Scrapy爬取CSDN博客列表
title: Scrapy爬取CSDN博客列表
date: 2019-08-16 13:48:43
tags: 爬虫
categories: Python
新建Scrapy爬虫项目
如果你还没有安装Scrapy,可以通过下面这个命令安装
```
pip install scrapy
```
新建一个项目
安装好之后就可以创建项目了
scrapy startproject 你的项目名
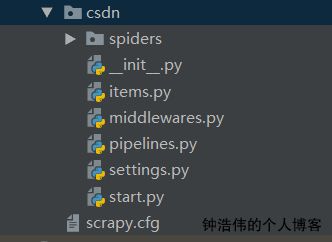
创建好之后的目录如上图所示
每个文件的具体作用可以参照Scrapy的官方文档,这里就不再赘述。
新建一个爬虫
通过命令
scrapy genspider 你的爬虫名
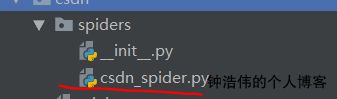
设置配置文件
如果你不需要存入数据库或者做进一步的反爬处理,则可以跳过这一步,打开setting.py进行以下修改
设置浏览器名
把BOT_NAME设置为你的浏览器名,如果使用默认,别人一看就知道是爬虫
BOT_NAME = 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'
设置日志级别
这样就不需要打印太多日志信息,干扰视线
LOG_LEVEL='WARN'
设置模式
将机器人模式设为FALSE
ROBOTSTXT_OBEY = False
设置你要抓取的博客页数
#博客页数
CsdnPage = 2;
设置你的数据库
为了方便将数据自动导入数据库,需要设置数据库配置信息,我使用的是mysql
#数据库设置
MYSQL_HOST = '你的主机名'
MYSQL_PORT = 3306 #端口
MYSQL_DBNAME = 'DBNAME' # 数据库名
MYSQL_TABLE = 'TABLE_NAME' #表名
MYSQL_USER = '你的用户名'
MYSQL_PASSWD='你的密码'
新建数据项
数据项的作用是方便scrapy以结构化的数据插入到数据库中。
打开 items.py,复制一下代码即可,或者你如果要爬新的数据,请记得加入新的字段
import scrapy
class CsdnItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
url = scrapy.Field()
#date = scrapy.Field()
tag = scrapy.Field()
pass
编写爬虫文件
import scrapy
from ..items import CsdnItem
from ..settings import CsdnPage
class CsdnSpiderSpider(scrapy.Spider):
name = 'csdn_spider'
allowed_domains = ['blog.csdn.net']
start_urls = ['https://blog.csdn.net/weixin_41154636/article/list/1']
def parse(self, response):
try:
for div in response.xpath('//div[contains(@class,"article-item-box")]'):
item = CsdnItem()
item['title'] = div.xpath('./h4/a/text()')[1].extract().strip()
item['url'] = div.xpath('./h4/a/@href')[0].extract().strip()
item['tag'] = item['url'].split('/')[-1] # 爬取时间戳,方便按时间排序
# item['date'] = div.xpath('//span[@class="date"]/text()')[1].extract().strip()
# 我也不知道为什么抓出来会有这个- -,所以特殊处理一下
if item['title'] == '帝都的凛冬':
continue
# 控制台输出
print(item['title'] + " " + item['url'] + " " + item['tag'])
# 封装成bean,装入数据库
yield item
# 实现翻页的功能
for page in range(2, CsdnPage + 1):
url = "https://blog.csdn.net/weixin_41154636/article/list/%s" % page
yield scrapy.Request(url, callback=self.parse)
except BaseException:
print(BaseException.__cause__)
pass
具体代码的说明注释已经写得很清楚了。
另外,需要注意的是,因为CSDN的翻页是通过ajax请求实现的,所以需要自己构造请求。
如果发现跑不起来,很可能是因为CSDN的HTML结构发生了改变,你可以了解一下XPATH的写法,然后修改即可。
先看下运行结果吧:
进入到spiders目录中运行
scrapy crawl csdn_spider #你的爬虫名,在上面的代码最开始定义的
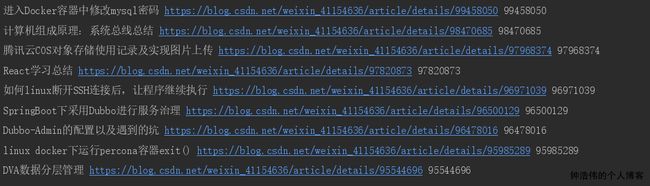
DONE!信息已经爬下来了,接下来就是把数据保存至数据库中。
保存数据至数据库
在setting.py中,把pipeline注释去掉
ITEM_PIPELINES = {
'csdn.pipelines.CsdnPipeline': 300,
}
在piplines.py中编写一下代码:
import pymysql
from scrapy.utils.project import get_project_settings
from twisted.enterprise import adbapi
from .items import CsdnItem
class DBHelper:
def __init__(self):
self.settings = get_project_settings() # 获取settings配置数据
dbparams = dict(
host=self.settings['MYSQL_HOST'], # 读取settings中的配置
db=self.settings['MYSQL_DBNAME'],
user=self.settings['MYSQL_USER'],
passwd=self.settings['MYSQL_PASSWD'],
charset='utf8', # 编码要加上,否则可能出现中文乱码问题
cursorclass=pymysql.cursors.DictCursor,
use_unicode=False,
)
# **表示将字典扩展为关键字参数,相当于host=xxx,db=yyy....
dbpool = adbapi.ConnectionPool('pymysql', **dbparams)
self.dbpool = dbpool
def connect(self):
return self.dbpool
# 插入数据
def insert(self, item):
self.settings = get_project_settings() # 获取settings配置数据
if isinstance(item, CsdnItem):
tb_name = self.settings['MYSQL_TABLE']
sql = """insert into """ + tb_name + """(id,title,link) values (%s,%s,%s) """
# print(sql)
# 调用插入的方法
query = self.dbpool.runInteraction(self._conditional_insert, sql, item)
# 调用异常处理方法
query.addErrback(self._handle_error)
return item
# 写入数据库中
def _conditional_insert(self, canshu, sql, item):
# 取出要存入的数据,这里item就是爬虫代码爬下来存入items内的数据
if isinstance(item, CsdnItem):
import datetime
# 字符串转为DateTime类型
# dateTime_p = datetime.datetime.strptime(item['date'], '%Y-%m-%d %H:%M:%S')
params = (
item['tag'], item['title'], item['url'])
canshu.execute(sql, params)
# 错误处理方法
def _handle_error(self, failue):
pass
print('--------------database operation exception!!-----------------')
# self.connect.rollback()
print(failue)
# 这里执行scrapy处理脚本
class CsdnPipeline(object):
def __init__(self):
self.db = DBHelper()
def process_item(self, item, spider):
# 插入数据库
self.db.insert(item)
return item
具体说明注释已经写的很清楚了。
这样就完成了导入至数据库的工作
再次运行爬虫。
scrapy crawl csdn_spider
可以看到,数据就全部自动导入到数据库了!
