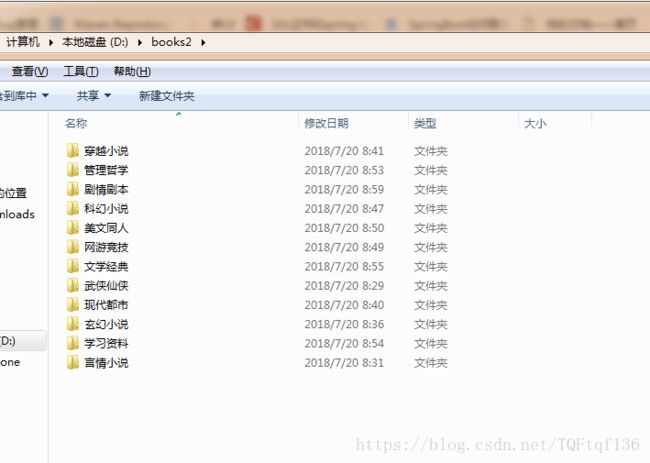
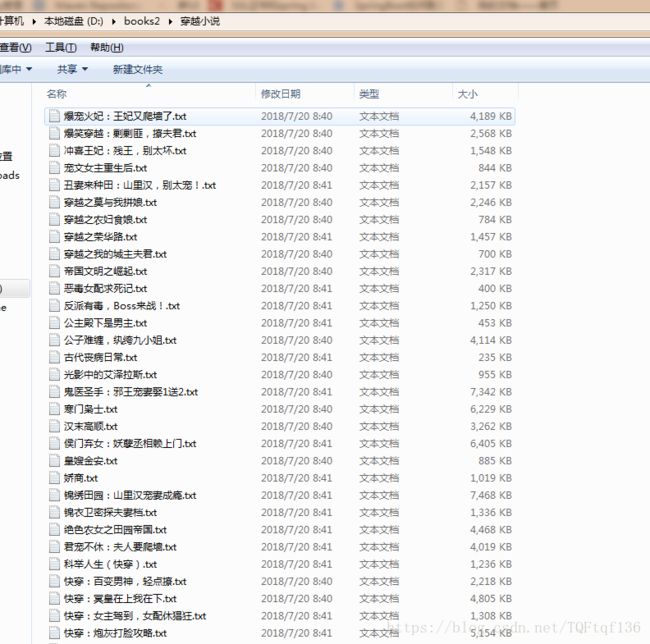
4.补充:这个网站看似简单,实则比较狡诈,哈哈哈,一开始以为拿到了规律直接去下载,谁知道他进行重定向了,所以需要在流里拿到重定向的url,需要再请求真实的url去下载小说,随便写写,喜欢看小说的可以去试试,不喜欢看小说的可以把小说拉下来給喜欢看小说的人去看,男生可以用小说去撩撩妹,毕竟10个妹子里面有9个喜欢看小说,哈哈哈哈