Python3 爬虫拉勾网抓取数据保存在Excel中
操作环境:Python 3.6、Pycharm 2017.2.3
前言
本人渣渣一枚,为爬虫拉勾网获取数据,将获得的数据保存在Excel中,这中间的过程大概花费了我两天的时间(捂脸),期间参考了很多博客,自己也一直在探索,终于折腾出来了,现在一步步地把步骤写出来。
步骤一 – 分析拉勾网
1、首先打开拉勾网,然后借助Chrome浏览器的开发工具进行分析,即按F12,记得勾上Presever Log这个选项

接着我们选择NetWork – XHR来查看网页请求,在之前看很多博主都说主要分析页面是那个pisotion开头的,但是我怎么找都找不到,后来偶尔发现你需要在搜索的时候选上工作地点才出来那个页面
2、我随便选了一个北京吧,然后按F5刷新一下页面就能看到所有的网络请求了,果不其然,那个position页面出来了,于是点进去分析
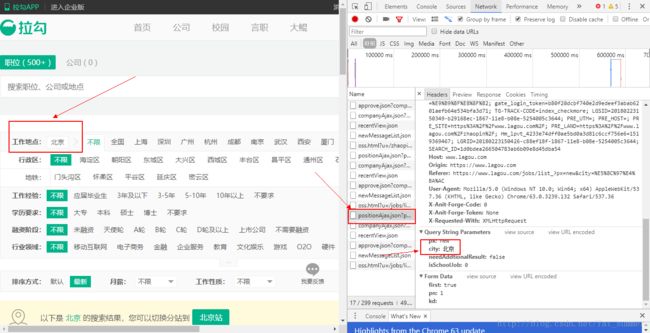
3、接着我们分析Previiew中的数据,发现在content>positionResult>result中的数据和我们在拉勾网页面看到的是一模一样的,没错,我们主要分析这里就可以了
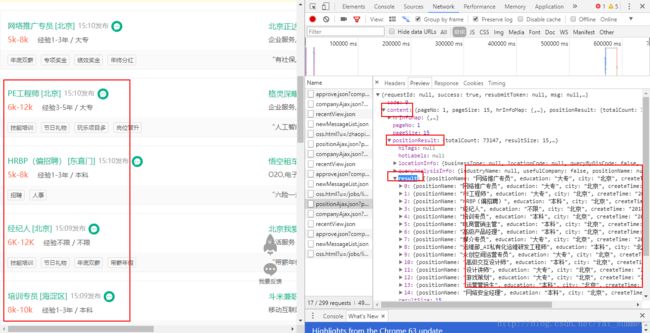
4、那么在审查元素的时候,我们可以得到以下的信息
URL:https://www.lagou.com/jobs/positionAjax.json?px=new&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0,其中的city参数就是我们选中的工作地点啦
代码
代码分析我就不一步步说了,毕竟我是初学者,也不是很懂,哈哈,现在我附上我的完整代码,可以成功运行,抓取到前6页的数据
import requests#导入库
import xlsxwriter
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E',
'Cookie': 'user_trace_token=20171010203203-04dbd95d-adb7-11e7-946a-5254005c3644; LGUID=20171010203203-04dbddae-adb7-11e7-946a-5254005c3644; index_location_city=%E5%B9%BF%E5%B7%9E; JSESSIONID=ABAAABAABEEAAJA8BF3AD5C8CFD40070BD3A86E50B0F9E4; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_Python%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D; TG-TRACK-CODE=index_navigation; SEARCH_ID=0cc609743acc4bf18789b584210f6ccb; _gid=GA1.2.271865682.1507638722; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507638723; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507720548; _ga=GA1.2.577848458.1507638722; LGSID=20171011190218-a611d705-ae73-11e7-8a7a-525400f775ce; LGRID=20171011191547-882eafd3-ae75-11e7-8a92-525400f775ce'
}
def getJobList(page):
formData = {
'first': 'false',
'pn': page,
'kd': 'Python'
}
res = requests.post(
# 请求的url
url='https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=0',
# 添加headers信息
headers=headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result']
return jobsInfo
workbook = xlsxwriter.Workbook(‘Python职位信息.xlsx’) # 创建一个excel表格
worksheet = workbook.add_worksheet()# 为创建的excel表格添加一个工作表
def writeExcel(row=0, positionId=’职位ID’, positionName=’职位名称’, salary=’薪资’, createTime=’发布时间’, workYear=’工作经验’,education=’学历’, firstType=’职位大类’, city=’城市’, companyFullName=’公司名’):# 将数据写入工作表中
if row == 0:
worksheet.write(row, 0, positionId)
worksheet.write(row, 1, positionName)
worksheet.write(row, 2, salary)
worksheet.write(row, 3, createTime)
worksheet.write(row, 4, workYear)
worksheet.write(row, 5, education)
worksheet.write(row, 6, firstType)
worksheet.write(row, 7, city)
worksheet.write(row, 8, companyFullName)
else:
worksheet.write(row, 0, job['positionId'])
worksheet.write(row, 1, job['positionName'])
worksheet.write(row, 2, job['salary'])
worksheet.write(row, 3, job['createTime'])
worksheet.write(row, 4, job['workYear'])
worksheet.write(row, 5, job['education'])
worksheet.write(row, 6, job['firstType'])
worksheet.write(row, 7, job['city'])
worksheet.write(row, 8, job['companyFullName'])
writeExcel(row=0) # 在第一行中写入列名
row = 1 # 从第二行开始写入数据
for page in range(1, 7): # 这里爬取前五页招聘信息做一个示范
for job in getJobList(page=page): # 爬取一页中的每一条招聘信息
# 将爬取到的信息写入表格中
writeExcel(row = row,positionId=job['positionId'], positionName=job['positionName'], salary=job['salary'], createTime=job['createTime'], workYear=job['workYear'],
education=job['education'], firstType=job['firstType'], city=job['city'], companyFullName=job['companyFullName'])
row += 1
print('第 %d 页已经爬取完成' % page)
# 做适当的延时
time.sleep(0.5)
workbook.close() # 关闭表格文件
print(‘爬取的结果在Python职位信息.xlsx中’)
爬取的结果如下:
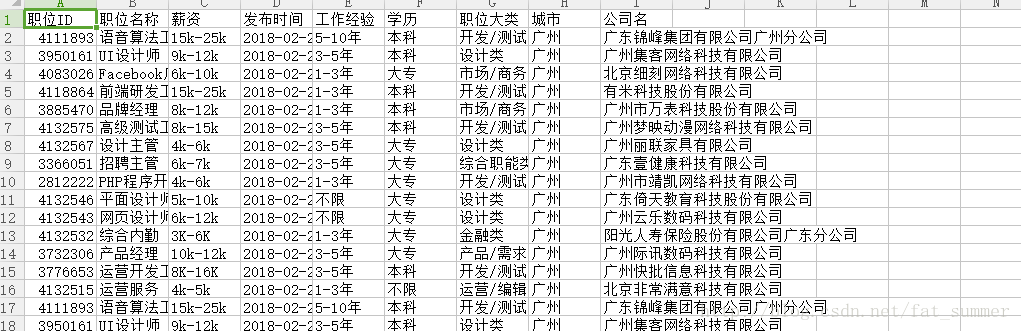
其中,我做的远远不够,代码写的有点乱,只能慢慢一步步来,下次写一遍分析岗位的文章