Inception V1理解及pytorch实现
一、Inception V1
用全局平均池化层代替了最后的全连接层
全连接层几乎占据了中大部分的参数量,会引起过拟合,去除全连接层之后模型可以训练的更快且避免了过拟合的情况。

在Inception v1中1*1卷积用于降维,减少参数量和feature map维度。

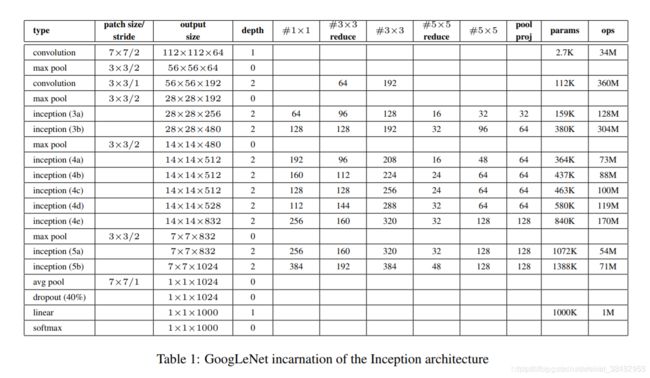
输入28 * 28 * 192的图像,如果直接通过3 * 3 * 256的滤波器(padding=1,stride=1),输出数据是28 * 28 * 256,参数量是192 * 3 * 3 * 256=44w;如果我们在3*3的滤波器前插入一个1 *1 * 64的滤波器实现降维,在通过3 * 3 * 256的滤波器,输出数据是28 * 28 * 256,参数量是192 * 1 * 1 * 64 + 64 * 3 * 3 * 256 = 16w,参数量减少将近1/3
采用不同大小的卷积核,意味着不同大小的感受野,这样可以增加网络对不同尺度的适应性。最后拼接意味着不同尺度特征的融合。


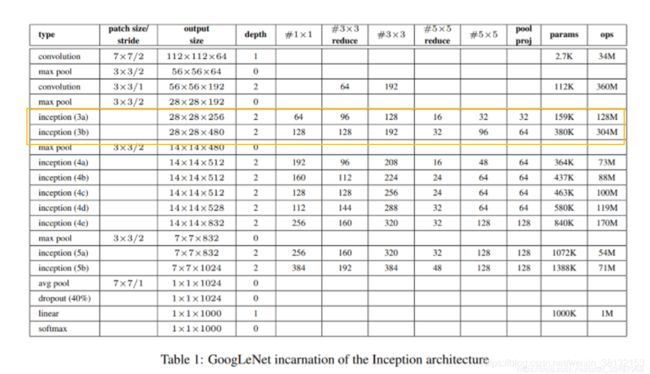
GoogleNet(v1)的完整结构图
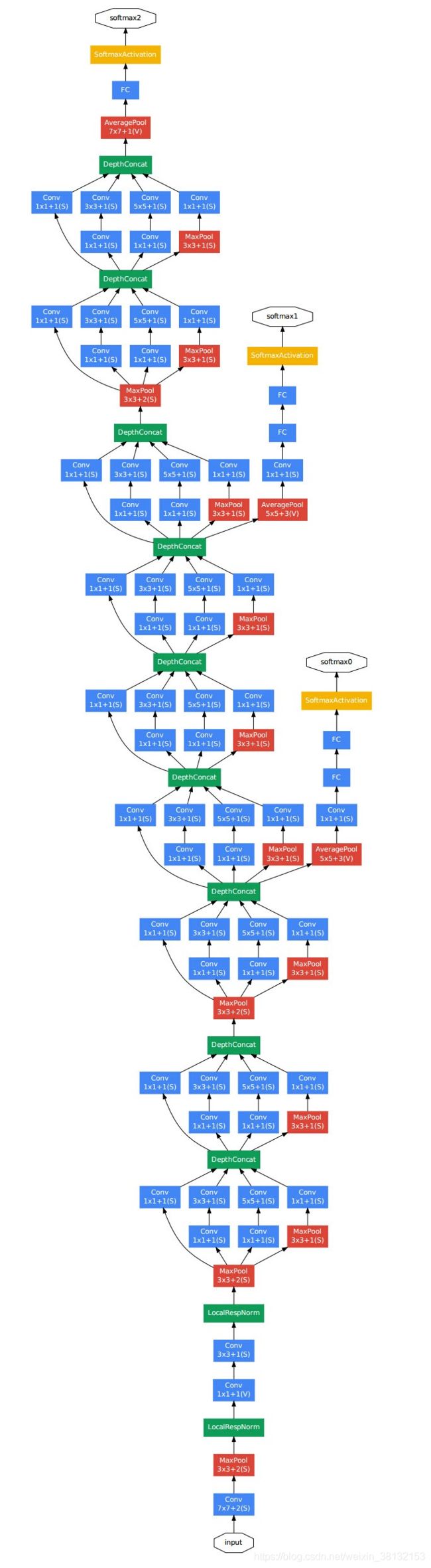
import torch
import torch.nn as nn
# Inception模块
class Block(nn.Module):
def __init__(self, in_channels, out_chanel_1, out_channel_3_reduce, out_channel_3,
out_channel_5_reduce, out_channel_5, out_channel_pool):
super(Block, self).__init__()
block = []
self.block1 = nn.Conv2d(in_channels=in_channels, out_channels=out_chanel_1, kernel_size=1)
block.append(self.block1)
self.block2_1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channel_3_reduce, kernel_size=1)
self.block2 = nn.Conv2d(in_channels=out_channel_3_reduce, out_channels=out_channel_3, kernel_size=3, padding=1)
block.append(self.block2)
self.block3_1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channel_5_reduce, kernel_size=1)
self.block3 = nn.Conv2d(in_channels=out_channel_5_reduce, out_channels=out_channel_5, kernel_size=3, padding=1)
block.append(self.block3)
self.block4_1 = nn.MaxPool2d(kernel_size=3,stride=1,padding=1)
self.block4 = nn.Conv2d(in_channels=in_channels, out_channels=out_channel_pool, kernel_size=1)
block.append(self.block4)
# self.incep = nn.Sequential(*block)
def forward(self, x):
out1 = self.block1(x)
out2 = self.block2(self.block2_1(x))
out3 = self.block3(self.block3_1(x))
out4 = self.block4(self.block4_1(x))
out = torch.cat([out1, out2, out3, out4], dim=1)
print(out.shape)
return out
# 在完整网络中间某层输出结果以一定的比例添加到最终结果分类
class InceptionClassifiction(nn.Module):
def __init__(self, in_channels,out_channels):
super(InceptionClassifiction, self).__init__()
self.avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=128, kernel_size=1)
self.linear1 = nn.Linear(in_features=128 * 4 * 4, out_features=1024)
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=0.7)
self.linear2 = nn.Linear(in_features=1024, out_features=out_channels)
def forward(self, x):
x = self.conv1(self.avgpool(x))
x = x.view(x.size(0), -1)
x= self.relu(self.linear1(x))
out = self.linear2(self.dropout(x))
return out
class InceptionV1(nn.Module):
def __init__(self, num_classes=1000, stage='train'):
super(InceptionV1, self).__init__()
self.stage = stage
self.blockA = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3),
nn.MaxPool2d(kernel_size=3,stride=2, padding=1),
nn.LocalResponseNorm(64),
)
self.blockB = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1, stride=1),
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1),
nn.LocalResponseNorm(192),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.blockC = nn.Sequential(
Block(in_channels=192,out_chanel_1=64, out_channel_3_reduce=96, out_channel_3=128,
out_channel_5_reduce = 16, out_channel_5=32, out_channel_pool=32),
Block(in_channels=256, out_chanel_1=128, out_channel_3_reduce=128, out_channel_3=192,
out_channel_5_reduce=32, out_channel_5=96, out_channel_pool=64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
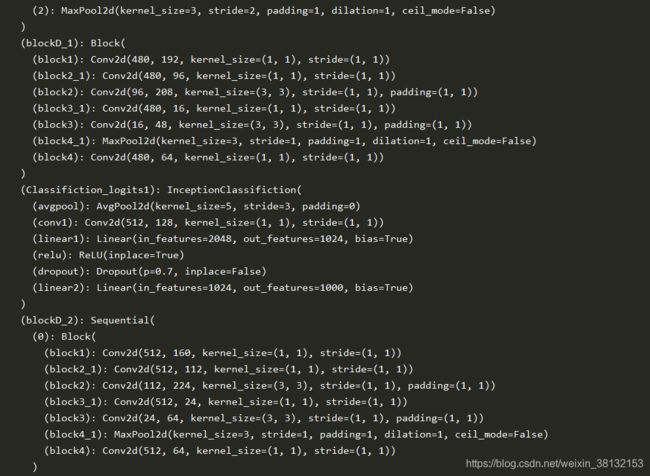
self.blockD_1 = Block(in_channels=480, out_chanel_1=192, out_channel_3_reduce=96, out_channel_3=208,
out_channel_5_reduce=16, out_channel_5=48, out_channel_pool=64)
if self.stage == 'train':
self.Classifiction_logits1 = InceptionClassifiction(in_channels=512,out_channels=num_classes)
self.blockD_2 = nn.Sequential(
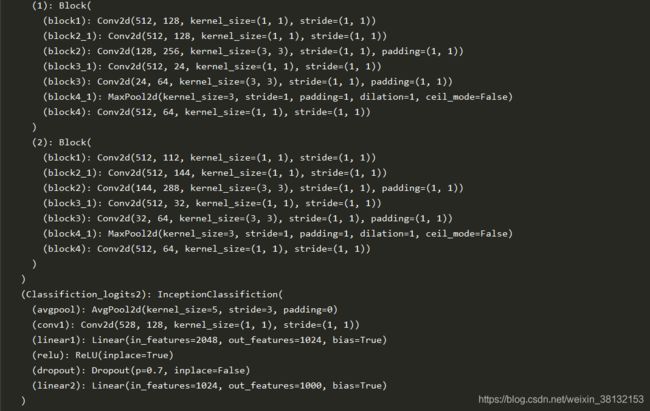
Block(in_channels=512, out_chanel_1=160, out_channel_3_reduce=112, out_channel_3=224,
out_channel_5_reduce=24, out_channel_5=64, out_channel_pool=64),
Block(in_channels=512, out_chanel_1=128, out_channel_3_reduce=128, out_channel_3=256,
out_channel_5_reduce=24, out_channel_5=64, out_channel_pool=64),
Block(in_channels=512, out_chanel_1=112, out_channel_3_reduce=144, out_channel_3=288,
out_channel_5_reduce=32, out_channel_5=64, out_channel_pool=64),
)
if self.stage == 'train':
self.Classifiction_logits2 = InceptionClassifiction(in_channels=528,out_channels=num_classes)
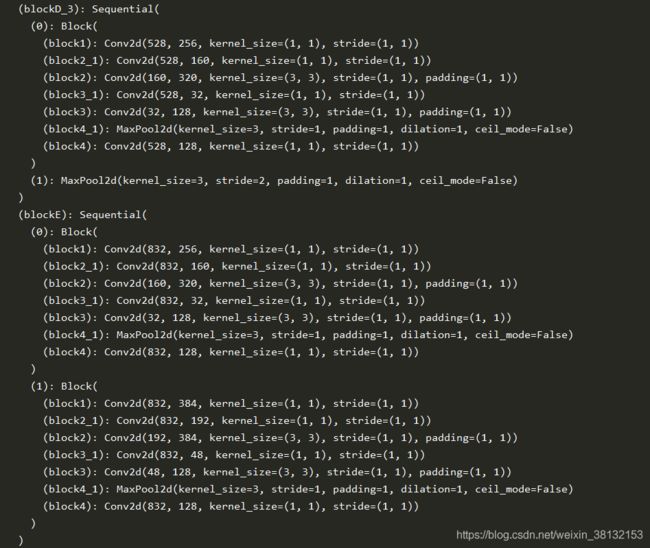
self.blockD_3 = nn.Sequential(
Block(in_channels=528, out_chanel_1=256, out_channel_3_reduce=160, out_channel_3=320,
out_channel_5_reduce=32, out_channel_5=128, out_channel_pool=128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.blockE = nn.Sequential(
Block(in_channels=832, out_chanel_1=256, out_channel_3_reduce=160, out_channel_3=320,
out_channel_5_reduce=32, out_channel_5=128, out_channel_pool=128),
Block(in_channels=832, out_chanel_1=384, out_channel_3_reduce=192, out_channel_3=384,
out_channel_5_reduce=48, out_channel_5=128, out_channel_pool=128),
)
self.avgpool = nn.AvgPool2d(kernel_size=7,stride=1)
self.dropout = nn.Dropout(p=0.4)
self.linear = nn.Linear(in_features=1024,out_features=num_classes)
def forward(self, x):
x = self.blockA(x)
x = self.blockB(x)
x = self.blockC(x)
Classifiction1 = x = self.blockD_1(x)
Classifiction2 = x = self.blockD_2(x)
x = self.blockD_3(x)
out = self.blockE(x)
out = self.avgpool(out)
out = self.dropout(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
if self.stage == 'train':
Classifiction1 = self.Classifiction_logits1(Classifiction1)
Classifiction2 = self.Classifiction_logits2(Classifiction2)
return Classifiction1, Classifiction2, out
else:
return out
model = InceptionV1()
print(model)
input = torch.randn(8, 3, 224, 224)
Classifiction1, Classifiction2, out = model(input)
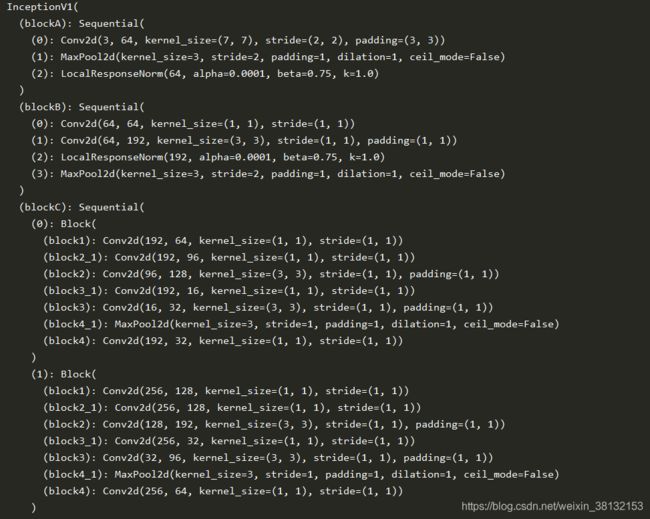

二、Inception V2
在网络中去除LRN,加上BN,并且去除Dropout,因为BN有regularization的作用。
关于BN的理解可以看我之前的文章:一键到达