Python爬虫入门——爬取中国大学排名
中国大学排名相关链接:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
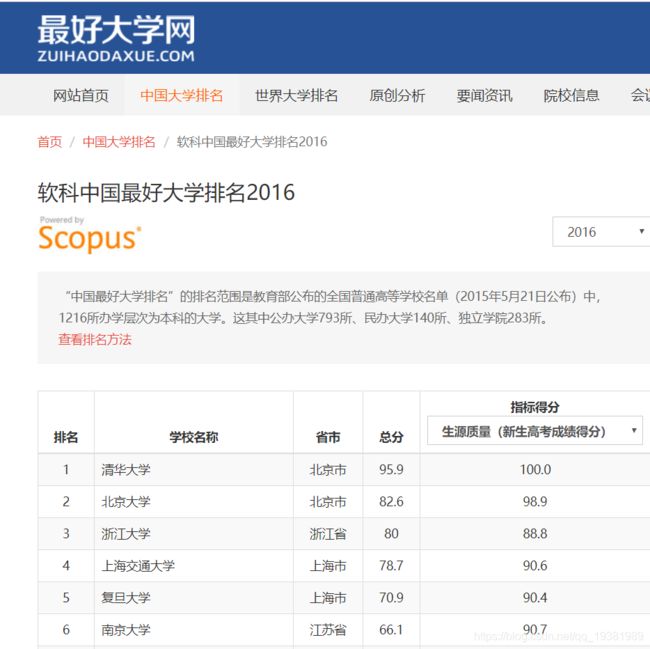
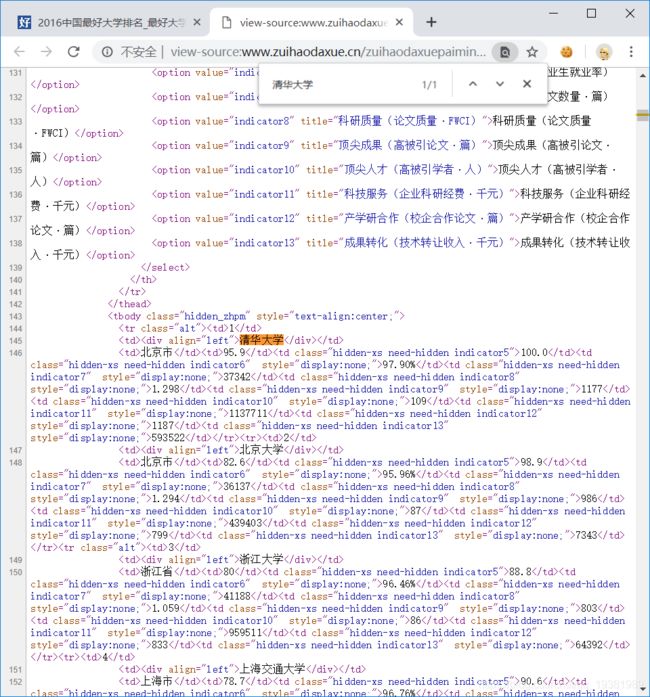
分析源代码得:大学排名的数据都存储于tbody标签下的子标签(关键)
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名", "学校名称", "总分", chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) #二十所学校的排名
main()1- getHTMLText(url)
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
调用requests库 抓取对应网页的内容若正常 则返回网页的代码,否者返回空
2- fillUnivList(ulist, html)
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
调用BeautifulSoup库 整理数据 观察网页源代码可知
数据都存储在tbody标签的子标签td中
用isinstance()方法 检查tbody的子标签是否为 bs4.element.Tag类
并将筛选过的数据通过嵌套的列表保存起来
tds[0]存储排名 tds[1]存储学校名称 tds[2]存储地名 tds[3]存储总分
我们只需要 排名,学校名称,总分 故只将tds[0],tds[1],tds[3]存储为新列表即可
3- printUnivList(ulist, num)
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名", "学校名称", "总分", chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
注意中英文对齐布局问题
chr(12288)是utf-8中 中文空格的编号
大意:间隔全用中文空格就可以避免布局不整齐的问题
Last
通过主函数调用就可以爬取到中国大学的排名了

问题小结
错误代码1
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名", "学校名称", "总分", chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiing2016.html"
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) #二十所学校的排名
main()for tr in soup.find('tbody').children:
在这里出现了traceback
发生异常: AttributeError
'NoneType' object has no attribute 'children'
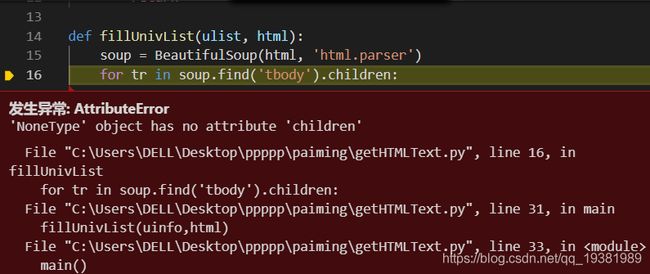
错误代码1:我的网站打错了 更改以后就可以了
错误代码2
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string)
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名", "学校名称", "总分", chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) #二十所学校的排名
main()这段代码在vscode的显示:
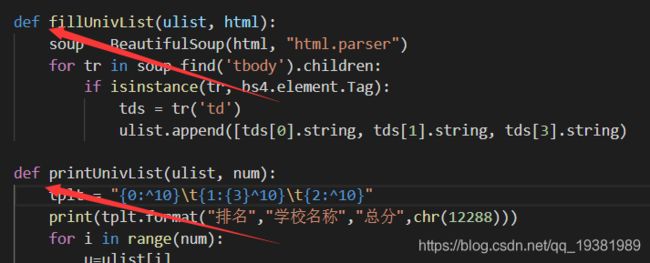
错误代码2:fillUnivList(ulist,html)函数的最后一个tds后少打了一个方括号
总结下来就是打错字了