【学习笔记】【机器学习】第3章——线性模型
第3章 线性模型 53
3.1 基本形式 53
给定由 d d d 个属性描述的示例 x = ( x 1 ; x 2 ; … ; x d ) \boldsymbol x = (x_1;x_2;\dots;x_d) x=(x1;x2;…;xd) ,其中 x i x_i xi 是 x \boldsymbol x x 在第 i i i 个属性上的取值,线性模型(linear model)试图学得一个通过属性得线性组合来进行预测的函数,即
f ( x ) = w 1 x 1 + w 1 x 1 + ⋅ ⋅ ⋅ + w d x d + b , f(\boldsymbol x) = w_1x_1+w_1x_1+···+w_dx_d+b , f(x)=w1x1+w1x1+⋅⋅⋅+wdxd+b,
一般用向量形式写成
f ( x ) = w T x + b , f(\boldsymbol x) = \boldsymbol w^T \boldsymbol x+b, f(x)=wTx+b,
其中 w = ( w 1 ; w 2 ; … ; w d ) \boldsymbol w = (w_1;w_2;\dots;w_d) w=(w1;w2;…;wd)。 w \boldsymbol w w 和 b b b 学得之后,模型就得以确定。
由于 w \boldsymbol w w 直观表达了各属性在预测中的重要性,因此线性模型有很好的可解释性。
3.2 线性回归 53
线性回归试图学得一个线性模型以尽可能准确地预测实值输出标记
f ( x i ) = w x i + b , 使 得 f ( x i ) ≃ y i f(x_i) = wx_i+b,使得 f(x_i) \simeq y_i f(xi)=wxi+b,使得f(xi)≃yi
均方误差最小化
( w ∗ , b ∗ ) = arg min ( w , b ) ∑ i = 1 m ( f ( x i ) − y i ) 2 = arg min ( w , b ) ∑ i = 1 m ( y i − w x i − b ) 2 \begin{aligned} (w^*,b^*) &= \mathop{\arg\min}\limits_{(w,b)}\sum\limits_{i=1}^{m}(f(x_i)-y_i)^2\\ &= \mathop{\arg\min}\limits_{(w,b)}\sum\limits_{i=1}^{m}(y_i-wx_i-b)^2 \end{aligned} (w∗,b∗)=(w,b)argmini=1∑m(f(xi)−yi)2=(w,b)argmini=1∑m(yi−wxi−b)2
均方误差有非常好的几何意义,它对应了常用的欧几里得距离或简称“欧氏距离”。基于均方误差最小化来进行模型求解的方法称为“最小二乘法”。
求解 w w w 和 b b b 使 E ( w , b ) = ∑ i = 1 m ( y i − w x i − b ) 2 E_{(w,b)} = \sum_{i=1}^{m}(y_i-wx_i-b)^2 E(w,b)=∑i=1m(yi−wxi−b)2最小化的过程,称为线性回归模型的最小二乘“参数估计”。将 E ( w , b ) E_{(w,b)} E(w,b) 分别对 w w w 和 b b b 求导,得到
∂ E ( w , b ) ∂ w = ∂ ∂ w [ ∑ i = 1 m ( y i − w x i − b ) 2 ] = ∑ i = 1 m ∂ ∂ w [ ( y i − w x i − b ) 2 ] = ∑ i = 1 m [ 2 ⋅ ( y i − w x i − b ) ⋅ ( − x i ) ] = ∑ i = 1 m [ 2 ⋅ ( w x i 2 − y i x i + b x i ) ] = 2 ⋅ ( w ∑ i = 1 m x i 2 − ∑ i = 1 m y i x i + b ∑ i = 1 m x i ) = 2 ( w ∑ i = 1 m x i 2 − ∑ i = 1 m ( y i − b ) x i ) \begin{aligned} \cfrac{\partial E_{(w, b)}}{\partial w}&=\cfrac{\partial}{\partial w} \left[\sum_{i=1}^{m}\left(y_{i}-w x_{i}-b\right)^{2}\right] \\ &= \sum_{i=1}^{m}\cfrac{\partial}{\partial w} \left[\left(y_{i}-w x_{i}-b\right)^{2}\right] \\ &= \sum_{i=1}^{m}\left[2\cdot\left(y_{i}-w x_{i}-b\right)\cdot (-x_i)\right] \\ &= \sum_{i=1}^{m}\left[2\cdot\left(w x_{i}^2-y_i x_i +bx_i\right)\right] \\ &= 2\cdot\left(w\sum_{i=1}^{m} x_{i}^2-\sum_{i=1}^{m}y_i x_i +b\sum_{i=1}^{m}x_i\right) \\ &=2\left(w \sum_{i=1}^{m} x_{i}^{2}-\sum_{i=1}^{m}\left(y_{i}-b\right) x_{i}\right) \end{aligned} ∂w∂E(w,b)=∂w∂[i=1∑m(yi−wxi−b)2]=i=1∑m∂w∂[(yi−wxi−b)2]=i=1∑m[2⋅(yi−wxi−b)⋅(−xi)]=i=1∑m[2⋅(wxi2−yixi+bxi)]=2⋅(wi=1∑mxi2−i=1∑myixi+bi=1∑mxi)=2(wi=1∑mxi2−i=1∑m(yi−b)xi)
同理
∂ E ( w , b ) ∂ b = ∂ ∂ b [ ∑ i = 1 m ( y i − w x i − b ) 2 ] = ∑ i = 1 m ∂ ∂ b [ ( y i − w x i − b ) 2 ] = ∑ i = 1 m [ 2 ⋅ ( y i − w x i − b ) ⋅ ( − 1 ) ] = ∑ i = 1 m [ 2 ⋅ ( b − y i + w x i ) ] = 2 ⋅ [ ∑ i = 1 m b − ∑ i = 1 m y i + ∑ i = 1 m w x i ] = 2 ( m b − ∑ i = 1 m ( y i − w x i ) ) \begin{aligned} \cfrac{\partial E_{(w, b)}}{\partial b}&=\cfrac{\partial}{\partial b} \left[\sum_{i=1}^{m}\left(y_{i}-w x_{i}-b\right)^{2}\right] \\ &=\sum_{i=1}^{m}\cfrac{\partial}{\partial b} \left[\left(y_{i}-w x_{i}-b\right)^{2}\right] \\ &=\sum_{i=1}^{m}\left[2\cdot\left(y_{i}-w x_{i}-b\right)\cdot (-1)\right] \\ &=\sum_{i=1}^{m}\left[2\cdot\left(b-y_{i}+w x_{i}\right)\right] \\ &=2\cdot\left[\sum_{i=1}^{m}b-\sum_{i=1}^{m}y_{i}+\sum_{i=1}^{m}w x_{i}\right] \\ &=2\left(m b-\sum_{i=1}^{m}\left(y_{i}-w x_{i}\right)\right) \end{aligned} ∂b∂E(w,b)=∂b∂[i=1∑m(yi−wxi−b)2]=i=1∑m∂b∂[(yi−wxi−b)2]=i=1∑m[2⋅(yi−wxi−b)⋅(−1)]=i=1∑m[2⋅(b−yi+wxi)]=2⋅[i=1∑mb−i=1∑myi+i=1∑mwxi]=2(mb−i=1∑m(yi−wxi))
令上述两式分别为0,可得到 w w w 和 b b b 最优解的闭式解
0 = w ∑ i = 1 m x i 2 − ∑ i = 1 m ( y i − b ) x i w ∑ i = 1 m x i 2 = ∑ i = 1 m y i x i − ∑ i = 1 m b x i w ∑ i = 1 m x i 2 = ∑ i = 1 m y i x i − ∑ i = 1 m ( y ˉ − w x ˉ ) x i w ∑ i = 1 m x i 2 = ∑ i = 1 m y i x i − y ˉ ∑ i = 1 m x i + w x ˉ ∑ i = 1 m x i w ( ∑ i = 1 m x i 2 − x ˉ ∑ i = 1 m x i ) = ∑ i = 1 m y i x i − y ˉ ∑ i = 1 m x i w = ∑ i = 1 m y i x i − y ˉ ∑ i = 1 m x i ∑ i = 1 m x i 2 − x ˉ ∑ i = 1 m x i w = ∑ i = 1 m y i ( x i − x ˉ ) ∑ i = 1 m x i 2 − 1 m ( ∑ i = 1 m x i ) 2 \begin{aligned} 0 &= w\sum_{i=1}^{m}x_i^2-\sum_{i=1}^{m}(y_i-b)x_i\\ w\sum_{i=1}^{m}x_i^2 &= \sum_{i=1}^{m}y_ix_i-\sum_{i=1}^{m}bx_i \\ w\sum_{i=1}^{m}x_i^2 & = \sum_{i=1}^{m}y_ix_i-\sum_{i=1}^{m}(\bar{y}-w\bar{x})x_i \\ w\sum_{i=1}^{m}x_i^2 & = \sum_{i=1}^{m}y_ix_i-\bar{y}\sum_{i=1}^{m}x_i+w\bar{x}\sum_{i=1}^{m}x_i \\ w(\sum_{i=1}^{m}x_i^2-\bar{x}\sum_{i=1}^{m}x_i) & = \sum_{i=1}^{m}y_ix_i-\bar{y}\sum_{i=1}^{m}x_i \\ w & = \cfrac{\sum_{i=1}^{m}y_ix_i-\bar{y}\sum_{i=1}^{m}x_i}{\sum_{i=1}^{m}x_i^2-\bar{x}\sum_{i=1}^{m}x_i}\\ w &= \cfrac{\sum_{i=1}^{m}y_i(x_i-\bar{x})}{\sum_{i=1}^{m}x_i^2-\cfrac{1}{m}(\sum_{i=1}^{m}x_i)^2} \end{aligned} 0wi=1∑mxi2wi=1∑mxi2wi=1∑mxi2w(i=1∑mxi2−xˉi=1∑mxi)ww=wi=1∑mxi2−i=1∑m(yi−b)xi=i=1∑myixi−i=1∑mbxi=i=1∑myixi−i=1∑m(yˉ−wxˉ)xi=i=1∑myixi−yˉi=1∑mxi+wxˉi=1∑mxi=i=1∑myixi−yˉi=1∑mxi=∑i=1mxi2−xˉ∑i=1mxi∑i=1myixi−yˉ∑i=1mxi=∑i=1mxi2−m1(∑i=1mxi)2∑i=1myi(xi−xˉ)
同理
0 = m b − ∑ i = 1 m ( y i − w x i ) m b = ∑ i = 1 m ( y i − w x i ) b = 1 m ∑ i = 1 m ( y i − w x i ) \begin{aligned} 0 &= m b-\sum_{i=1}^{m}\left(y_{i}-w x_{i}\right)\\ mb &= \sum_{i=1}^{m}\left(y_{i}-w x_{i}\right)\\ b &= \frac {1}{m} \sum_{i=1}^{m}\left(y_{i}-w x_{i}\right) \end{aligned} 0mbb=mb−i=1∑m(yi−wxi)=i=1∑m(yi−wxi)=m1i=1∑m(yi−wxi)
更一般的情况是样本由 d d d 个属性描述,称为“多元线性回归”。类似的,可以用最小二乘法来对 w \boldsymbol w w 和 b b b 进行估计。把 w \boldsymbol w w 和 b b b 吸收入向量形式 w ^ = ( w ; b ) \boldsymbol {\hat{w}} = (\boldsymbol w;b) w^=(w;b),把数据集 D D D 表示为一个 m × ( d + 1 ) m \times (d+1) m×(d+1) 大小的矩阵 X \mathbf X X
X = ( x 11 x 12 ⋯ x 1 d 1 x 21 x 22 ⋯ x 2 d 1 ⋮ ⋮ ⋱ ⋮ ⋮ x m 1 x m 2 ⋯ x m d 1 ) = ( x 1 T 1 x 2 T 1 ⋮ ⋮ x m T 1 ) \mathbf X=\begin{pmatrix} x_{11} & x_{12} & \cdots & x_{1d} &1 \\ x_{21} & x_{22} & \cdots & x_{2d} &1 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_{m1} & x_{m2} & \cdots & x_{md} &1 \\ \end{pmatrix} = \begin{pmatrix} \boldsymbol x_{1}^{\mathrm{T}} & 1 \\ \boldsymbol x_{2}^{\mathrm{T}} & 1 \\ \vdots & \vdots \\ \boldsymbol x_{m}^{\mathrm{T}} & 1 \\ \end{pmatrix} X=⎝⎜⎜⎜⎛x11x21⋮xm1x12x22⋮xm2⋯⋯⋱⋯x1dx2d⋮xmd11⋮1⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x1Tx2T⋮xmT11⋮1⎠⎟⎟⎟⎞
把标记写成向量形式 y = ( y 1 ; y 2 ; … ; y m ) \boldsymbol y = (y_1;y_2;\dots;y_m) y=(y1;y2;…;ym),有
w ^ ∗ = arg min w ^ ( y − X w ^ ) T ( y − X w ^ ) \begin{aligned} \boldsymbol {\hat{w}}^* &= \mathop{\arg\min}\limits_{\boldsymbol {\hat{w}}}(\boldsymbol{y}-\mathbf X\boldsymbol{\hat w})^\mathrm{T} (\boldsymbol{y}-\mathbf X\boldsymbol{\hat w})\\ \end{aligned} w^∗=w^argmin(y−Xw^)T(y−Xw^)
令 E w ^ = ( y − X w ^ ) T ( y − X w ^ ) E_{\boldsymbol {\hat{w}}} = (\boldsymbol{y}-\mathbf X\boldsymbol{\hat w})^\mathrm{T} (\boldsymbol{y}-\mathbf X\boldsymbol{\hat w}) Ew^=(y−Xw^)T(y−Xw^),对 w ^ \boldsymbol {\hat{w}} w^ 求导得
∂ E w ^ ∂ w ^ = ∂ ( y T y − y T X w ^ − w ^ T X T y + w ^ T X T X w ^ ) ∂ w ^ = ∂ y T y ∂ w ^ − ∂ y T X w ^ ∂ w ^ − ∂ w ^ T X T y ∂ w ^ + ∂ w ^ T X T X w ^ ∂ w ^ = 0 − X T y − X T y + ( X T X + X T X ) w ^ = 2 X T ( X w ^ − y ) \begin{aligned} \cfrac{\partial E_{\hat{\boldsymbol w}}}{\partial \hat{\boldsymbol w}} &= \cfrac {\partial (\boldsymbol{y}^{\mathrm{T}}\boldsymbol{y}-\boldsymbol{y}^{\mathrm{T}}\mathbf{X}\hat{\boldsymbol w}-\hat{\boldsymbol w}^{\mathrm{T}}\mathbf{X}^{\mathrm{T}}\boldsymbol{y}+\hat{\boldsymbol w}^{\mathrm{T}}\mathbf{X}^{\mathrm{T}}\mathbf{X}\hat{\boldsymbol w})} {\partial \hat{\boldsymbol w}} \\ &= \cfrac{\partial \boldsymbol{y}^{\mathrm{T}}\boldsymbol{y}}{\partial \hat{\boldsymbol w}}-\cfrac{\partial \boldsymbol{y}^{\mathrm{T}}\mathbf{X}\hat{\boldsymbol w}}{\partial \hat{\boldsymbol w}}-\cfrac{\partial \hat{\boldsymbol w}^{\mathrm{T}}\mathbf{X}^{\mathrm{T}}\boldsymbol{y}}{\partial \hat{\boldsymbol w}}+\cfrac{\partial \hat{\boldsymbol w}^{\mathrm{T}}\mathbf{X}^{\mathrm{T}}\mathbf{X}\hat{\boldsymbol w}}{\partial \hat{\boldsymbol w}}\\ &= 0-\mathbf{X}^{\mathrm{T}}\boldsymbol{y}-\mathbf{X}^{\mathrm{T}}\boldsymbol{y}+(\mathbf{X}^{\mathrm{T}}\mathbf{X}+\mathbf{X}^{\mathrm{T}}\mathbf{X})\hat{\boldsymbol w}\\ &=2\mathbf{X}^{\mathrm{T}}(\mathbf{X}\hat{\boldsymbol w}-\boldsymbol{y}) \end{aligned} ∂w^∂Ew^=∂w^∂(yTy−yTXw^−w^TXTy+w^TXTXw^)=∂w^∂yTy−∂w^∂yTXw^−∂w^∂w^TXTy+∂w^∂w^TXTXw^=0−XTy−XTy+(XTX+XTX)w^=2XT(Xw^−y)
令上式为零可得
w ^ ∗ = ( X T X ) − 1 X T y \begin{aligned} \boldsymbol {\hat{w}}^* &= (\mathbf X^{\mathrm{T}}\mathbf X)^{-1} \mathbf X^{\mathrm{T}} \boldsymbol{y} \end{aligned} w^∗=(XTX)−1XTy
最终线性回归模型为
f ( x i ^ ) = x i ^ T ( X T X ) − 1 X T y \begin{aligned} f (\boldsymbol {\hat{x_i}}) &= \boldsymbol {\hat{x_i}}^{\mathrm{T}}(\mathbf X^{\mathrm{T}}\mathbf X)^{-1} \mathbf X^{\mathrm{T}} \boldsymbol{y} \end{aligned} f(xi^)=xi^T(XTX)−1XTy
简写为
y = w T x + b y = \boldsymbol w^{\mathrm{T}}\boldsymbol x+b y=wTx+b
对数线性回归,实际上是在试图让 e w T x + b e^{\boldsymbol w^{\mathrm{T}}\boldsymbol x+b} ewTx+b 逼近 y y y 。形式上仍为线性回归,但实质上已是在求取输入空间到输出空间的非线性函数映射。
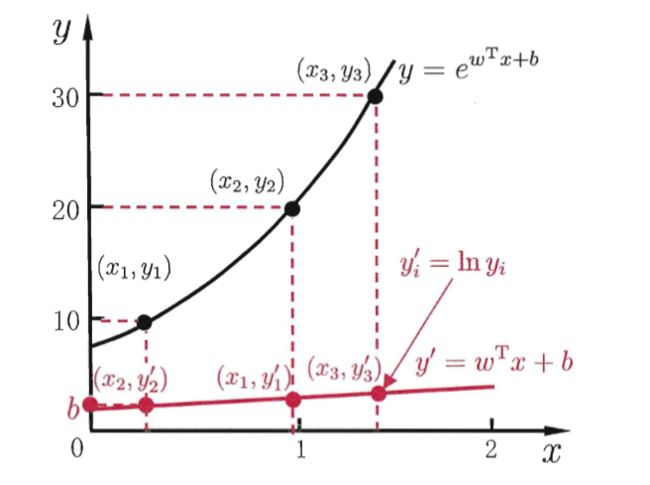
广义线性模型
y = g − 1 ( w T x + b ) y = g^{-1}(\boldsymbol w^{\mathrm{T}}\boldsymbol x+b) y=g−1(wTx+b)
其中函数 g ( ⋅ ) g(·) g(⋅) 称为联系函数,对数线性回归是广义线性模型在 g ( ⋅ ) = l n ( ⋅ ) g(·) = ln(·) g(⋅)=ln(⋅) 时的特例。
3.3 对数几率回归 57
对数几率函数是一种“Sigmoid函数”
y = 1 1 + e − x y=\frac {1}{1+e^{-x}} y=1+e−x1
对数几率
ln y 1 − y \ln \frac {y}{1-y} ln1−yy
3.4 线性判别分析 60
线性判别分析(LDA)是一种经典的线性学习方法:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。

3.5 多分类学习 63
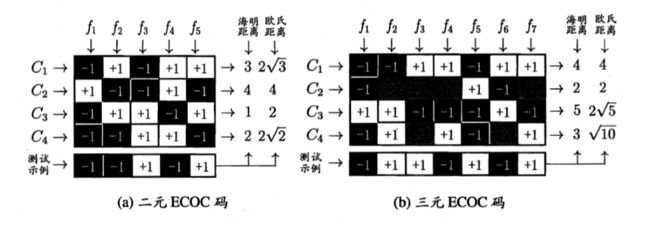
多分类通过ECOC编码进行拆分。
3.6 类别不平衡问题 66
类别不平衡是指分类任务中不同类别的训练样例差别很大的情况。
当正反例可能性相同时,若 y 1 − y > 1 \frac{y}{1-y}>1 1−yy>1 则 预测为正例;反之,令 m + m^+ m+ 表示正例数目, m − m^- m− 表示反例数目,若 y 1 − y > m + m − \frac{y}{1-y}>\frac{m^+}{m^-} 1−yy>m−m+ 则 预测为正例。
再缩放
y ′ 1 − y ′ = y 1 − y × m − m + \frac{y'}{1-y'}=\frac{y}{1-y}\times\frac{m^-}{m^+} 1−y′y′=1−yy×m+m−
欠采样:去除一些反例使得正、反例数目接近,然后再进行学习。
过采样:增加一些正例使得正、反例数目接近,然后再进行学习。
阈值移动:直接基于原始数据集进行学习,但在用训练好的分类器进行预测时,将再缩放嵌入到决策过程中。