爬虫入门系列
1. Requests库入门
一、安装 Requests
通过pip安装
pip install requests
二、发送请求与传递参数
- Requests库的七个主要方法:

库方法
- get方法
r = requests.get(url):右边构造一个向服务器请求资源的Requests对象,左边返回一个包含服务器资源的Response对象给r
完整参数:requests.get(url,params=None,**kwargs),实则由request方法封装
Resonse对象的五个属性:
属性
- 爬取网页的通用代码框架
Requests库爬取网页会遇到异常: 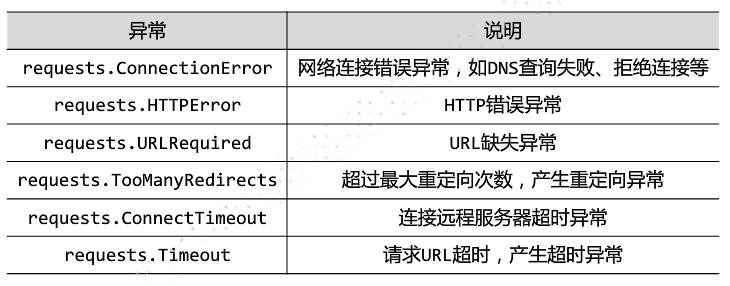
6种常用异常
使用r.raise_for_status()方法构建通用代码框架:
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status() #如果状态不是 200 ,主动引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
- HTTP协议及Requests库方法
- method(请求方式)包括:
GET/HEAD/POST/PUT/PATCH/delete/OPTIONS - **kwargs(控制访问参数)包括:
params(添加键值到url后)/data(字典/字节序列等作为Request的内容)/json/headers(HTTP定制头)/cookies(Request中的cookie)/auth(元祖,支持HTTP认证)/files(传输文件)/timeout/proxies(设定访问代理服务器)/allow_redirects(重定向开关)/stream(获取内容立即下载开关)/verify(认证SSL证书开关)/cert(本地SSL证书路径)
- method(请求方式)包括:
- HTTP(Hypertext Transfer Protocol,超文本传输协议)是一个基于"请求与响应"模式的/无状态的应用层协议;URL是通过HTTP协议存取资源的Internet路径
HTTP协议对资源的操作: 
HTTP方法
-
Requests库主要方法:requests.request(method,url,**kwargs)
method : 请求方式 , 对应get /put /post /等7种方法
url : 拟获取页面的url链接
r = requeste.request('GET',url,**kwargs)
r = requeste.request('HEAD',url,**kwargs)
r = requeste.request('POST',url,**kwargs)
r = requeste.request('PUT',url,**kwargs)
r = requeste.request('PATCH',url,**kwargs)
r = requeste.request('delete',url,**kwargs)
r = requeste.request('OPTIONS',url,**kwargs)
requests.get () , requests.put()等都是基于request的
** kwargs : 控制访问的参数,均为可选项
params : 字典或字节序列 ,作为参数增加到 url 中
url = 'https://python123.io/ws'
kv = {'key1':'value1','key2':'value2'}
r = requests.request('GET',url,params=kv)
print(r.url)
# https://python123.io/ws?key1=value1&key2=value2data: 字典,字节序列或文件对象 ,作为Request 的内容
kv = {'key1':'value1','key2':'value2'}
url = 'https://python123.io/ws'
r = requests.request('POST',url,data=kv)
body = '主体内容'
r = requests.request('POST',url,data=body)json : json 格式的数据 ,作为Request的内容 :
url = 'https://python123.io/ws'
kv = {'key1':'value1','key2':'value2'}
r = requests.request('POST',url,json=kv)headers : 字典 , http 定制头
url = 'https://python123.io/ws'
hd = {'user-agent':'Chrome/10'}
r = requests.request('POST',url,headers=hd)cookies : 字典或CookieJar , Request中的cookie
auth : 元组 ,支持http 认证功能
files : 字典类型,传输文件
fs = {'file':open('data.xls','rb')}
r = requests.request('POST',url,files=fs)timeout : 设定超时时间 ,秒为单位
r = requests.request('POST',url,timeout=10)proxies :字典类型 ,设定访问代理服务器 , 可以增加登录认证
.....
2. 网络爬虫的盗亦有道
- 网络爬虫引发的问题

网络爬虫的尺寸
- 网络爬虫可能会给Web服务器带来巨大的资源开销
- 网络爬虫获取数据后可能会带来法律风险
- 网络爬虫可能会造成隐私泄露
对网络爬虫的限制: - 来源审查:检查来访HTTP协议头的User-Agent域
- 发布公告:Robots协议
- Robots协议(Robots Exclusion Standard,网络爬虫排除标准)
爬虫应自动或人工识别robots.txt,但Robots协议是建议但非约束性
Robots协议
网站告诉爬虫哪些页面允许获取 ,哪些不允许获取 .
京东的RObots协议 https://www.jd.com/robots.txt
3. Requests库爬取实例
实例1 京东商品页面的爬取
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status() #如果状态不是 200 ,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text[:1000]
except:
return "产生异常"
if __name__ == "__main__":
url = 'https://item.jd.com/100001550349.html'
print(getHTMLText(url))实例2 亚马逊商品页面爬取 由于亚马逊有自身的头部审查,故我们模拟浏览器访问:
def getHTMLText(url):
try:
kv = {'user-agent':'Mozilla/5.0'} #模拟浏览器向http发送请求
r = requests.get(url,headers=kv) # 修改头部信息
r.raise_for_status() #如果状态不是 200 ,引发HTTPError异常
r.encoding = r.apparent_encoding
print(r.text[1000:2000])
except:
return "产生异常"
if __name__ == "__main__":
url = 'https://item.jd.com/100001550349.html'
url1 = 'https://www.amazon.cn/dp/B0083DP0CY/ref=cngwdyfloorv2_recs_0?pf_rd_p=db4e96ef-5fc1-47f8-92b2-b9a5e737b326&pf_rd_s=desktop-2&pf_rd_t=36701&pf_rd_i=desktop&pf_rd_m=A1AJ19PSB66TGU&pf_rd_r=S3W96Q29FW67JSZNJXTF&pf_rd_r=S3W96Q29FW67JSZNJXTF&pf_rd_p=db4e96ef-5fc1-47f8-92b2-b9a5e737b326'
getHTMLText(url1)实例 3 百度360搜素关键词提交

import requests
keyword = "Python" #搜素关键词
try:
kv = {'wd':keyword}
url = 'http://www.baidu.com/s'
r = requests.get(url,params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")360搜素
import requests
keyword = "Python" #搜素关键词
url = 'https://www.so.com/s' #搜素引擎
try:
kv = {'q':keyword}
r = requests.get(url,params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
# https://www.so.com/s?q=Python
# 311964
实例 4 网络图片的爬取和存储
import requests
import os
url = "http://image.nationalgeographic.com.cn/2017/0311/20170311024522382.jpg"
root = "D://pics//"
path = root +url.split('/')[-1]
print(path)
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
实例5 IP 地址归属地的自动查询
import requests
import os
try:
url = "http://m.ip138.com/ip.asp?ip="
r = requests.get(url+'202.194.119.110')
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")