机器学习之路六:文本特征提取
三种特征提取方式:
TF-IDF
Word embedding
Word2vec
TF-IDF,词频-逆文件频率


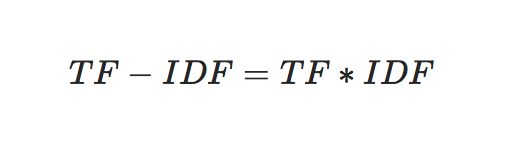
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
文本特征提取函数CountVectorizer()和TfidfVectorizer()
https://blog.csdn.net/lyn5284767/article/details/85316931
Word embedding

Embedding层就是以one hot为输入、中间层节点为字向量维数的全连接层!而这个全连接层的参数,就是一个“字向量表”!字向量就是one hot的全连接层的参数!
Word2vec
深度学习文本分类方法
卷积神经网络(TextCNN)
循环神经网络(TextRNN)
TextRNN+Attention
TextRCNN(TextRNN+CNN)
文本分类方法综述
http://blog.nsfocus.net/text-categorization-practice-based-keras/
传统文本分类方法
基于逻辑回归模型
https://github.com/Edward1Chou/Textclassification
针对文本分类的CNN结构

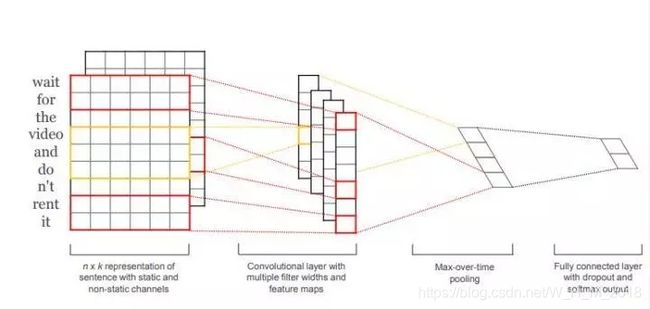
“Convolutional Neural Networks for Sentence Classification”
模型的主要结构:
输入层+第一层卷积层+池化层+全连接+softmax层
# 创建tensor
print("正在创建模型...")
inputs=Input(shape=(sequence_length,),dtype='int32')
embedding=Embedding(input_dim=vocabulary_size,output_dim=embedding_dim,input_length=sequence_length)(inputs)
reshape=Reshape((sequence_length,embedding_dim,1))(embedding)
# cnn
conv_0=Conv2D(num_filters,kernel_size=(filter_sizes[0],embedding_dim),padding='valid',kernel_initializer='normal',activation='relu')(reshape)
conv_1=Conv2D(num_filters,kernel_size=(filter_sizes[1],embedding_dim),padding='valid',kernel_initializer='normal',activation='relu')(reshape)
conv_2=Conv2D(num_filters,kernel_size=(filter_sizes[2],embedding_dim),padding='valid',kernel_initializer='normal',activation='relu')(reshape)
maxpool_0=MaxPool2D(pool_size=(sequence_length-filter_sizes[0]+1,1),strides=(1,1),padding='valid')(conv_0)
maxpool_1=MaxPool2D(pool_size=(sequence_length-filter_sizes[1]+1,1),strides=(1,1),padding='valid')(conv_1)
maxpool_2=MaxPool2D(pool_size=(sequence_length-filter_sizes[2]+1,1),strides=(1,1),padding='valid')(conv_2)
concatenated_tensor = Concatenate(axis=1)([maxpool_0, maxpool_1, maxpool_2])
flatten = Flatten()(concatenated_tensor)
dropout = Dropout(drop)(flatten)
output = Dense(units=2, activation='softmax')(dropout)
model=Model(inputs=inputs,outputs=output)
实验结果

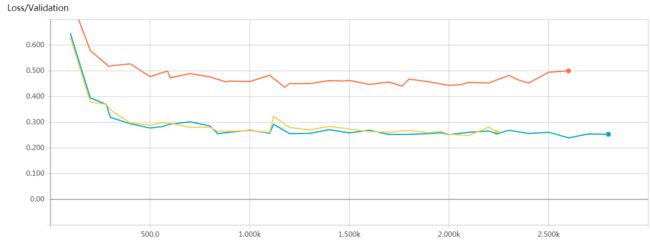
为了检验模型在真实数据上的分类准确率,我们又额外人工审核了1000条深圳地区的案情数据,相较于原来分类准确率的68%,提升到了现在的90%,说明我们的模型确实有效,相对于原来的模型有较大的提升。

红色:word2vec+CNN(max_pooling)在验证集上的准确率走势图
黄色和蓝色:word2vec+CNN(batch normalization & chunk max_pooling:2 chunk)在验证集上的准确率走势图
实例
Logistic regression 与 CNN text
https://github.com/Edward1Chou/Textclassification
CNN文本分类流程
https://blog.csdn.net/vivian_ll/article/details/80829474