Python爬取10529条《三十而已》热评,看看大家都说了些啥!
继《隐秘的角落》后,又一部“爆款剧”——《三十而已》获得了口碑收视双丰收,王漫妮、顾佳、钟晓芹三个女主角的故事线频频登上微博热搜。《三十而已》于2020年7月17日在东方卫视首播,并在腾讯视频同步播出。为了了解吃瓜群众们对这部剧的看法,我爬了爬腾讯视频关于这部剧的评论,并做了简单文本可视化分析。
一、数据获取
1.分析评论页面
腾讯视频评论要点击查看更多评论才能加载更多数据,很明显是一个动态网页,评论内容使用了Ajax动态加载技术。因此,我们需要找到真实URL,然后再请求数据。
找到真实URL其实不难,按照以下步骤即可找到。当然,你也可以使用抓包工具fiddler,同样可以轻松找到。
2.寻找参数规律
我们多刷新几次,找几个真实的URL看看这些参数有什么变化。下图是我刷新了3次得到的真实的URL:
第1次刷新:
https://video.coral.qq.com/varticle/5572751505/comment/v2?callback=_varticle5572751505commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6689895369036463828&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1595994099261
第2次刷新:
https://video.coral.qq.com/varticle/5572751505/comment/v2?callback=_varticle5572751505commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6689950633282796870&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1595994099262
第3次刷新:
https://video.coral.qq.com/varticle/5572751505/comment/v2?callback=_varticle5572751505commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6690046095919619518&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1595994099263
很显然,只有cursor=?和_=?有变化,_=?为公差为1的等差数列,而cursor=?貌似没有什么规律。根据以往经验,这类参数有可能藏在上一个真实URL中。我们尝试将第1个URL在浏览器中打开,然后搜索第2个真实URL的中的cursor值。

还真有!一般情况下,我们还要多试几次,对我们的猜想进行验证。既然规律已经找到,接下来就很简单了。限于篇幅,以下给出部分代码:
def main():
#初始页面的_=?
page=1595991084333
#初始待刷新页面的cursor=?
lastId="0"
for i in range(1,1000):
time.sleep(1)
html = get_content(page,lastId)
#获取评论数据
commentlist=get_comment(html)
print("------第"+str(i)+"轮页面评论------")
k = 0
for j in range(1,len(commentlist)):
comment = commentlist[j]
k += 1
print('第%s条评论:%s'%(k,comment))
item = {'comment':comment}
with open('comment.csv', 'a', encoding='utf_8_sig', newline='') as fp:
fieldnames = ['comment']
writer = csv.DictWriter(fp, fieldnames=fieldnames)
writer.writerow(item)
#获取下一轮刷新页ID
lastId=get_lastId(html)
page += 1
if __name__ == '__main__':
main()
# 解决ssl报错
ssl._create_default_https_context = ssl._create_unverified_context
# 构建用户代理
ua = UserAgent(verify_ssl=False)
headers = ("User-Agent", ua.random)
二、数据处理
1.导入相关包
#基础数据分析库
import numpy as np
import pandas as pd
#分词库
import jieba
import re
#绘图库
import matplotlib.pyplot as plt
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import stylecloud
from IPython.display import Image
2.导入评论数据
df = pd.read_csv('/Users/wangjia/Documents/技术公号/公号项目/2.spider/腾讯/comment.csv',names=['评论内容'])
df.sample(5)
| 评论内容 | |
|---|---|
| 4380 | 这都什么年代了你们还看不起弟弟,现实中姐弟恋结婚的也多的是,也很幸福。 |
| 2713 | 这是给90后看的吗 |
| 1541 | 三个女主选的太好,太好 |
| 3765 | 我也是90年 |
| 3853 | 谁都不容易 主要是缺少沟通跟三观对不上 |
数据类型转换
df.info()
df['评论内容'] = df['评论内容'].astype('str')
3.删除重复评论
df = df.drop_duplicates()
4.增加评论类型
cut = lambda x : '短评' if len(x) <= 20 else ('中评' if len(x) <=50 else '长评')
df['评论类型'] = df['评论内容'].map(cut)
5.提取演员关键词
result = []
for i in df['评论内容']:
result.append(re.split('[::,,.。!!~·`\;; ……、]',i))
def actor_comment(df,result):
actors = pd.DataFrame(np.zeros(6 * len(df)).reshape(len(df),6),
columns = ['王漫妮','顾佳','钟晓芹','江疏影','童瑶','毛晓彤'])
for i in range(len(result)):
words = result[i]
for word in words:
if '王漫妮' in word or '王曼妮' in word:
actors.iloc[i]['王漫妮'] = 1
if '顾佳' in word:
actors.iloc[i]['顾佳'] = 1
if '钟晓芹' in word:
actors.iloc[i]['钟晓芹'] = 1
if '江疏影' in word:
actors.iloc[i]['江疏影'] = 1
if '童瑶' in word or '童谣' in word:
actors.iloc[i]['童瑶'] = 1
if '毛晓彤' in word:
actors.iloc[i]['毛晓彤'] = 1
final_result = pd.concat([df,actors],axis = 1)
return final_result
df1 = actor_comment(df,result)
df1.head(10)
| 评论内容 | 评论类型 | 王漫妮 | 顾佳 | 钟晓芹 | 江疏影 | 童瑶 | 毛晓彤 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 自认为三个女主都很好看,演技也棒棒的 | 短评 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 看了二十不惑和三十而已,真的好真实,二十岁的单纯与迷茫,职场小白,啥都不懂,三十岁的圆滑与精... | 长评 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 有多少人是冲着江疏影看此剧的举个手让我看看有多少人! | 中评 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 3 | 有多少20出头的女生来看这剧呢? | 短评 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 三十岁,王漫妮是事业型的奋斗者,顾佳是双商在线型的能力者,钟晓芹是单纯型的嘻嘻哈哈者。抛开现... | 长评 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 5 | 今晚12点过后,我正式步入三十岁,为自己加油! | 中评 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 6 | 我今年32岁,没谈过恋爱!在周围人的眼里我是奇葩!大龄剩女!但我只是想把自己的日子过好!不依... | 长评 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 7 | 真的其实王曼妮配不上梁,和顾佳在一起吧,哈哈 | 中评 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 8 | 为看童瑶而来的 举个手让我看看有多少人 | 短评 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 9 | 我为了童谣 | 短评 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
三、数据可视化
1.整体评论情况
# 定义分词函数
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open("/Users/wangjia/Documents/技术公号/公号项目/3.data_analysis/豆果美食数据分析/stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['', '']
for i in my_words:
jieba.add_word(i)
# 自定义停用词
my_stop_words = ['真的', '看着','有没有','感觉']
stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
# 绘制词云图
text1 = get_cut_words(content_series=df1['评论内容'])
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=1000,
collocations=False,
font_path='演示悠然小楷.ttf',
icon_name='fas fa-heart',
size=653,
palette='matplotlib.Inferno_9',
output_name='./评论.png')
Image(filename='./评论.png')

通过对一万多条热评内容绘制词云图,我们很容易看出大家对《三十而已》的喜欢,以及对主要角色和演员的关注。家庭与工作如何兼得?婚姻与爱情如何共处?这些问题都被广大观众所热议。
2.评论类型分布
df2 = df1.groupby('评论类型')['评论内容'].count()
df2 = df2.sort_values(ascending=False)
regions = df2.index.to_list()
values = df2.to_list()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
.add("", zip(regions,values),radius=["40%", "70%"])
.set_global_opts(title_opts=opts.TitleOpts(title="评论类型占比",subtitle="数据来源:腾讯视频",pos_top="2%",pos_left = 'center'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18))
)
c.render_notebook()

从评论类型来看,以短评居多,占比72.52%。另外,有4.15%的评论者给出了50字以上的评论,表现出自己对《三十而已》的独到见解。
3.演员角色提及
df3 = df1.iloc[:,2:].sum().reset_index().sort_values(0,ascending = True)
df3.columns = ['角色','次数']
df3['占比'] = df3['次数'] / df3['次数'].sum()
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
.add_xaxis(df3['角色'].to_list())
.add_yaxis("",df3['次数'].to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="主演及其饰演的角色被提及次数",subtitle="数据来源:腾讯视频",pos_top="2%",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
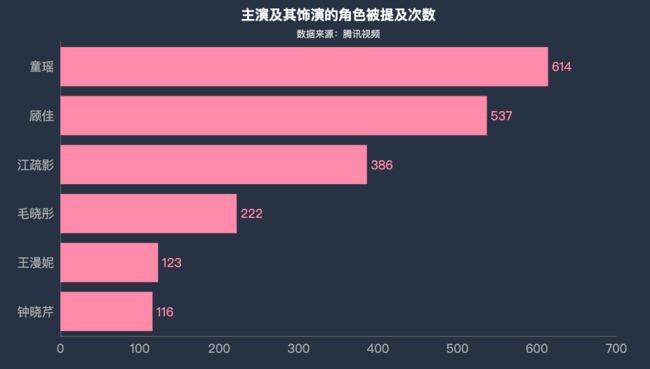
童瑶和顾佳被评论者提及的次数最多,分别为614次和537次。江疏影,作为一名优秀的女演员,她的高人气在众多的评论中可见一斑。王漫妮和钟晓芹提及次数相对少一些,随着剧情的推进应该会有快速的提升。
4.对王漫妮的评论

王漫妮是众人眼中的标准都市女性,大家普遍认为她长得好看又努力上进,甚至有人觉得她是完美的存在。身为柜姐的她需要对顾客进行极致化服务,却遭到现实的嘲讽。感情上,想要好好过日子的她却遇到不该遇到的男人。
5.对顾佳的评论

顾佳作为一名全职太太,在观众看来是个优秀的居家女人。双商在线能力强,将自己的孩子和丈夫的公司都打理得井井有条。与此同时,幸福的生活出现了入侵者,顾佳没有被现实打倒,勇敢应战。另外,顾佳因为长得像章子怡,也被众多观众所提及。
### 5.对钟晓芹的评论

钟晓芹被认为是标准化的大多数,嫁给事业单位铁饭碗的老公,自己保有一份普通工作,安心做一个平凡妻子。却因写作爱好偶然卖出高价版权,夫妻的经济地位和社会地位一夜之间发生倒置,女强男弱的婚姻瞬间失去了平衡,钟晓芹面临抉择。
往期回顾
睡地摊or租房?爬取某大型房产网站24685个房源信息并分析,助你选择
摆地摊or打工,爬取某大型招聘网站3万条招聘信息并分析,作何选择?
实战|Python爬虫并用Flask框架搭建可视化网站
欢迎关注公众号菜J学Python,我们坚持认真写Python基础,幽默写Python实战。你可在公众号后台免费领取相关学习资料或学习交流。
