编译器发展史5个十年3大人物及编译器知识(公号回复“编译器”下载PDF资料,欢迎转发、赞赏、支持科普)
编译器发展史5个十年3大人物及编译器知识(公号回复“编译器”下载PDF资料,欢迎转发、赞赏、支持科普)
原创: 秦陇纪 科学Sciences 今天
科学Sciences导读:继本号操作系统、指令集等计算机科普文章后,接着介绍编译器相关知识。本文按事、人、物的顺序,介绍编译器的发展史、典型人物、技术知识。
编译器发展史5个十年3大人物及编译器知识(25289字)
目录
A编译器发展史5个十年(6864字)
第一个十年
第二个十年
第三个十年
第四个十年
第五个十年
置身于平行世界
B编译器发展史3大人物(12591字)
1.世界首个编译器作者GraceMurray Hopper格蕾丝·穆雷·霍珀
2.编译器优化奠基人JohnCocke约翰·科克
3.矢量化Parafrase编译系统作者DavidJ. Kuck大卫·卡克
C编译器知识(5721字)
1工作原理
2种类(▪处理器▪前端▪后端)
3代码分析
4工作方法
5编译器优化
6进行对比
7历史
参考文献(3832字)
Appx.数据简化DataSimp社区简介(835字)
A编译器发展史5个十年(6864字)
编译器发展史5个十年
文|Michael Wolfe,科学Sciences20181019Fri
作者:自20世纪70年代就读伊利诺伊大学研究生院以来,Michael Wolfe就一直主攻并行计算方面的语言和编译器。在此过程中,他与别人创办Kuck and Associates(已被英特尔收购),在俄勒冈州研究生院(自与俄勒冈健康与科学大学合并以来)投身学术界,并在PGI开发高性能Fortran(PGI先被意法半导体收购,最近被英伟达收购)。如今大部分时间,他在一个为高度并行计算、尤其是为英伟达GPU加速器开发和改进PGI编译器的团队担任技术主管。

如果想了解我们在计算机架构和驱动计算机架构的编译器方面的现状,有必要看看编译器如何在六十年间由一种架构改用另一种架构。
先让目光回到1957年的第一个在IBM 704计算机上实现的编译器IBM Fortran,并首次成功运行了FORTRAN程序。之前在1951年,美国IBM公司约翰·贝克斯(John Backus)针对汇编语言的缺点着手研究开发FORTRAN语言(注1:源自于“公式翻译”的英语FormulaTranslation的缩写)。FORTRAN是世界上最早出现的计算机高级程序设计语言,广泛应用于科学和工程计算领域。如果你看看它的起源和取得的成果,付出的巨大努力是今天的人都无法想象的,这种编程语言是一项了不起的技术。
IBM想要销售计算机,想要销售让更多的人能够进行编程的计算机。当时编程是用汇编语言完成的。这太难了,IBM很清楚这一点。于是蓝色巨人希望人们有办法更快地编写程序,又不牺牲性能。Fortran的开发人员(注2:指发明Fortran的那些人,而不是发明使用编译器和语言的程序的那些人)希望利用如今所谓的高级编程语言编写的程序,提供尽可能接近手动调整的机器代码的性能。
说到编译器,你必须考虑三个P:性能、生产力和可移植性。Fortran的发明者拿机器代码的性能作了比较。生产力方面的好处是,程序员再也不必编写机器代码。我不知道IBM在可移植性方面的最初意图,不过你在1957年无法为软件获得专利权,IBM也没有抱怨其他企业组织实现Fortran。因此没过多久,市面上出现了来自其他供应商的面向其他机器的Fortran编译器。这立即为Fortran程序提供了机器代码无法想象的可移植性。
从这一刻起,编译器开始迅猛发展起来。让我们看看每个十年的情况。
第一个十年
在20世纪60年代(注3:作者出生前),计算机架构师和编译器编写者首先开始考虑并行性。即使那样,人们仍然认为计算机速度不够快,速度提升也不够快,觉得并行性有望解决这个问题。我们看到指令级并行性引入到了Seymour Cray公司的CDC 6600和CDC 7600以及IBM System/360 Model 91中。更为激进的做法是开发出了由伊利诺伊大学的研究人员设计并由Burroughs公司制造的ILLIAC IV、Control Data Corp STAR-100以及德州仪器(TI)Advanced Scientific Computer。CDC和TI的系统是内存到内存的长向量机,而ILLIAC IV是我们今天所说的SIMD机器。(注4:SingleInstruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。)ILLIAC之所以功能有限,是由于没有主要的标量处理器,编程起来确实很难。面向STAR-100的Fortran编译器添加了用于描述长连续向量操作的语法。TI ASC机器最值得关注,因为它拥有第一个自动向量化编译器。TI做了一番了不起的工作,确实提升了当时编译器分析的最新水平。
第二个十年
20世纪70年代,Cray-1成为第一台商业上大获成功的超级计算机。它有众多的跟随者和模仿者,许多读者可能了如指掌。Cray机器的成功很大程度上归功于引入了向量寄存器。就像标量寄存器一样,向量寄存器让程序可以对小小的数据向量执行许多操作,没必要从内存加载和存储到内存。Cray Research还开发了一种非常大胆的向量化编译器。它在许多方面与早期的TI编译器类似,但Cray编译器拥有让它非常备受关注的附加功能。其中最重要的一项功能是能够为程序员提供编译器反馈。
如今开发人员编译程序时,如果程序含有语法错误,编译器将生成出错消息。程序员不断修复这些错误并重新编译,直到拥有一个正常运行的程序。如果开发人员希望程序运行得更快,可以启用编译器优化标志,好让生成的可执行文件运行得更快——他们希望如此。在大多数计算机上,优化代码和非优化代码之间的性能可能相差两倍,通常差异小得多,比如相差10%、20%或者50%。与之相比的是原始Cray机器上可用的向量指令集。在这种情况下,代码被Cray编译器优化和向量化后,程序员常常会看到性能提升5倍到10倍。程序员、尤其是高性能计算(HPC)程序员愿意做大量工作,以便将性能提升5倍或更高。
来自Cray编译器的反馈将告诉程序员它在第110行向量化了一个循环(loop),在第220行向量化了另一个循环,但是没有在第230行向量化循环,原因是第235行有无法被向量化的I/O语句或函数调用。或者,可能存在编译器无法分析的数组引用,或者某个数组的第二个下标中的一个未知变量阻碍了依赖项分析,因此该循环无法进行向量化。想要获得向量性能的Cray程序员格外注意这些消息。他们根据这种反馈修改了代码,可能从循环中取出I/O语句,或者将循环推入到子程序,或者修改数组引用以删除某个未知变量。有时他们会添加一个编译器指令,以便向编译器传达可以安全地进行向量化这一信息,即使编译器无法通过依赖项分析来确定这一点。
多亏了编译器的反馈,发生了三件事。首先,更多的程序被向量化,更多的程序员得益于Cray向量性能。其次,Cray程序员受过了培训,不再将I/O语句、条件语句和过程调用放入到循环的中间。他们明白一个步长(stride)的数据访问很重要,确保内部循环中的数组访问是一个步长。第三,用Cray编译器自动向量化的程序可以在来自Alliant、Convex、Digital、富士通、日立、IBM和NEC的许多类似的向量机上重新编译。所有这些系统都拥有带向量寄存器的向量处理器和自动向量化编译器,之前针对Cray优化的代码在所有这些机器上都可以进行向量化,并很顺畅地运行。简而言之,Cray程序员终于实现了性能、生产力和可移植性这三个目标。
这个编译器反馈有多重要、培训整整一代HPC开发人员为向量机编程有多成功,怎么强调都不为过。每个使用它的人都很高兴。那时候,我还在伊利诺伊大学,我们考虑开一家立足于并行化编译器技术的公司。当然,我们的技术比别人的要好,因为我们是一流的学者。在Cray编译器的早期阶段,用户抱怨编译器无法对任何内容进行向量化,因而不得不重写代码。我们认为自己有望解决这些问题,于是开了这家小公司专门搞这一块。几年后,我们接触同样那样用户、展示我们用于并行化和向量化循环的工具时,他们回复自己不需要这类工具,因为Cray编译器已经向量化了所有循环。倒不是说Cray编译器变得更聪明,不过我确信它会渐渐变得更好。主要是程序员在如何编写可向量化的循环方面训练有素。
第三个十年
20世纪80年代,多处理得到了广泛的实施和使用。早些时候已有多处理器,包括IBM System /370s和Burroughs系统。但是32位单片微处理器的问世推动多处理技术进入了主流。要开一家计算机公司,你不再需要设计处理器——可以径直购买。你没必要编写操作系统,可以购买Unix的许可。只需要有人全部组装起来、贴上铭牌。要是有编译器就好了。Sequent、Encore和SGI都构建了有一个微处理器、性能出色的系统,但如果可以让一批处理器并行运行,那就更好了。
不像大获成功的自动向量化,自动并行化基本上一败涂地。它适用于最内层循环,但要实现大幅的并行加速,通常需要对外层循环进行并行化。不过当然,外层循环增添了控制流的复杂性,常常包括过程调用,现在你的编译器分析完全崩溃了。一种确实可行的方法是,让程序员参与其中,分析并行性,并输入编译器指令来驱动它。我们由此看到了面向并行循环的各种指令集纷纷出现。Cray、Encore、IBM和Sequent都有各自的指令集,唯一的共同点就是SGI采用Sequent指令。同样,许多可扩展的系统要传递网络消息,这促使开发了众多针对特定供应商的、学术性的消息传递库。
第四个十年
20世纪90年代,所有那些消息传递库都被消息传递接口(MPI)取而代之,所有那些针对特定供应商的并行化指令都被OpenMP取而代之。出现了扩展性更强的并行系统,比如Thinking Machines CM-5以及有成千上万个商用微处理器的其他系统。基于微处理器的可扩展系统主要用MPI进行编程,但MPI是一个库,对编译器来说不透明。MPI作为一种编程模型而具有的优点是,虽然通信开销很大,但通信在程序中是完全暴露的。MPI程序员知道何时插入显式通信调用,他们不遗余力地尽可能减少和优化通信。缺点是从编程模型的角度来看,它非常低级,MPI程序员没有得到编译器的帮助。
OpenMP诞生于针对特定供应商的并行指令集百花齐放的时期,因为用户需要它。用户们才不愿仅仅为了能在可供使用的所有不同系统上运行程序而将程序重写12次。OpenMP的整个宗旨就是以同样的方式彰显“并行性可以”。不像MPI,编译器必须支持指令,因为指令是语言的一部分。你无法将OpenMP作为一个库来实现。
同样在20世纪90年代,市面上出现了面向单芯片微处理器的SIMD指令集,比如来自英特尔的SSE和SSE2,我们看到编译器恢复了当时已有20年或25年历史的同样的向量化技术,以便自动利用那些SIMD指令。(注5:同注4的SIMD单指令多数据流)
第五个十年
2000年后不久,众多供应商开始普遍提供多核微处理器。全世界突然意识到必须为大家解决这个并行编程问题。
当时,许多应用程序在一块芯片上的所有核心上以及分布式内存节点上使用扁平的MPI编程模型。你始终可以添加更多的MPI序号(rank)来使用更高的并行性。这一招效果有限,但是你开始获得大量序号时,一些MPI程序会遇到扩展问题。数据在每个MPI序号中复制时,内存使用会有点失控。一旦你开始在每个节点上放置一二十个核心,复制的每一项数据可供使用的内存量是12倍或24倍。如果是为单个节点编程,OpenMP及其他共享内存并行编程模型开始受到追捧。比如在20世纪90年代,英特尔推出了线程构建模块(又名TBB);有人声称,TBB是如今最受欢迎的并行编程语言。
大概在同一时期,异构HPC系统开始出现,不过异构性其实不是新话题。我们在20世纪60年代就遇到了异构性,使用附加的协处理器用于数组处理。附加的处理器大受欢迎,原因是它们可以比CPU更快地完成专门操作。它们常常能够以小型机的价格提供大型机的性能,大约15年来浮点系统在这方面做得很好。在21世纪初期,有几款专门为HPC市场开发或加以改造的加速器,比如ClearSpeed加速器和IBM Cell处理器。这两款产品都取得了一些真正的技术成功,但是HPC市场规模太小,无法支持开发独立的定制处理器芯片。
这给GPU计算留下了缺口。GPU相对定制加速器的优势在于,GPU的主打功能很好——早期的主要任务是图形和游戏,现在还包括AI和深度学习,因此从最新硅片技术和驱动硅片所需的软件方面来看,开发处理器非常高昂的成本维持得下去。
伴随异构性而来的是这个显而易见的问题:我们如何为这些系统编程?早在那时,浮点系统提供了在底层使用加速器的子程序库。程序员调用该库,HPC用户可以高效地使用加速器,无需实际编程(不过有一些程序员进行了编程)。今天,想支持多年来在标量、向量和可扩展系统上开发的众多应用程序,HPC开发人员需要能够为加速器高效地编程,他们希望程序看起来尽可能正常。使用OpenCL或CUDA可以为你提供了很强的控制性,但是对于现有HPC源代码的影响可能非常大。程序员通常将有待在加速器上运行的代码提取到特别注释的函数中,而且编写的方式常常与为主机编写的方式全然不同。这时候,专门为通用并行编程设计的基于指令的编程模型和语言就有一些优势,而优秀的优化编译器大有用场。
置身于平行世界
这给我们引出了另一个至关重要的方面。20世纪60年代为指令级并行性开发的所有技术现在都在微处理器里面。20世纪70年代的向量处理概念存在于微处理器里面的SIMD寄存器中。20世纪80年代Cray和基于商用处理器的系统的多个处理器都以多个核心的形式存在于微处理器里面。今天的微处理器可以说整合了过去50年来所做的全部架构工作,而由于我们现在拥有出色的晶体管技术(数十亿个门),我们可以这么做。另外我们现在还有异构性;在一些情况下,我们甚至可以在同一块芯片上做到异构性。比如说,中国太湖之光系统中的“神威”芯片从封装的角度来看是一块芯片,但芯片上每个四分之一的部分都包括一个主处理器和64个计算处理器。因此,它基本上是异构的,编程起来更像是CPU-GPU混合体,而不是像多核处理器。
为了充分利用异构的GPU加速节点,程序需要具有很强的并行性,而且是类型合适的并行性。这些高度并行处理器不是通过更快的时钟提供性能,不是由于某种异常奇特的架构。确切地说,那是由于更多的可用门用于并行核心,而这些并行核心用于缓存、乱序执行或分支预测。商用CPU的所有那些主要任务被排除在GPU之外,结果是大规模并行处理器在合适的内核和应用程序上提供更高的吞吐量。
这让我们回到了三个P,而性能不是HPC开发人员的唯一目标。程序员需要高性能、良好的生产力和广泛的可移植性。大多数程序员希望程序只编写一次,而不是多次。
在当时只有节点上的单处理器、所有并行性横跨节点的时期,程序员可以使用扁平的MPI来应付。这类程序可在一系列广泛的机器上顺畅运行,但这不再是我们现在所置身的HPC环境。我们在一个节点中有多个处理器,有SIMD指令,还有异构加速器,引入了更多类型的并行性。为了获得可移植性,我们需要能够编写针对不同数量的核心、不同的SIMD或向量长度可以高效映射的程序,以及同构或异构的系统,没必要每次改用新系统就要重写程序。为了确保生产力,我们需要把其中尽可能多的部分抽取出来。我们使用编译器为今天的HPC系统试图做到的是与IBM在六十年前使用第一个Fortran编译器做到同样的抽象质量,后者实际上是第一种任何类型的高级语言编译器。
目标是在如今极其复杂的硬件上获得尽可能接近手动编程的性能。今天,就小小的简单代码块而言,针对英伟达GPU的PGI OpenACC编译器常常可以提供接近原生CUDA的性能。对于像大型函数这种更复杂的代码序列,或者整批调用树被移植到GPU时,接近原生代码性能要困难得多。
客观地说,OpenACC编译器天生处于劣势。在CUDA中重写代码时,程序员可能查明某个数据结构不适合GPU,可能改变数据结构以增强并行性或性能。也许程序员查明程序逻辑的一部分不是很适合GPU,或者查明数据访问模式并不理想,因此重写该逻辑或循环以改进数据访问模式。如果你在对应的OpenACC程序中进行同样这些更改,常常也会获得好得多的性能。但是你最好不这么做,如果重写减慢了多核CPU上代码的运行速度,更是如此。因此,OpenACC代码可能无法获得与你花了这番编程工作量同样的性能级别。即便如此,如果OpenACC代码的性能足够接近GPU上的CUDA,基于指令的编程模型在生产力和可移植性方面的好处常常很明显。
尽管过去的60年间我们在编译器技术方面取得了诸多进展,但一些人仍然认为编译器与其说是解决办法,还不如说是问题。他们想要的是来自编译器的可预测性,而不是在后台优化编译器的高级分析和代码转换。这可能引出了这条道路:我们尝试从编译器中获取功能,将更多的责任交到程序员的手里。有人会说,这正是OpenMP今天所走的道路;我看到的危险是,我们到头来可能为了可预测性而牺牲了可移植性和生产力。比如说,设想你仍然得使用英特尔的SSE和AVX内部函数,对每个循环进行手动向量化,而不是针对英特尔至强处理器上的SIMD指令进行自动向量化。你实际上在编写内联汇编代码。这具有很强的可预测性,但很少有程序员想要在该层面编写所有的计算密集型代码,你要为每一代SIMD指令重写代码,或者在非X86 CPU上使用SIMD指令时更是如此。
计算机架构方面任何合理的进步都伴随编译器技术方面合理的进步。不能仅用那些架构和编译器所提供的性能来衡量好处,还要用程序从一代HPC系统移植到下一代(不必完全重写)后,节省的人力和提高的生产力来衡量。
B编译器发展史3大人物(12591字)
编译器发展史3大人物
文|秦陇纪,科学Sciences20181107Wed1118Sun
写出一个操作系统,还是写出一个编译器的程序员,哪个更厉害?
一般人可能会想,虽然没写过编译器,但应该写操作系统比编译器要简单多了。
非也!讲操作系统实现的书很多,但讲编译器或调试器实现的则极少,参考资料很难找。多年从事开发的程序员,如果需要写操作系统(类Linux等简单的),花一定时间能做成;但要写个编译器或调试器,则可能束手无策。写编译器难在词法分析、语法分析、逻辑分析、嵌套分解、优化算法、CPU二进制码对应等,是真正的计算机科学。完全从源码分析,如GDB源码,会让人看不下去而崩溃放弃,更不要说GCC之类的源码,极其枯燥、抽象、难梳理。事实上,编译器是与CPU架构一起发展的,从基础的“程序-指令”体系不断演进越来越复杂。识字读书思考的伪专家编写的CS、EE、IT专业教科书,基本都是碎片化表达的语文知识,缺乏科学性理论和技术演进过程。这方面的差距不是一天两天是事,而是长期以来外行领导专业领域、不注重科学理论和工程实践造成的。
这里,秦陇纪整理维基百科、百度百科、IT网站等公开资料,列举3名经典编译器作者、奠基人,他们无不具备坚实的数学、逻辑功底。未来再整理其他计算机语言相关的编译器。
1.世界首个编译器作者Grace Murray Hopper格蕾丝·穆雷·霍珀
世界上第一位程序员是女性;世界上第一个编译器也是女性开发的!下面介绍开发世界上第一个编译器的女牛人:Grace Murray Hopper格蕾丝·穆雷·霍珀。
1.1 启蒙
格蕾丝·霍珀Grace Hopper(1906–1992)本姓穆雷Murray,Hopper为夫姓。1906年12月9日生于美国纽约一个海军世家,其祖父军衔曾达少将。她的外祖父则是一名高级土木工程师,常带她去上班,她也十分高兴地帮着扶红白相间的测量杆,这培养了她对于几何学和数学的兴趣。Grace的父亲因患动脉硬化导致双腿截肢,长期住院,这使得作为长女的她从小就更加懂事和勤奋。
Grace回忆她小时候最喜欢上的课是数学课,特别是几何课。因为在几何课上,她可以把铅笔盒里所有彩色的笔全部拿出来用。虽然她是个女孩子,可是各种量角器、计算尺她都喜欢拿来玩,研究它们的原理和作用。她还做过一些很像男孩子做的事情:她曾经在六、七岁的时候,把家里所有的钟都拆开,但是没有一个成功装回去,因此还受到了严厉的处罚。
1.2 教育
进入大学前,Grace就读于私立Wardlaw-Hartridge学校。1928年她大学毕业于瓦萨学院(Vassar College)并取得数学和物理的双学士学位,在校期间是美国资优学生联谊会(Phi-Beta-Kappa Society)成员(PBK是一个有着两百多年历史、很好很强大的学生社团,成员如老布什、克林顿、厄普代克)。随后去耶鲁大学(Yale University)攻读数学硕士,1930年获硕士学位。1930年6月15日她与VincentFoster Hopper结婚(注1:Vincent是纽约大学英文系教授,1945年过世,Hopper与她没有生育子女)。
结婚没多久,Grace就决定攻读博士。她一边教书一边在耶鲁大学进修博士学位,并在1934年取得博士学位,前后只花了四年时间,这算是相当快的。博士论文题为《代数方程可约的一个新准则》(A NewCriterion for Reducibility of Algebraic Equations),但是让许多人惊奇的是,她是用几何方法证明这个准则的。

作为女性,获得数学博士学位是一个很大的成就,因为在数学上取得成就而获得博士学位本身就很困难。据统计,从1862-1934年间,全美总共授予1279个博士学位,平均每年不到18个,而女性获得数学博士学位更是凤毛麟角。在求职方面,女数学家通常只能到高中教课,极难上大学讲台。但Grace做到了,硕士毕业后被母校瓦萨学院聘任,短短几年就从助教升到副教授。不过,到这个阶段为止,我们还看不出来她会跟计算机产生任何关系。
1.3 转折
1941年是Grace人生的转折点。珍珠港事件后,Grace有了从军念头,她想加入海军。当时女性从军都是做后备军人,大部分都是护士,要不然就是做后勤。如果是受过高等教育的女性,就会被分配去做有关计算的工作。由于家族传统,她选择参加海军的WAVES组织(Women Accepted forVoluntary Emergency Service)。
在马萨诸塞州北安普敦(Northampton, MA)海军军官学校接受培训后,她被授予上尉军衔。考虑到她的数学背景,她被派到哈佛大学著名计算机专家霍德·艾肯Howard Aiken(1900-1973)教授手下参与Mark I研制工作。Aiken教授是1939年哈佛物理博士,是Mark I、II、III、IV一系列电机计算机的设计及制造者。(注2:Mark I原来叫ASCC(Automatic Sequence Controlled Calculator),由哈佛大学与IBM合资建造,完成于1943年,重35吨,内部线路长达500英里。但在1944年Mark I启用典礼之后,IBM和哈佛就闹翻了,原因是哈佛认为IBM只是个出钱的财主,主要的智力贡献是哈佛人的功劳,IBM认为自己也在工程上做了许多研究和创新,而哈佛却认为那些工程上的创新都不值一提。所以IBM就从哈佛的Mark计划中退出。后来的十年间,IBM在学术界的主要合作伙伴,变成了哥伦比亚大学。)
Grace从小就喜欢各种计算尺,当她走进哈佛的计算工厂见到这台电机计算机时,她说这是她看过最有趣的计算尺。在她之前,有两名男工程师在Mark上写过程序,这两个男士帮助Grace在三天之内写出了她的第一个程序。所以算起来,Grace是世界上第三个在电机计算机上写程序的人。
1.4 荣耀
1945年9月9日,发生了一件对计算机界而言非常重要的轶事。那天的天气很热,工作人员把窗户都打开了,后来有一只蛾飞了进来,结果那只蛾死在一只继电器里面,造成电路不通,机器死机,他们没办法算出他们要的结果。经过了近一天的检查,Grace找到了那只蛾,她设法用她的发夹把那只蛾弄了出来,还把那只蛾的尸体贴在她的管理日志上,上面写道:“就是这个Bug,害我们今天的工作无法完成。”这个消息传开之后,那个实验室里的人每逢老板询问为何还没做出结果时,都把过错推给Bug。尔后,”bug”(小虫)和”debug”(除虫)这两个本来普普通通的词汇,成了计算机领域中特指莫明其妙的“错误”和“排除错误”的专用词汇流传至今。

Grace对计算机界的贡献相当多,Bug这个名词的引用,其实只算是一个小小的插曲。
她对计算机的最大贡献是发明了世界上第一个编译器(Compiler),名字叫做A-0。当时没有任何组合语言及程序语言存在,所有的程序设计人员都要把程序翻译成机器码,即“0011000101011”这样的形式,在纸上打孔,再送到机器里去读。Grace进入Eckert-Mauchley公司后产生一种想法,想设计一种程序,让人可以用类似英文的语法,把想做的事写下来,然后用这个程序把英文翻译成机器的语法,交给机器去执行。这个想法就是今日的Compiler(编译器)。
当初她提出这样的构想时,众人皆曰不可。所有人都告诉她计算机只能做计算,只能处理数字,计算机是不懂英文的。在50年代,大部分人都尚未意识到计算机是用来处理信息的工具,所有的人就认为计算机只是个计算器而已。
Grace Hopper可能是第一个想到这个问题并且有机会做下去的人。尔后,她就到处去演讲以筹集资金来做这项计划。这段期间,有很多朋友问她:“你怎么这么勇敢呢?万一搞砸了,你该怎么办?”Grace回答道:“It isalways easier to ask forgiveness than it is to get permission.”(以后要道歉,比现在要拿到钱简单多了。)这句话后来成为她一生中的至理名言之一。
当初在写世界上第一个编译器A-0时,为了向能出钱的老板炫耀,Grace还设计了三个版本:英文版、德文版、法文版,表明编译器不仅看得懂英文,也看得懂德文跟法文。但后来德文版和法文版的编译器都没再做下去。到1956年,她开发出来一套很完整的程序语言,叫做FLOW-MATIC。
海军采用了这套系统(这时Grace还是海军的一员)。因为海军幅员广大,如果各地自行稍加将编译器修改一小部分,就会发生A地的程序在B地无法执行的问题。于是Grace写了一套程序,用来检查这些程序之间是不是采用同样的编译方式,称作Validation。后来影响到民间,渐渐发展出一套新的语言,偏向于商业使用的语法,这套程序语言就是著名的COBOL(Common BusinessOriented Language)。这也是Grace Hopper对计算机界的第二个重大贡献。
那个年代,总共只有三种程序语言:COBOL、ART、FORTRAN(IBM的产品)。有人把Grace叫做“COBOL之母”,这个称号虽然被学术界的某些人所反对(因为她没有直接参COBOL语言的设计工作),但她对COBOL的形成与发展所起的重大作用却是世人一致公认的。据20世纪80年代初的统计,全美在运行中的程序有80%是用COBOL语言编写的,由此可见COBOL语言对计算机应用发展所起的作用。1971年,为了纪念现代数字计算机诞生25周年,美国计算机学会特别设立了“格蕾丝·霍珀奖”,颁发给每年最优秀的30岁以下的青年计算机工作者,因此,“霍珀奖”也是全球电脑界“少年英雄”的标志。1980年,霍珀获得国际IEEE组织颁发的首届计算机先驱奖。
1.5 后记
Grace Hopper是个非常amazing的人(常被称为AmazingGrace),崇拜她的人相当多。虽然她的事迹很多,但是还有很多有类似事迹的人并没有像她这样受到众人的崇拜。由其中一点我们可以看出来:从1947年开始(二战结束第二年),她获得第一个荣誉博士学位(宾州大学)以后,她先后被40多所大学授予荣誉博士学位,其中包括芝加哥大学、华盛顿大学、马里兰大学等知名学府。
各种妇女社会团体和学术组织都曾授予Grace各种称号和奖励。1991年,布什总统在白宫授予她的“美国国家技术奖”(National Medal of Technology)是其中的最高奖项,她也是至今惟一获此殊荣的美国女性。她的名言有很多,她自己最喜欢的,也是她最喜欢对所谓的“年轻人”说的(在她年老时,她所谓的年轻人就是“年龄不到我的一半的人就叫做年轻人”),这句话是:“A ship in port is safe, but that is not what ships are builtfor.”(船舶入港安全,但这不是造船目的。)

1992年1月7日,华盛顿阿灵顿国家公墓,美国海军为在元旦凌晨睡梦中安然去世的退休海军女军官格蕾丝·穆雷·霍珀(Grace Murray Hopper)举行了隆重的葬礼。海军仪仗队和众多肃穆的海军官兵按照海军的礼仪向这位令人尊敬的长者作最后的告别。千千万万的美国人则通过电视转播观看了葬礼的实况。格蕾丝·霍珀珍惜生命,她希望能够活到94岁新世纪来临那天,却未能如愿。
四年后的1996年1月6日,美国海军在缅因州的巴斯港(Bath, Maine)为它新建造的一艘阿利·伯克级驱逐舰举行了隆重的命名仪式,把它命名为“霍珀号”。这是第二次世界大战以后第一次、整个美国海军历史上第二次以一位女性的名字命名一艘战舰。
2.编译器优化奠基人John Cocke约翰·科克
RISC(Reduced InstructionSet Computer精简指令系统计算机)架构设计师JohnCocke约翰·科克,1972年获得IBM公司颁赠给内部员工的最高荣誉称号“IBM小子”,同年还获得了美国国家技术勋章和图灵奖。1991年,老布什总统亲自授予他国家科学奖(国家技术勋章和国家科学奖是美国最具荣耀的两项政府大奖)。作为科学家的一生中,Cocke在高性能系统设计中取得的革命性进步,为信息技术的发展做出独一无二的创造性贡献。在系统架构和编译器优化研究领域取得了大量进步,他当之无愧地成为编译器优化的奠基人和革新带头人。
约翰·科克John Cocke,1925年,出生于北卡罗莱那州(North Carolina)的夏洛特(Charlotte)。他是从机械到数学、又从数学转到计算机方向上来的学者。1946年,杜克大学(Duke University)先后取得机械工程学士学位和硕士证书,干了几年实际工作以后,他又回到母校读研究生,于1956年取得数学博士学位。第二年,他加盟IBM公司直到退休。在IBM开始了他的计算机生涯并为IBM计算机市场的开拓和计算机科学技术的发展,尤其是RISC架构和编译器优化[11],做出了巨大贡献。

中文名:约翰·科克,外文名:John Cocke,国籍:美国,出生地:美国北卡罗来纳州夏洛特,出生日期:1925年,职业:IBM老资格的研究员,计算机科学家,毕业院校:杜克大学,主要成就:RISC架构之父、ACM图灵奖(1987)[12],IEEE约翰·冯诺依曼奖(1994)[13],美国国家科学奖章(1994)[14],代表作品:《各种变换的优化方法》(A Catalogof Optimizing Transformations)。
2.1 学术生涯
他的计算机生涯始于IBM,在计算机市场开拓和计算机科学技术发展均做出巨大贡献。由于学过机械和数学,基础扎实、知识面广,加上科克兴趣广泛,善于动脑,他在IBM许多产品的设计开发和技术问题的解决中都起过至关重要的作用,有众多的发明创造。在沃特森研究中心,在很长一段时间里,每当人们有疑难问题需要解决的时候,自然就会说:“找约翰讨论去”。事实上,科克也总能提出有益的建议,因而受到其同事的普遍敬仰和尊重[11]。
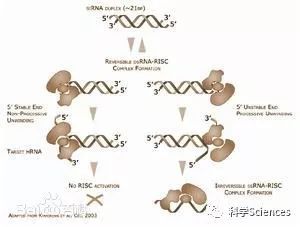
Cocke在IBM公司从事的第一个项目是研究Stretch计算机(世界上第一个“超级计算机”型号),他很快成为大型机专家。1974年,Cocke和他领导的研究小组开始尝试研发每秒能够处理300线呼叫的电话交换网络。为了实现这个目标,他不得不寻找一种办法来提高交换系统已有架构的交换率。1975年,Cocke研究IBM370的CISC(ComplexInstruction Set Computing复杂指令集计算)系统,发现占总指令数20%的简单指令发出了80%程序调用,而占总指令数80%的复杂指令却只有20%的机会被用到。由此,他提出了RISC概念,其中心思想就是简化硬件设计,硬件只执行一部分很有限的最常用的指令,大部分复杂的操作则使用成熟的编译技术,由简单指令合成。RISC的最大特点是指令长度固定,指令格式种类少,寻址方式种类少,大多数是简单指令且都能在一个时钟周期内完成,易于设计超标量与流水线,寄存器数量多,大量操作在寄存器之间进行。
1980年,Cocke在IBM位于约克城(Yorktown)的华生研究中心(Watson Research Center)里开始研制IBM801(PowerPC前身),首台RISC机器就作为801微电脑项目的一部分最终开发成功。RISC技术推出以来,由于其优化指令系统带来运算速度提高的优势,使得RISC技术在1980年代后期,逐渐在高端服务器和工作站领域中取代了CISC成为主流微处理器设计架构之一。各个具备一定技术实力的厂家开始在这个架构上研发出自己的处理器,经过近二十年的发展,各大型计算机和超级服务器都采用RISC架构的处理器。现在,RISC处理器已经成为高性能计算机的代名词。

RISC模型
2.2 贡献成就
科克的贡献和成就首先是在高性能计算机的体系结构方面。科克是60年代IBM推出的晶体管大型计算机,也是世界上第一个“超级计算机”(Supercomputer)型号STRETCH的技术负责人。Stretch包含15万只晶体管,其速度比IBM上一个主流计算机型号IBM704快75倍。STRETCH首创的灵活的寻址技术、指令提前执行(即流水线技术)、差错校正码ECC(Error Correcting Code)等至今仍被广泛使用着。Stretch共生产了8台,被洛斯阿拉莫斯(Los Alamos)国家实验室(这是研制出了世界上第一颗原子弹的著名的原子能研究中心)等机构所采用。
模型
70年代中期,科克又主持了一个801计算机项目。(注3:或叫“80号大楼”项目,这是IBM的传统,按研制小组所在建筑物命名项目) 801计算机原是为每小时能处理100万次呼叫的全数字电话交换机设计的专用机,但实现中被发展为一种具有小指令集、每个指令都是单地址、有固定格式、以流水线方式重叠执行、指令高速缓存和数据高速缓存则分开并互相独立的一种超级通用小型机。IBM推出这种体系结构引起加州大学伯克利分校D.Patterson和斯坦福大学J.Hennessy的极大兴趣和重视,经过进一步研究、改进和发展,最后形成为一种崭新的计算机体系结构,即大家熟知的“精简指令集计算机”RISC(ReducedInstruction Set Computer)。因此,RISC这个名词虽然是1980年由Patterson提出的,但学术界公认科克是RISC概念的首创者。
除计算机体系结构外,科克在编译器优化方面有很多重要贡献。高级语言编译器发展的初期,技术上不够成熟,生成的目标代码大,执行效率低,影响了高级语言的推广应用。科克对编译器的代码生成技术进行了深入研究,提出了一系列优化方法,如过程(Procedure)的集成、循环(loop)的变换、公共子表达式(common subexpression)的消除、代码移动(code motion)、寄存器定位、存储单元重用等,编译器质量大大提高,使编译技术发展到一个新阶段。科克在其主编的《各种变换的优化方法》(A Catalogof Optimizing Transformations, Prentice Hall, 1972)中详细介绍了这些方法。
此外,科克在磁记录技术、机器翻译的统计方法等方面也都有过创造和发明。
在获得图灵奖以前,科克于1985年获得过ACM的另一个奖项:Eckert Mauchly奖。这个奖是1979年纪念世界上第一台电子计算机ENIAC的两位设计者而设立的,主要用来奖励在计算机体系结构方面作出杰出贡献的科学家。1991年,科克又荣获美国全国性的国家技术创新奖章“National Medal of Technology”。
不知什么原因,科克没有出席图灵奖颁奖仪式,由他的同事A.Peled代为领奖并致词。但科克发表题为“对科学处理器性能的探索”(Thesearch for Performance in Scientific Processors)的书面图灵奖演说,回顾了他一生追求高性能计算机的历程,认为对计算机性能影响最大的三个因素是算法、编译器和机器组织。虽然他本人从事机器组织和编译器方面研究工作,但他认为,这三者中,算法改进是最重要的。Peled致词和科克书面演说全文在《Communicationsof ACM》1988年3月号刊载。
2.3 荣誉
“IBM小子”是RISC(Reduced InstructionSet Computer,精简指令系统计算机)架构设计师——JohnCocke,在1972年得到的IBM公司颁赠给内部员工的最高荣誉称号。

约翰·科克
在IBM以外,他也受到广泛的认可,获得无数奖项,其中代表性的有:
ACM图灵奖(1987)[12]
IEEE计算机先驱奖(1989)[15]
美国国家技术奖章(1991)[16]
美国国家科学奖章(1994)[14]
IEEE约翰·冯诺依曼奖(1994)[13]
国家技术勋章和国家科学奖是美国最具荣耀的两项政府大奖,在作为科学家的一生中,他在高性能系统设计中取得的革命性进步,Cocke为信息技术的发展做出了独一无二的创造性贡献。在系统架构和编译器优化研究领域取得了大量进步,当之无愧地成为编译器优化的奠基人和革新带头人。
2.4 评价
“从1957到1992年,John Cocke在工作中把自己近40年的精力毫无保留地奉献给了IBM,他取得了了不起(amazing)的成绩”,Cocke的同事兼密友Peter Capek这样评价他:“他的经历非同一般。他因为计算机架构而闻名,但他对很多领域同样充满浓厚兴趣。包括逻辑模拟(logicsimulation)、编码理论(coding theory)和编译器优化(compiler optimization),他都可以把这些技术当成艺术来研究。”Cocke退休后还依然为IBM公司发挥余热,直到2002年7月16日病故。
2.5 关于RISC
简介
RISC(reduced instruction set computer精简指令集计算机)是一种执行较少类型计算机指令的微处理器,起源于80年代MIPS主机(即RISC机),RISC机中采用的微处理器统称RISC处理器。这样一来,能够以更快的速度执行操作(每秒执行更多百万条指令MIPS)。因为计算机执行每个指令类型都需要额外的晶体管和电路元件,计算机指令集越大就会使微处理器更复杂,执行操作也会更慢。

RISC&CISC
纽约约克镇IBM研究中心的JohnCocke证明,计算机中约20%的指令承担了80%的工作,于1974年,他提出RISC的概念。第一台得益于这个发现的电脑是1980年IBM的PC/XT。再后来,IBM的RISCSystem/6000也使用了这个思想。RISC这个词本身属于伯克利加利福尼亚大学的一个教师David Patterson。RISC这个概念还被用在Sun公司的SPARC微处理器中,并促成了现在所谓的MIPS技术的建立,它是Silicon Graphics的一部分。许多当前的微芯片现在都使用RISC概念。
RISC概念已经引领了微处理器设计的一个更深层次的思索。设计中必须考虑到:指令应该如何较好的映射到微处理器的时钟速度上(理想情况下,一条指令应在一个时钟周期内执行完);体系结构需要多“简单”;以及在不诉诸于软件的帮助下,微芯片本身能做多少工作等等。
除了性能的改进,RISC的一些优点以及相关的设计改进还有:
@如果一个新的微处理器其目标之一是不那么复杂,那么其开发与测试将会更快。
@使用微处理器指令的操作系统及应用程序的程序员将会发现,使用更小指令集使得代码开发变得更加容易。
@RISC的简单使得在选择如何使用微处理器上的空间时拥有更多的自由。
@比起从前,高级语言编译器能产生更有效的代码,因为编译器使用RISC机器上的更小的指令集。
除了RISC,任何全指令集计算机都使用的是复杂指令集计算(CISC)。RISC典型范例如:MIPSR3000、HP—PA8000系列,MotorolaM88000等均属于RISC微处理器。
主要特点
RISC微处理器不仅精简了指令系统,采用超标量和超流水线结构;它们的指令数目只有几十条,却大大增强了并行处理能力。如:1987年SunMicrosystem公司推出的SPARC芯片就是一种超标量结构的RISC处理器。而SGI公司推出的MIPS处理器则采用超流水线结构,这些RISC处理器在构建并行精简指令系统多处理机中起着核心的作用。
RISC处理器是当今UNIX领域64位多处理机的主流芯片
性能特点一:由于指令集简化后,流水线以及常用指令均可用硬件执行;
性能特点二:采用大量的寄存器,使大部分指令操作都在寄存器之间进行,提高了处理速度;
性能特点三:采用缓存—主机—外存三级存储结构,使取数与存数指令分开执行,使处理器可以完成尽可能多的工作,且不因从存储器存取信息而放慢处理速度。
1、应用特点:由于RISC处理器指令简单、采用硬布线控制逻辑、处理能力强、速度快,世界上绝大部分UNIX工作站和服务器厂商均采用RISC芯片作CPU用。如原DEC的Alpha21364、IBM的PowerPCG4、HP的PA—8900、SGI的R12000A和SUNMicrosystem公司的UltraSPARC-II。
2、运行特点:RISC芯片的工作频率一般在400MHZ数量级。时钟频率低,功率消耗少,温升也少,机器不易发生故障和老化,提高了系统的可靠性。单一指令周期容纳多部并行操作。在RISC微处理器发展过程中。曾产生了超长指令字(VLIW)微处理器,它使用非常长的指令组合,把许多条指令连在一起,以能并行执行。VLIW处理器的基本模型是标量代码的执行模型,使每个机器周期内有多个操作。有些RISC处理器中也采用少数VLIW指令来提高处理速度。
RISC和CISC区别
RISC和CISC是目前设计制造微处理器的两种典型技术,虽然它们都是试图在体系结构、操作运行、软件硬件、编译时间和运行时间等诸多因素中做出某种平衡,以求达到高效的目的,但采用的方法不同,因此,在很多方面差异很大,它们主要有:
(1)指令系统:RISC设计者把主要精力放在那些经常使用的指令上,尽量使它们具有简单高效的特色。对不常用的功能,常通过组合指令来完成。因此,在RISC机器上实现特殊功能时,效率可能较低。但可以利用流水技术和超标量技术加以改进和弥补。而CISC计算机的指令系统比较丰富,有专用指令来完成特定的功能。因此,处理特殊任务效率较高。
(2)存储器操作:RISC对存储器操作有限制,使控制简单化;而CISC机器的存储器操作指令多,操作直接。
(3)程序:RISC汇编语言程序一般需要较大的内存空间,实现特殊功能时程序复杂,不易设计;而CISC汇编语言程序编程相对简单,科学计算及复杂操作的程序社设计相对容易,效率较高。
(4)中断:RISC机器在一条指令执行的适当地方可响应中断;而CISC机器在一条指令执行结束后响应中断。
(5)CPU:RISCCPU包含有较少的单元电路,因而面积小、功耗低;而CISCCPU包含有丰富的电路单元,因而功能强、面积大、功耗大。
(6)设计周期:RISC微处理器结构简单,布局紧凑,设计周期短,且易于采用最新技术;CISC微处理器结构复杂,设计周期长。
(7)用户使用:RISC微处理器结构简单,指令规整,性能容易把握,易学易用;CISC微处理器结构复杂,功能强大,实现特殊功能容易。
(8)应用范围:由于RISC指令系统的确定与特定的应用领域有关,故RISC机器更适合于专用机;而CISC机器则更适合于通用机。[17]
词条标签:非教师,行业人物,教师,人物。词条统计:浏览11252次,编辑16次历史版本,最近更新:w_ou(2018-08-11)。[17]
3.矢量化Parafrase编译系统作者David J. Kuck大卫·卡克
大卫·卡克David J. Kuck,密西根大学(Universityof Michigan)研究生毕业。(注4:奥运会银牌得主Jonathan Kuck的父亲) 1965年至1993年,他是伊利诺伊大学厄本那-香槟分校计算机科学系(Computer Science Department the University of Illinois at Urbana-Champaign)教授,开发了Parafrase编译系统(1977)——自动矢量化和相关程序转换(automaticvectorization and related programtransformations)开发的第一个测试平台。作为超级计算研究与开发中心(CSRD-UIUC, Center for Supercomputing Research andDevelopment)主任(1986-93),Kuck领导了CEDAR项目的建设——1988年在伊利诺伊大学完成的分层共享内存32处理器SMP超级计算机(a hierarchicalshared-memory 32-processor SMP supercomputer)。[19]
1979年,他创建Kuck and Associates(KAI)公司,以构建一系列行业标准的优化编译器(aline of industry-standard optimizing compilers),专注于利用并行性(parallelism)。在CSRD之后,Kuck将他的全部注意力转移到KAI及其在美国国家实验室(US National Laboratories)的客户身上。KAI于2000年3月被英特尔收购,Kuck目前在英特尔研究员、软件和服务组(SSG, an IntelFellow, Software and ServicesGroup),开发人员产品部(DPD, Developer Products Division)任职。
与所有其他面向硬件的成员相比,Kuck是ILLIACIV项目中唯一的软件人员。Kuck不仅负责开发许多关于如何重新构建计算机源代码以实现并行性的初步想法,而且还负责培训该领域许多该领域的主要参与者。
3.1 杰出博士论文奖Outstanding PhD Thesis Award
Kuck是1965-1993年的计算机科学教授。1977年,他开发了Parafrase编译系统,该系统被用作开发关于矢量化和程序转换的许多新想法的试验台。他于1985年领导了Cedar的建设,这是一台在伊利诺伊州建造的32处理器SMP超级计算机。他是Kuck and Associates的创始人,并获得了无数奖项,包括ACM/IEEE的Eckert-Mauchly奖,IEEE计算机学会的计算机先锋奖,Charles Babbage杰出科学家奖以及CS@ILLINOIS杰出教育家奖。2015年,Kuck入选工程学院名人堂(College of Engineering Hall of Fame)。
3.2 荣誉Honors
Kuck是美国科学促进会(AmericanAssociation for the Advancement of Science),计算机协会(ACM, the Association for Computing Machinery)和电气和电子工程师协会(the Instituteof Electrical and Electronics Engineers)成员。他也是国家工程院(the National Academy of Engineering)成员。他赢得了ACM/IEEE颁发的Eckert-MauchlyAward奖和IEEE计算机协会CharlesBabbage奖(the IEEE Computer Society Charles BabbageAward)。Kuck是创建OpenMP的主要贡献者。OpenMP是一种跨平台,基于指令的并行编程方法,在多核环境中尤其友好。2010年,Kuck被ACM和IEEE计算机学会高性能计算创新奖授予Ken Kennedy Award奖。[20][21]
C编译器知识(5721字)
编译器
文|秦陇纪,源|百度百科,科学Sciences2018110Thu
编译器是将“一种语言(通常为高级语言)”翻译为“另一种语言(通常为低级语言)”的计算机程序。一个现代编译器的主要工作流程:源代码(sourcecode)→预处理器(preprocessor)→编译器(compiler)→目标代码(objectcode)→链接器(Linker)→可执行程序(executables)。
高级计算机语言便于人编写、阅读交流、维护。机器语言是计算机能直接解读、运行的。编译器将汇编或高级计算机语言源程序(Source program)作为输入,翻译成目标语言(Target language)机器代码的等价程序。源代码一般为高级语言(High-level language),如Pascal、C、C++、Java、汉语编程等或汇编语言,而目标则是机器语言的目标代码(Object code),有时也称作机器代码(Machine code)。
对于C#、VB等高级语言而言,此时编译器完成的功能是把源码(SourceCode)编译成通用中间语言(MSIL/CIL)的字节码(ByteCode)。最后运行的时候通过通用语言运行库的转换,编程最终可以被CPU直接计算的机器码(NativeCode)。
图1 MS VC++编译器函数演示图
中文名:编译器,外文名:Compiler,别称:译码器,表达式:源代码→预处理器→编译器→目标代码,提出者:葛丽丝·霍普,提出时间:20世纪50年代末,应用学科:计算机,适用领域范围:计算机,单片机,编程语言。
1 工作原理
编译[1]是从源代码(通常为高级语言)到能直接被计算机或虚拟机执行的目标代码(通常为低级语言或机器语言)的翻译过程。然而,也存在从低级语言到高级语言的编译器,这类编译器中用来从由高级语言生成的低级语言代码重新生成高级语言代码的又被叫做反编译器。也有从一种高级语言生成另一种高级语言的编译器,或者生成一种需要进一步处理的的中间代码的编译器(又叫级联)。

图2 MS宏汇编编译器
典型的编译器输出是由包含入口点的名字和地址,以及外部调用(到不在这个目标文件中的函数调用)的机器代码所组成的目标文件。一组目标文件,不必是同一编译器产生,但使用的编译器必需采用同样的输出格式,可以链接在一起并生成可以由用户直接执行的EXE,所以我们电脑上的文件都是经过编译后的文件。
2 种类(▪处理器▪前端▪后端)
编译器可以生成用来在与编译器本身所在的计算机和操作系统(平台)相同的环境下运行的目标代码,这种编译器又叫做“本地”编译器。另外,编译器也可以生成用来在其它平台上运行的目标代码,这种编译器又叫做交叉编译器。交叉编译器在生成新的硬件平台时非常有用。“源码到源码编译器”是指用一种高级语言作为输入,输出也是高级语言的编译器。例如:自动并行化编译器经常采用一种高级语言作为输入,转换其中的代码,并用并行代码注释对它进行注释(如OpenMP)或者用语言构造进行注释(如FORTRAN的DOALL指令)。

图3 ISTool编译器
处理器
作用是通过代入预定义等程序段将源程序补充完整。
前端
前端主要负责解析(parse)输入的源代码,由语法分析器和语意分析器协同工作。语法分析器负责把源代码中的‘词块’(Token)找出来,语意分析器把这些分散的单词按预先定义好的语法组装成有意义的表达式,语句,函数等等。例如“a = b + c;”前端语法分析器看到的是“a,=,b,+,c;”,语意分析器按定义的语法,先把他们组装成表达式“b + c”,再组装成“a = b + c”的语句。前端还负责语义(semantic checking)的检查,例如检测参与运算的变量是否是同一类型的,简单的错误处理。最终的结果常常是一个抽象的语法树(abstract syntax tree,或AST),这样后端可以在此基础上进一步优化,处理。。(注5:token词义为象征、标志、纪念品、代币、代价券,和sign意思相同但比sign庄重文雅,常用于严肃场合。token有语言学词义:[语言学]语言符号,计算机词义:[计算机]令牌、标记。秦陇纪认为“符标”更合意,但常见NLP文献里token译为“词块”,随大流吧。)
图4 c/c++编译器选项
后端
编译器后端主要负责分析,优化中间代码(Intermediaterepresentation)以及生成机器代码(Code Generation)。一般说来所有的编译器分析,优化,变型都可以分成两大类:函数内(intraprocedural)还是函数之间(interprocedural)进行。很明显,函数间的分析,优化更准确,但需要更长的时间来完成。

3 代码分析
编译器分析(compiler analysis)的对象是前端生成并传递过来的中间代码,现代的优化型编译器(optimizing compiler)常常用好几种层次的中间代码来表示程序,高层的中间代码(high level IR)接近输入的源程序的格式,与输入语言相关(language dependent),包含更多的全局性的信息,和源程序的结构;中层的中间代码(middle level IR)与输入语言无关,低层的中间代码(Low level IR)与机器语言类似。不同的分析,优化发生在最适合的那一层中间代码上。

图6 编译器工作流程
常见的编译分析有函数调用树(call tree),控制流程图(Control flow graph),以及在此基础上的变量定义-使用,使用-定义链(define-use/use-defineor u-d/d-u chain),变量别名分析(alias analysis),指针分析(pointeranalysis),数据依赖分析(data dependence analysis)等。
程序分析结果是编译器优化(compiler optimization)和程序变形(compiler transformation)的前提条件。常见的优化和变形有:函数内嵌(inlining),无用代码删除(Dead code elimination),标准化循环结构(loop normalization),循环体展开(loop unrolling),循环体合并,分裂(loop fusion,loop fission),数组填充(arraypadding),等等。优化和变形的目的是减少代码的长度,提高内存(memory),缓存(cache)的使用率,减少读写磁盘,访问网络数据的频率。更高级的优化甚至可以把序列化的代码(serial code)变成并行运算,多线程的代码(parallelized,multi-threadedcode)。

图7 编译器内部结构图
机器代码的生成是优化变型后的中间代码转换成机器指令的过程。现代编译器主要采用生成汇编代码(assemblycode)的策略,而不直接生成二进制的目标代码(binaryobject code)。即使在代码生成阶段,高级编译器仍然要做很多分析,优化,变形的工作。例如如何分配寄存器(register allocatioin),如何选择合适的机器指令(instruction selection),如何合并几句代码成一句等等。
4 工作方法
首先编译器进行语法分析,也就是要把那些字符串分离出来。
然后进行语义分析,就是把各个由语法分析分析出的语法单元的意义搞清楚。
最后生成的是目标文件,也称为obj文件。
再经过链接器的链接就可以生成最后的EXE文件了。有些时候需要把多个文件产生的目标文件进行链接,产生最后的代码。这一过程称为交叉链接。
5 编译器优化
应用程序之所以复杂,是由于它们具有处理多种问题以及相关数据集的能力。实际上,一个复杂的应用程序就象许多不同功能的应用程序“粘贴”在一起。源文件中大部分复杂性来自于处理初始化和问题设置代码。这些文件虽然通常占源文件的很大一部分,具有很大难度,但基本上不花费CPU执行周期。
尽管存在上述情况,大多数Makefile文件只有一套编译器选项来编译项目中所有的文件。因此,标准的优化方法只是简单地提升优化选项的强度,一般从O 2到O3。这样一来,就需要投人大量精力来调试,以确定哪些文件不能被优化,并为这些文件建立特殊的make规则。
一个更简单但更有效的方法是通过一个性能分析器,来运行最初的代码,为那些占用了85一95% CPU的源文件生成一个列表。通常情况下,这些文件大约只占所有文件的1%。如果开发人员立刻为每一个列表中的文件建立其各自的规则,则会处于更灵活有效的位置。这样一来改变优化只会引起一小部分文件被重新编译。进而,由于时间不会浪费在优化不费时的函数上,重编译全部文件将会大大地加快。[25]
6 进行对比
许多人将高阶程序语言分为两类:编译型语言和直译型语言。然而,实际上,这些语言中的大多数既可用编译型实现也可用直译型实现,分类实际上反映的是那种语言常见的实现方式。(但是,某些直译型语言,很难用编译型实现。比如那些允许在线代码更改的直译型语言。)
7 历史
20世纪50年代,IBM的John Backus带领一个研究小组对FORTRAN语言及其编译器进行开发。但由于当时人们对编译理论了解不多,开发工作变得既复杂又艰苦。与此同时,Noam Chomsky开始了他对自然语言结构的研究。他的发现最终使得编译器的结构异常简单,甚至还带有了一些自动化。Chomsky的研究导致了根据语言文法的难易程度以及识别它们所需要的算法来对语言分类。正如Chomsky架构(Chomsky Hierarchy),它包括了文法的四个层次:0型文法、1型文法、2型文法和3型文法,且其中的每一个都是其前者的特殊情况。2型文法(或上下文无关文法)被证明是程序设计语言中最有用的,而且今天它已代表着程序设计语言结构的标准方式。分析问题(parsing problem,用于上下文无关文法识别的有效算法)的研究是在60年代和70年代,它相当完善的解决了这个问题。它已是编译原理中的一个标准部分。

图8 反编译器
有限状态自动机(FiniteAutomation)和正则表达式(RegularExpression)同上下文无关文法紧密相关,它们与Chomsky的3型文法相对应。对它们的研究与Chomsky的研究几乎同时开始,并且引出了表示程序设计语言的单词的符号方式。
人们接着又深化了生成有效目标代码的方法,这就是最初的编译器,它们被一直使用至今。人们通常将其称为优化技术(Optimization Technique),但因其从未真正地得到过被优化了的目标代码而仅仅改进了它的有效性,因此实际上应称作代码改进技术(Code ImprovementTechnique)。
当分析问题变得好懂起来时,人们就在开发程序上花费了很大的功夫来研究这一部分的编译器自动构造。这些程序最初被称为编译器的编译器(Compiler-compiler),但更确切地应称为分析程序生成器(ParserGenerator),这是因为它们仅仅能够自动处理编译的一部分。这些程序中最著名的是Yacc(Yet Another Compiler-compiler),它是由SteveJohnson在1975年为Unix系统编写的。类似的,有限状态自动机的研究也发展了一种称为扫描程序生成器(Scanner Generator)的工具,Lex(与Yacc同时,由MikeLesk为Unix系统开发)是这其中的佼佼者。
在20世纪70年代后期和80年代早期,大量的项目都贯注于编译器其它部分的生成自动化,这其中就包括了代码生成。这些尝试并未取得多少成功,这大概是因为操作太复杂而人们又对其不甚了解。
编译器设计最近的发展包括:首先,编译器包括了更加复杂算法的应用程序它用于推断或简化程序中的信息;这又与更为复杂的程序设计语言的发展结合在一起。其中典型的有用于函数语言编译的Hindley-Milner类型检查的统一算法。其次,编译器已越来越成为基于窗口的交互开发环境(Interactive DevelopmentEnvironment,IDE)的一部分,它包括了编辑器、连接程序、调试程序以及项目管理程序。这样的IDE标准并没有多少,但是对标准的窗口环境进行开发已成为方向。另一方面,尽管在编译原理领域进行了大量的研究,但是基本的编译器设计原理在近20年中都没有多大的改变,它正迅速地成为计算机科学课程中的中心环节。
在20世纪90年代,作为GNU项目或其它开放源代码项目标一部分,许多免费编译器和编译器开发工具被开发出来。这些工具可用来编译所有的计算机程序语言。它们中的一些项目被认为是高质量的,而且对现代编译理论感兴趣的人可以很容易的得到它们的免费源代码。
大约在1999年,SGI公布了他们的一个工业化的并行化优化编译器Pro64的源代码,后被全世界多个编译器研究小组用来做研究平台,并命名为Open64。Open64的设计结构好,分析优化全面,是编译器高级研究的理想平台。
编译器相关专业术语: [26]
| 1. |
compiler编译器;编译程序 |
| 2. |
on-line compiler 连线编译器 |
| 3. |
precompiler 预编译器 |
| 4. |
serial compiler 串行编译器 |
| 5. |
system-specific compiler 特殊系统编译器 |
| 6. |
Information Presentation Facility Compiler 信息展示设施编译器 |
| 7. |
Compiler Monitor System 编译器监视系统 |
权威合作编辑
“科普中国”百科科学词条编写与应用工作项目.资源提供中国电子学会(Chinese Instituteof Electronic)提供资源类型:内容。详情请大家直接看英文资料https://en.wikipedia.org/wiki/Compiler。词条标签:科学百科信息科学分类,中国电子学会,软件,网站,互联网。词条统计:浏览558610次,编辑51次历史版本,最近更新:w_ou(2018-08-12)。
—END—
参考文献(3832字)
1.wikipedia.Compiler.[EB/OL];wikipedia,https://en.wikipedia.org/wiki/Compiler,2018-11-16.
2.云头条.编译器的“五个十年”发展史.[EB/OL];云头条企鹅号,https://new.qq.com/omn/20181103/20181103A1R61K.html,2018-11-03.
3.wikipedia.John Cocke.[EB/OL];wikipedia,https://en.wikipedia.org/wiki/John_Cocke,2018-11-16.
4.Schofield, Jack (2002-07-27). "John Cocke". The Guardian. GuardianMedia Group. Retrieved 2011-05-10. "Cocke's idea was to use fewerinstructions, but design chips that performed simple instructions very quickly.[...] Later, this approach became known as reduced instruction set computing(Risc) [...]"
5.Jelinek, Frederick, "The Dawn of Statistical ASR and MT",Computational Linguistics, 35(4), 2009, pp. 483-494, doi:10.1162/coli.2009.35.4.35401
6.John Cocke, The search for performance in scientific processors: the TuringAward lecture. Communications of the ACM, Volume 31 Issue 3, March 1988, Pages250-253. doi:10.1145/42392.42394
7."National Science Foundation - The President's National Medal ofScience". Nsf.gov. Retrieved 2014-06-19.
8."John Cocke". thocp.net. Retrieved 21 December 2015.
9."John Cocke". Computer History Museum. Archived from the original on2013-05-09. Retrieved 2013-05-23.
10.在线阅读.编译器优化奠基人:John Cocke.[EB/OL];中国Linux联盟,http://www.lisdn.com/html/97/n-297.html,引用日期2012-12-05.
11.Association for Computing Machinery.CHRONOLOGICAL LISTING OFA.M. TURING AWARD WINNERS.[EB/OL];ACM官网,https://amturing.acm.org/byyear.cfm,引用日期2015-07-11,访问日期2018-11-16.
12.Institute of Electrical and Electronics Engineers.IEEE John von NeumannMedal Recipients.[EB/OL];IEEE官网,https://www.ieee.org/about/awards/bios/vonneumann-recipients.html#top,引用日期2015-07-11,访问日期2018-11-16.
13.National Science Foundation.The President's NationalMedal of Science: Recipient Search.[EB/OL];National ScienceFoundation官网https://www.nsf.gov/od/nms/recipients.jsp,引用日期2015-07-11,访问日期2018-11-16.
14.Institute of Electrical and Electronics Engineers.Computer Pioneer Award.[EB/OL];IEEE计算机协会官网,http://www.computer.org/web/awards/pioneer,引用日期2015-07-12,访问日期2018-11-16.
15.Office of the Chief Communications Officer,National Medal ofTechnology and Innovation (NMTI).The National Medal ofTechnology and Innovation 1991 Laureates.[EB/OL];The United States Patentand Trademark Office官网,https://www.uspto.gov/learning-and-resources/ip-programs-and-awards/national-medal-technology-and-innovation-nmti,引用日期2015-07-12,访问日期2018-11-16.
16.IT世界网..[EB/OL];IT世界网,http://www.it.com.cn/,访问日期2018-11-16.
17.最近更新:w_ou(2018-08-11).约翰·科克.[EB/OL];百度百科,https://baike.baidu.com/item/%E7%BA%A6%E7%BF%B0%C2%B7%E7%A7%91%E5%85%8B/7868274,2018-08-12,访问日期2018-11-14.
18.blackhu.[IT名人堂] 编译器优化奠基人:John Cocke.[EB/OL];CSDN,https://blog.csdn.net/blackhu/article/details/673604?utm_source=blogxgwz5,2006-04-23.
19.单片机论坛»论坛›非技术区›电子工程师杂谈›51hei小林.世界上第一个编译器的作者--女牛人Grace Murray Hoppe.[EB/OL];51黑电子论坛,http://www.51hei.com/bbs/dpj-55880-1.html,2016-9-24.
20.Alumn.David J. KuckOutstanding PhD Thesis Award.[EB/OL];the University of Illinoisat Urbana-Champaign,https://cs.illinois.edu/about-us/awards/graduate-fellowships-awards/david-j-kuck-outstanding-thesis-awards,访问日期2018-11-16.
21.wikipedia.David Kuck.[EB/OL];wikipedia,https://en.wikipedia.org/wiki/David_Kuck,2018-03-13.
22.秦陇纪,计算机的数学思想源头(回复“计算机数学”可下载PDF典藏版).[EB/OL];数据简化DataSimp,https://mp.weixin.qq.com/s/JLGCOPN-OIyfyM5Rb0EKIw,2018-04-16.
23.最近更新:ActLikeDove(2018-10-28).约翰·冯·诺依曼.[EB/OL];百度百科,https://baike.baidu.com/item/%E7%BA%A6%E7%BF%B0%C2%B7%E5%86%AF%C2%B7%E8%AF%BA%E4%BE%9D%E6%9B%BC/986797,2018-10-28,访问日期2018-11-18.
24.编译互动的博客,胡月军聊天的博客.置顶:从实战中理解编译原理1(一断、二比、三译).[EB/OL];wikipedia,http://blog.sina.com.cn/compileinteract,2013-07-16,引用日期2013-07-31.
25.David Levinthal Vladimir Tsymbal.注重性能的编译器使用:电脑编程技巧与维护,2005年:08期.
26.最近更新:w_ou(2018-08-12).编译器.[EB/OL];百度百科,https://baike.baidu.com/item/%E7%BC%96%E8%AF%91%E5%99%A8,2018-08-12,访问日期2018-11-14.
x.秦陇纪.数据简化社区Python官网Web框架概述;数据简化社区2018年全球数据库总结及18种主流数据库介绍;数据科学与大数据技术专业概论;人工智能研究现状及教育应用;信息社会的数据资源概论;纯文本数据溯源与简化之神经网络训练;大数据简化之技术体系.[EB/OL];数据简化DataSimp(微信公众号),http://www.datasimp.org,2017-06-06.
编译器发展史5个十年3大人物及编译器知识(25289字)
秦陇纪
简介:编译器发展史5个十年3大人物及编译器知识。公号回复“编译器”文末“阅读原文”可下载31k字1表17图21页PDF资料,欢迎转发、赞赏、支持科普。蓝色链接“科学Sciences”关注后下方菜单项有文章分类页。作者:秦陇纪。来源:Michael Wolfe/维基百科/百度百科/数据简化社区/秦陇纪微信群聊公众号,引文出处附参考文献。主编译者:秦陇纪,数据简化DataSimp/科学Sciences/知识简化新媒体创立者,数据简化社区创始人OS架构师/C/Java/Python/Prolog程序员,IT教师。每天大量中英文阅读/设计开发调试/文章汇译编简化,时间精力人力有限,欢迎转发/赞赏/加入支持社区。版权声明:科普文章仅供学习研究,公开资料©版权归原作者,请勿用于商业非法目的。秦陇纪2018数据简化DataSimp综合汇译编,投稿合作、转载授权、侵权错误(包括原文错误)等请联系[email protected]沟通。欢迎转发:“数据简化DataSimp、科学Sciences、知识简化”新媒体聚集专业领域一线研究员;研究技术时也传播知识、专业视角解释和普及科学现象和原理,展现自然社会生活之科学面。秦陇纪发起,期待您参与各领域~~
Appx.数据简化DataSimp社区简介(835字)
信息社会之数据、信息、知识、理论持续累积,远超个人认知学习的时间、精力和能力。应对大数据时代的数据爆炸、信息爆炸、知识爆炸,解决之道重在数据简化(DataSimplification):简化减少知识、媒体、社交数据,使信息、数据、知识越来越简单,符合人与设备的负荷。数据简化2018年会议(DS2018)聚焦数据简化技术(DataSimplificationTechniques):对各类数据从采集、处理、存储、阅读、分析、逻辑、形式等方面做简化,应用于信息及数据系统、知识工程、各类数据库、物理空间表征、生物医学数据,数学统计、自然语言处理、机器学习技术、人工智能等领域。欢迎投稿数据科学技术、简化实例相关论文提交电子版(最好有PDF格式)。填写申请表加入数据简化DataSimp社区成员,应至少一篇数据智能、编程开发IT文章:①高质量原创或翻译美欧数据科技论文;②社区网站义工或完善S圈型黑白静态和三彩色动态社区LOGO图标。论文投稿、加入数据简化社区,详情访问www.datasimp.org社区网站,网站维护请投会员邮箱[email protected]。请关注公众号“数据简化DataSimp”留言,或加微信QinlongGEcai(备注:姓名/单位-职务/学校-专业/手机号),免费加入投稿群或“科学Sciences学术文献”读者微信群等。长按下图“识别图中二维码”关注三个公众号(搜名称也行,关注后底部菜单有文章分类页链接):
数据技术公众号“数据简化DataSimp”:

科普公众号“科学Sciences”:

社会教育知识公众号“知识简化”:

(转载请写出处:©秦陇纪2010-2018汇译编,欢迎技术、传媒伙伴投稿、加入数据简化社区!“数据简化DataSimp、科学Sciences、知识简化”投稿反馈邮箱[email protected]。)
普及科学知识,分享到朋友圈

转发/留言/打赏后“阅读原文”下载PDF
阅读原文

微信扫一扫
关注该公众号