Python3.5——文件读与写详解(中)
1、(1)文件读操作——读文件的第一行——调用:句柄.readline()
f = open("song",'r',encoding="utf-8")
first_line = f.readline() #读取第一行
print(first_line)
#运行结果:
#take me to your heartf = open("song",'r',encoding="utf-8")
for i in range(5):
print(f.readline().strip())
#运行结果:
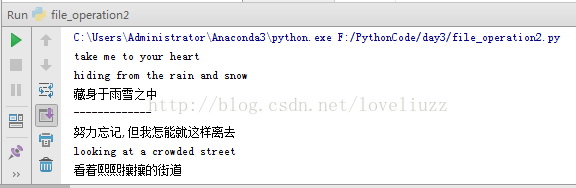
#take me to your heart
#hiding from the rain and snow
#藏身于雨雪之中
#trying to forget but i won't let go
#努力忘记,但我怎能就这样离去f = open("song",'r',encoding="utf-8")
print(f.readlines())![]()
(3)文件读操作——利用句柄.readlines()循环读取文件的内容:
f = open("song",'r',encoding="utf-8")
for line in f.readlines():
print(line.strip())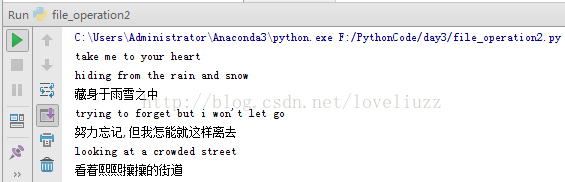
(4)文件读操作——利用句柄.readlines()循环读取文件的内容并处理特殊的行:
f = open("song",'r',encoding="utf-8")
for index,line in enumerate(f.readlines()):
if index == 5:
print("------------")
continue
print(line.strip())
(5)高效读取文件:当文件的内容很大时,采用readlines的方式需要先把文件转换成列表,耗费时间太长,内存里装不下太大的文件。
采用遍历并打印句柄的方式可以高效的实现文件的读取,这种方式采用一行行读取文件方式,内存里面每次只保存一行。
f = open("song",'r',encoding="utf-8")
for line in f:
print(line.strip())运行结果:
(6)高效读取文件——处理特殊行
count = 0
f = open("song",'r',encoding="utf-8")
for line in f:
if count == 3:
print("-------------")
count+=1
continue
print(line.strip())
count += 1