一开始按照视频上的找了笔趣阁的网站先爬一部小说, 找了<遮天>,但是章节太多,爬起来太慢, 就换了一个几十章的小说.
根据视频里的去写了代码, 在正则表达式哪里出了很大的问题.
from bs4 import BeautifulSoup
import requests
import re先找到了小说主页的链接地址: url = 'https://www.biquge5.com/3_3004/'
reponse = requests.get(url)
reponse.encoding = 'gbk'html = reponse.text
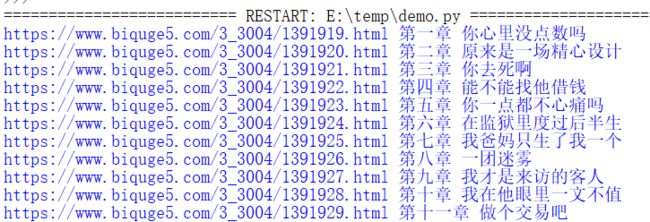
这是网页的部分代码
<div id="list"><ul class="_chapter"> <li><a href="https://www.biquge5.com/3_3004/ 1391919.html">第一章 你心里没点数吗a>li><li><a href="https://www.biquge5.com/3_3004/ 1391920.html">第二章 原来是一场精心设计a>li><li><a href="https://www.biquge5.com/3_3004/ 1391921.html">第三章 你去死啊a>li><li><a href="https://www.biquge5.com/3_3004/ 1391922.html">第四章 能不能找他借钱a>li><li><a href="https://www.biquge5.com/3_3004/ 1391923.html">第五章 你一点都不心痛吗a>li><li><a href="https://www.biquge5.com/3_3004/ 1391924.html">第六章 在监狱里度过后半生a>li><li><a href="https://www.biquge5.com/3_3004/ 1391925.html">第七章 我爸妈只生了我一个a>li><li><a href="https://www.biquge5.com/3_3004/ 1391926.html">第八章 一团迷雾a>li>写出正则表达式,找到ul标签里面的链接: dl = re.findall(r'
(.*?)<', html, re.S) 结果返回了空列表. 又试了几种正则表示,还是错误的. 检查了好久也查不出原因.
最后直接打开浏览器, 在小说首页查看源代码, 复制了href链接到搜索栏里, 出现了 404 !
又回到源代码, 仔细看一下发现href里只有http--3004/有蓝色标记,后面的139.....没有, 于是只复制了前面的http--3004/, 没想到竟然跳转到了小说章节内容.
于是又复制了一遍href里的链接,发现在浏览器搜索框里出现了一个'\n'换行符,把它去点后也可以 正常访问. 看来就是这个'\n'符就是万恶之源了.
修改代码: dl = re.findall(r'
(.*?)<' (\s代表可以匹配换行空格等一切字符) 可是还是有问题, 就是在返回的列表里面,链接还是有\n.
干脆就把所有的换行符都换掉好了: html = html.replace('\n','')
至此,问题解决了

代码:
1 from bs4 import BeautifulSoup 2 import requests 3 import re 4 url = 'https://www.biquge5.com/3_3004/' 5 reponse = requests.get(url) 6 reponse.encoding = 'gbk' 7 '''soup = BeautifulSoup(reponse.text, 'lxml') 8 chapter = soup.select('ul._chapter > li > a') 9 temp=[] #链接 10 temp2=[] #章节标题''' 11 12 ''' 13 #用字典 14 for c in chapter: 15 temp.append(c.get_text()) 16 temp2.append(c.get('href')) 17 print(temp2)''' 18 '''f = open('遮天.txt','w') 19 for i in temp: 20 f.write(str(i)) 21 f.write('\n') 22 print('ok') 23 f.close()''' 24 '''f = open('遮天.txt','w') 25 for c in chapter: 26 data={ 27 'clink': c.get('href'), 28 'ctitle': c.get_text() 29 } 30 for i in data.values(): 31 f.write(i[1]) 32 print('ok') 33 exit() 34 35 tml = reponse.text 36 html = html.replace('\n','') 37 dl = re.findall(r'(.*?)<', html, re.S) 38 #print((chapter_info_list)) 39 for i in dl: 40 m,n=i 41 m="https://www.biquge5.com/3_3004/\n%s" % m 42 print(m,n) 43 ''' 44 45 46 html = reponse.text 47 html = html.replace('\n','') 48 dl = re.findall(r'(.*?)< ', html, re.S) 49 for i in dl: 50 m,n=i 51 m="https://www.biquge5.com/3_3004/%s" % m #将链接前面的东西加到m上, + 的方式效率低,采用占位符%S代替. 52 print(m,n)
结果: