Python3运用requests包爬取QQ音乐指定歌手歌曲
Python3应用requests包开发定向爬虫
最近学院给我们开设了Python+爬虫课程,请来了外面的公司的老师来给我们进行了为期10天的爬虫课程,实训的日子最近结束,我也有时间把我们平常写的拿来回顾一下写写博客。这个聚焦爬虫可以用来爬取QQ音乐web端指定歌手的音乐(客户端需要vip才能听的也可以爬),大家喜欢的可以多点赞(手动狗头)。接下来上代码和讲解:
这个爬虫采用了面向对象的思想,运用requests包和json包,从QQ音乐web端爬取指定歌手的音乐并以.m4a形式下载到本地。QQ音乐web端采用异步请求获取音乐文件,所以不能直接从看到的那个页面的链接爬取。
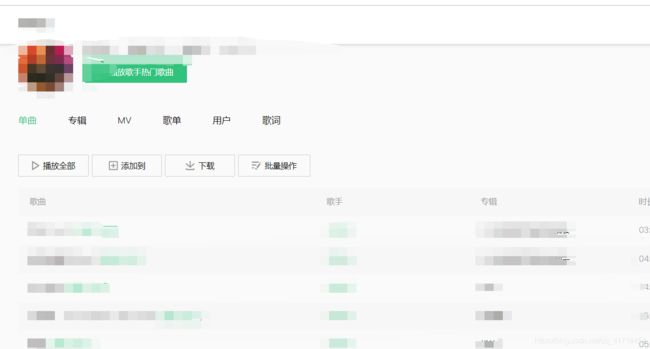
打开开发者工具,在network里刷新,找到真正的传来音乐文件响应(有时候很难找…),复制他的链接(在这里是一个client_search的链接),包括参数(很重要,有时候没这些参数是请求不到数据的)。
class QQMusic:
def __init__(self, singer):
self.singer = singer
self.tmp_singer_url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=58393477745290472&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=' + self.singer + '&g_tk=5381&loginUin=249099&hostUin=0&platform=yqq.json&needNewCode=0'
self.guid = "3481851020"
self.headers = {
"Referer": "https://y.qq.com/portal/player.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"
}
类的初始化函数,用来定义请求头和一些必要的参数和请求头信息,没有这些很可能取不到,或者被识别为爬虫。
# 获取歌手名
def get_singer_url(self):
return self.tmp_singer_url
# 利用歌曲id获取歌曲链接
def get_music_url(self, songmid):
return 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"' + self.guid + '","songmid":["' + songmid + '"],"songtype":[0],"uin":"27281729","loginflag":1,"platform":"20"}},"comm":{"uin":"27281729","format":"json","ct":24,"cv":0}}'
# 获取指定url的响应内容
def parse_url(self, url):
response = requests.get(url, headers=self.headers)
return response.content
# 从响应内容获取歌曲的列表
def get_song_url(self, content):
song_dict = json.loads(content.decode())
sip = song_dict["req_0"]["data"]["sip"][0] # http://ws.stream.qqmusic.qq.com/
purl = song_dict["req_0"]["data"]["midurlinfo"][0]["purl"]
url = sip + purl
filename = song_dict["req_0"]["data"]["midurlinfo"][0]["filename"]
return url, filename
# 将音乐的url响应的内容通过二进制输出到文件中
def write_song_to_file(self, content, filename):
with open(filename, "wb") as f:
f.write(content)
print(filename + "保存成功")
# 获取歌曲列表
def get_song_list(self, content):
json_str = content.decode()
song_dict = json.loads(json_str[9:-1])
song_list = song_dict["data"]["song"]["list"]
new_song_list = [ {"title": song["title"], "songmid": song["mid"]} for song in song_list]
return new_song_list
def run(self):
# 获取歌手的url地址
singer_url = self.get_singer_url()
# 发送请求获取歌手的歌曲的列表
singer_content = self.parse_url(singer_url)
print(singer_content)
# 解析歌手的歌曲列表
song_list = self.get_song_list(singer_content)
# 遍历歌曲列表,对每首歌进行操作
for song in song_list:
# 循环遍历歌手的歌曲列表,下载歌曲
# 发送请求获取歌曲的下载地址
# 获取初始化的url地址
url = self.get_music_url(song["songmid"])
# 发送请求获取响应
content = self.parse_url(url)
# 处理响应数据,获取歌曲的下载地址
song_url, filename = self.get_song_url(content)
filename = song["title"] + ".m4a"
# 发送请求下载歌曲
song_content = self.parse_url(song_url)
# 保存到文件中
self.write_song_to_file(song_content, filename)
这里的注释说的很清楚了,核心的方法是run,获取你相查的歌手的歌曲列表url,然后for循环每一首歌,获取歌曲文件的url,访问获得文件并以二进制输出到本地。
比如:
import json
import requests
class QQMusic:
def __init__(self, singer):
self.singer = singer
self.tmp_singer_url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=58393477745290472&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=' + self.singer + '&g_tk=5381&loginUin=249099&hostUin=0&platform=yqq.json&needNewCode=0'
self.guid = "3481851020"
self.headers = {
"Referer": "https://y.qq.com/portal/player.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"
}
# 获取歌手名
def get_singer_url(self):
return self.tmp_singer_url
# 利用歌曲id获取歌曲链接
def get_music_url(self, songmid):
return 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"' + self.guid + '","songmid":["' + songmid + '"],"songtype":[0],"uin":"27281729","loginflag":1,"platform":"20"}},"comm":{"uin":"27281729","format":"json","ct":24,"cv":0}}'
# 获取指定url的响应内容
def parse_url(self, url):
response = requests.get(url, headers=self.headers)
return response.content
# 从响应内容获取歌曲的列表
def get_song_url(self, content):
song_dict = json.loads(content.decode())
sip = song_dict["req_0"]["data"]["sip"][0] # http://ws.stream.qqmusic.qq.com/
purl = song_dict["req_0"]["data"]["midurlinfo"][0]["purl"]
url = sip + purl
filename = song_dict["req_0"]["data"]["midurlinfo"][0]["filename"]
return url, filename
# 将音乐的url响应的内容通过二进制输出到文件中
def write_song_to_file(self, content, filename):
with open(filename, "wb") as f:
f.write(content)
print(filename + "保存成功")
# 获取歌曲列表
def get_song_list(self, content):
json_str = content.decode()
song_dict = json.loads(json_str[9:-1])
song_list = song_dict["data"]["song"]["list"]
new_song_list = [ {"title": song["title"], "songmid": song["mid"]} for song in song_list]
return new_song_list
def run(self):
# 获取歌手的url地址
singer_url = self.get_singer_url()
# 发送请求获取歌手的歌曲的列表
singer_content = self.parse_url(singer_url)
print(singer_content)
# 解析歌手的歌曲列表
song_list = self.get_song_list(singer_content)
# 遍历歌曲列表,对每首歌进行操作
for song in song_list:
# 循环遍历歌手的歌曲列表,下载歌曲
# 发送请求获取歌曲的下载地址
# 获取初始化的url地址
url = self.get_music_url(song["songmid"])
# 发送请求获取响应
content = self.parse_url(url)
# 处理响应数据,获取歌曲的下载地址
song_url, filename = self.get_song_url(content)
filename = song["title"] + ".m4a"
# 发送请求下载歌曲
song_content = self.parse_url(song_url)
# 保存到文件中
self.write_song_to_file(song_content, filename)
if __name__ == '__main__':
singer = "李荣浩"
qqmusic = QQMusic(singer)
qqmusic.run()
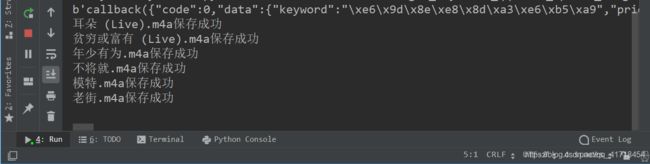
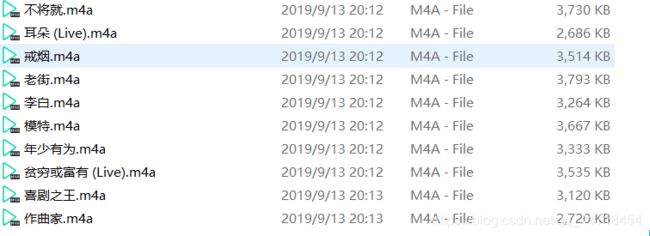
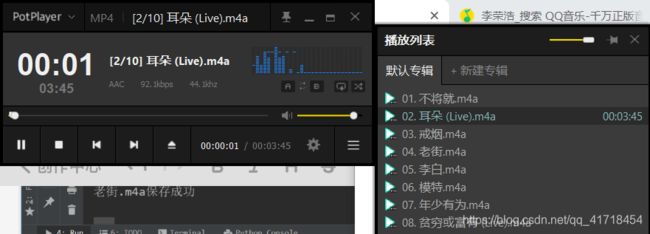
这样就爬到音乐了!请各位观众老爷给个赞?吧!!
