Reinforcement Learning强化学习系列之三:MC Control
引言
前面一篇文章中说到了MC prediction,主要介绍的是如何利用采样轨迹的方法计算Value函数,但是在强化学习中,我们主要想学习的是Q函数,也就是计算出每个state对应的action以及其reward值,在这篇文章中,将会介绍。
MC control with epsilon-greedy
这一部分将会介绍基于 ϵ−greedy ϵ − g r e e d y 方法,所谓 ϵ−greedy ϵ − g r e e d y 方法,就是对于当前策略,我们以 1−epsilon 1 − e p s i l o n 的概率选择当前策略所要执行的动作A,以 ϵ ϵ 的概率随机执行其他的动作,对于动作状态空间有 |A| | A | 个的状态,其动作执行策略是:
同样,对于上一篇的21点游戏,我们将MC Prediction中的策略替换成现在所使用的 ϵ−greedy ϵ − g r e e d y 策略,那么其算法改变如下:

为此我们将上一篇文章中的策略迭代代码换成如下:
def epsilon_greedy_policy(Q,observation,nA,epsilon):
best_action = np.argmax(Q[observation])
A = np.ones(nA,dtype=np.float32)*epsilon/nA
A[best_action] += 1-epsilon
return A
def MC_Control_with_epsilon_greedy(env,episode_nums,discount_factor=1.0, epsilon=0.1):
env = Blackjack()
Q = defaultdict(lambda:np.zeros(env.nA))
return_sum=defaultdict(float)
return_count=defaultdict(float)
for i_episode in range(1,1+episode_nums):
env._reset()
state = env.observation()
episode=[]
if i_episode % 1000 == 0:
print("\rEpisode {}/{}.".format(i_episode, episode_nums))
sys.stdout.flush()
for i in range(100):
A = epsilon_greedy_policy(Q,state,env.nA,epsilon)
probs = A
action = np.random.choice(np.arange(env.nA),p=probs)
next_state,reward,done = env._step(action)
episode.append((state,action,reward))
if done:
break
else:
state = next_state
seperate_episode = set([(tuple(x[0]), x[1]) for x in episode])
for state,action in seperate_episode:
for idx,e in enumerate(episode):
if e[0]==state and e[1]==action:
first_visit_idx = idx
break
pair = (state,action)
G = sum([e[2]*(discount_factor**i) for i,e in enumerate(episode[first_visit_idx:])])
return_sum[pair]+=G
return_count[pair]+=1.0
Q[state][action]=return_sum[pair]*1.0/return_count[pair]
return Q同样我们迭代500000次,根据所得到的Q函数,计算出每个state的最佳reward值:
for state, actions in Q.items():
action_value = np.max(actions)
V[state] = action_value我们将Value绘制出来:
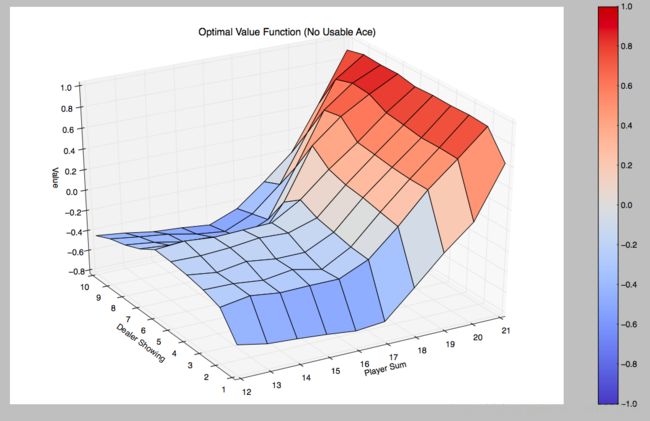
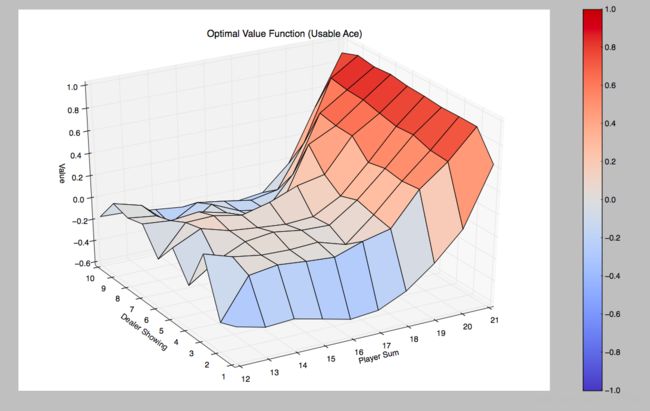
Off-Policy MC control with epsilon-greedy
上面一小节显示的是On-Policy的策略评估方法,所谓On-Policy,也就是执行的策略和要更新的策略是一个策略,而与之相反的是,Off-Policy表示的是执行的策略和更新的策略不是一个策略,在Off-Policy方法里面,执行的策略称之为behavior-policy,而要更新的策略称之为target-policy,如何根据behavior-policy来更新target-policy呢,这里涉及的一个知识点就是重要性采样,所谓重要性采样,就是当我们计算
对于target-policy其计算方式一致,那么target-policy而言,使用behavior-policy采样的比例为:
这个值记为 ρt:T(t)−1 ρ t : T ( t ) − 1
那么在使用behavior-policy的时候,target-policy的Value值可以计算为:
这样我们就可以根据behavior-policy更新得到target-policy的值函数,同理我们也可以得到target-policy的Q函数。我们将上面式子中的 ρt:T(t)−1 ρ t : T ( t ) − 1 替换成 W W ,那么上式子可以表示为:
通过上面式子可以得到如下关系:
其中 Cn+1=Cn+Wn+1 C n + 1 = C n + W n + 1
由此可以得出Off-policy的更新方法:

将MC Control的策略代码修改为:
def sample_policy(Q,observation,nA):
A = np.ones(nA,dtype=np.float32)/nA
return A
def Off_policy_MC_Control(env,episode_nums,discount_factor=1.0):
env = Blackjack()
Q = defaultdict(lambda:np.zeros(env.nA))
target_policy = defaultdict(float)
return_count=defaultdict(float)
for i_episode in range(1,1+episode_nums):
env._reset()
state = env.observation()
episode=[]
prob_b=[]
if i_episode % 1000 == 0:
print("\rEpisode {}/{}.".format(i_episode, episode_nums))
sys.stdout.flush()
for i in range(100):
A = sample_policy(Q,state,env.nA)
probs = A
action = np.random.choice(np.arange(env.nA),p=probs)
next_state,reward,done = env._step(action)
episode.append((state,action,reward))
prob_b.append(probs[action])
if done:
break
else:
state = next_state
seperate_episode = set([(tuple(x[0]), x[1]) for x in episode])
G =0.0
W =1
prob_b=prob_b[::-1]
for idx,eps in enumerate(episode[::-1]):
state,action,reward = eps
pair=(state,action)
G = discount_factor*G+reward
return_count[pair]+=W
Q[state][action]+=W*1.0/return_count[pair]*(G-Q[state][action])
target_policy[state] = np.argmax(Q[state])
if target_policy[state]!=action:
break
W = W*1.0/prob_b[idx]
return Q同样将Value绘制出来,得到的是:
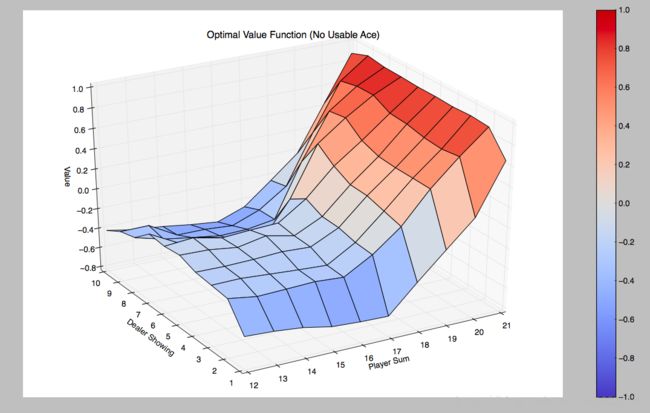
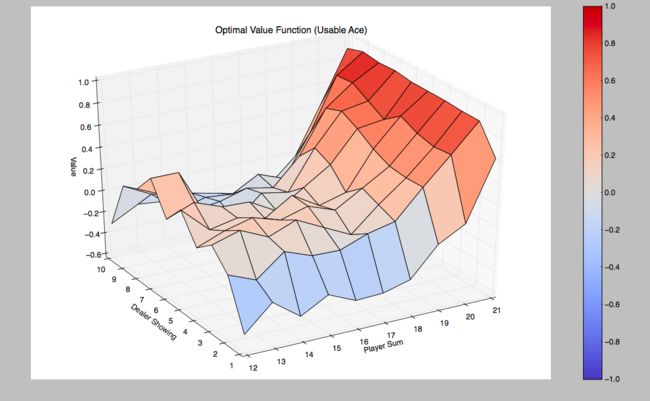
代码在这里可以获取
后记
这两天倒腾完MC之后,感觉强化学习是慢慢入了门,后面还得继续学习,争取能进门吧,下面一个章节是关于TD算法的,也就是时序差分学习,take it easy,记于北京