redis介绍及spring data redis方法总结
越来越发现包括redis在内的非关系型数据库在工作实现中重要性。利用redis做数据的缓存处理、防止对数据库的恶意攻击等都有很大帮助。在这里做个redis的系统介绍,和常用方法总结,供以后参看并和朋友们分享。
Redis安装请自行百度,本篇文章redis部署在window10专业版上,且添加在了window服务进程当中,还有用到redis的桌面化工具redis-desktop-manager-0.8.8.384。在这里附上我用的工具包
目录
Redis介绍
键值(key-value)数据类型简介
SpringDataRedis总结
java使用redis需要导入的包
配置
不同类型数据的操作
String
List
set
zset
Hash
redis和json
总结
Redis介绍
要介绍Redis就要先说说非关系型数据库NOSQL,NOSQL,即non-relational或者Not Only StrucStructured Query Language(两者都是非关系型数据库的意思,后者更为通俗),其这样的名字主要是为了区分于常规的SQL(结构化查询语言)。NOSQL的诞生是为了解决Web2.0时代大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。NOSQL没有一个明确的范围和定义,但都普遍存在易扩展、大数据量、高性能、高可用、灵活的数据模型等几个特点。Redis作为非关系型数据库的一种,其自然也包含非关系型数据库普遍拥有的特点。
Redis是用C语言编写的一个开源的高性能键值对(key-value)数据库,根据官方提供的测试数据,50个并发100000(十万)个请求,读的速度是110000次/s(十万),写的速度是81000次/s(万),且redis通过提供多种键值数据类型来适应不同场景下的存储需求,redis常用的键值数据类型如下
字符串类型string:key value 类型 最大能存储512M,redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。,
散列类型 hash:hash 是一个键值(key=>value)对集合,特别适合用于存储对象
列表类型 list:list 是链表结构,所有如果在头部和尾部插入数据,性能会非常高,不受链表长度的影响;但如果在链表中插入数据,性能就会越来越差。
集合类型 set:Set 是 string 类型的无序不可重复集合,集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
有序集合类型 sortedset(zset):zset 和 set 一样也是string类型元素的集合,且不允许重复的成员,不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序,zset的成员是唯一的,但分数(score)却可以重复
redis默认端口号是6379
键值(key-value)数据类型简介
|
|
增/改 |
查 |
删 |
| 字符串String |
set key value |
get key |
del key |
| 字符串列表list |
lpush |
lrang key index1 index2 |
lpop/rpop(从左推/从右推) |
| 无序集合set |
sadd |
smembers key |
srem key mebmers[member1 member2] |
| 有序集合sorted set |
zadd key values[value1、value2…] (例:zadd sortlist 5 lisi 10 xiaoming 7 xiaohua 8 xiaogou) | zrang key index1 index2 |
zrem key member |
| 散列(或者叫哈希)hash |
hset key field value (例:hset myhash username peng) |
hget key field ( hget myhash username /*或者*/hgetall myhash ) |
hdel myhash username[fiel1,fiel2,.....] |
| 通用命令 |
keys *(查看所有键) |
exists key(判断键是否存在1,存在,0不存在) |
del key1 key2…(删除指定键) |
|
|
keys key(返回指定的键) |
type key(获取指定键的类型) |
|
SpringDataRedis总结
java使用redis需要导入的包

maven中的坐标
org.springframework.boot spring-boot-starter-data-redis
Spring-data-redis是spring大家族的一部分,提供了在srping应用中通过简单的配置访问redis服务,对reids底层开发包(Jedis, JRedis, and RJC)进行了高度封装,RedisTemplate提供了redis各种操作、异常处理及序列化,支持发布订阅,并对spring 3.1 cache进行了实现。
配置
配置参数:因为创建的是springboot项目,相关配置只需要在application.yml中声明配置即可,注意yml对格式要求极高,包括空格都不能错
spring:
application:
name: user-auth
redis:
host: 127.0.0.1
port: 6379
password:
jedis:
pool:
max-active: 8
max-idle: 8
min-idle: 0
下面写一个demo测试下redis是否连通
package com.heronsbill.redisdemo.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @Author: heronsbill
* @DATA: 2019/10/12
*/
@RestController
@RequestMapping("/redis")
public class RedisDemo01 {
@Autowired
private RedisTemplate redisTemplate;
@GetMapping("/get")
public Object main() {
redisTemplate.boundValueOps("niu").set("11");
redisTemplate.opsForValue().set("muji","不好");
return redisTemplate.opsForValue().get("muji");
}
}
启动springboot项目后,利用postman输入连接http://127.0.0.1:8080/redis/get,最后得到“不好”
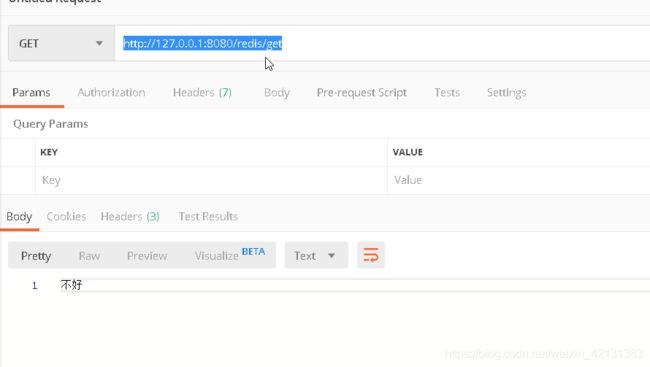
这里要注意一点,RedisTemplate会默认使用JdkSerializationRedisSerializer作为序列化工具,所以存在redis中的数据无论是key还是value前面都有一串特殊符号
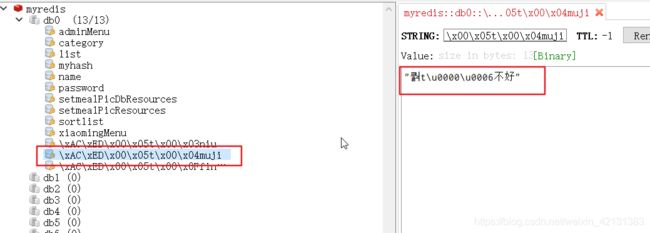
特殊符号是redis默认的序列化方式产生的序列化标记,不影响数据的存取。想取消序列化标记,需要在启动类中配redisTemplate
如下:
/**
* 设置 redisTemplate 的序列化设置
* @param redisConnectionFactory
* @return
*/
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 1.创建 redisTemplate 模版
RedisTemplate template = new RedisTemplate<>();
// 2.关联 redisConnectionFactory
template.setConnectionFactory(redisConnectionFactory);
// 3.创建 序列化类
GenericToStringSerializer genericToStringSerializer = new GenericToStringSerializer(Object.class);
// 6.序列化类,对象映射设置
// 7.设置 value 的转化格式和 key 的转化格式
template.setValueSerializer(genericToStringSerializer);
template.setKeySerializer(new StringRedisSerializer());
template.afterPropertiesSet();
return template;
} 这样,再存取数据,就不会有序列化标记了。到此配置完成。
不同类型数据的操作
关于spring-data-redis其实现了 连接池自动管理,并且提供了一个高度封装的“RedisTemplate”类,里面为数据操作准备了两套方法,一套是ops开头的一套是bound开头的,bound开头的方法需要传key值,里面会对key进行一些初始化的设置,如空值的处理等。其他的区别还在研究中。但是在涉及到多个用户同时操作同一数据时,ops这套方法能够有效锁住数据(类似于单线程操作),bound却不能(类似于多线程操作)。这里两套方法都演示。
String
|
|
bound |
ops |
| 顶级接口 |
|
|
| 增 |
set(Object value) 简单的给键赋值 set(Object value,long l) 给value的第几个字节赋值,空出的位置用x00补位,字母和数字占一个字节汉字占3个字节 set(Object value,Duration timout) 设置当前字符串在redis的有效时间 set(Object value,long l TimeUnit timeUnit) TimeUnit是时间颗粒,秒级,分级等 |
bound有的方法,ops都有 但这里还有一些其他很有用的方法
|
| 查 |
get() getAndSet(Object value) |
get(Object key) getAndSet(Object key,Object value) 获取之前的值,并修改 |
| 删 |
除了删除Key值外,也可以通过设置有效时间为1s实现删除 |
|
| 其他 |
|
|
List
list是链表,所以涉及到的操作着重于头和尾的操作,也就是压栈和出栈
|
|
bound |
ops |
| 顶级接口 |
|
|
| 压栈 |
rightPush(Object value) leftPush(Object value) rightPushAll(Object ... vs) leftPushAll(Object ... vs) rightPushIfPresent(Object value) leftPushIfPresent(Object value) |
|
| 出栈 |
出栈操作类似于压栈操作将push换做pop(ops方法类似) |
|
| 改 |
set(long index,Object value)在第几个位置修改,注意这里不能修改不存在的值(ops方法类似) |
|
| 其他 |
|
|
set
|
|
bound |
ops |
| 顶级接口 |
|
|
| 增 |
add(Object... vs) |
|
| 查 |
members() |
|
| 删 |
remove(Object object)(删除集合里面的单个对象) |
|
| 其他 |
|
|
zset
|
|
bound |
ops |
| 顶级接口 |
|
|
| 方法说明 |
|
|
Hash
hash类型集合适合用来存对象,但是java中的对象类都必须实现序列化接口,而存进redis中的数据也都是序列化后的数据,一串看不懂的字符串,但是不影响操作
|
|
bound |
ops |
| 顶级接口 |
|
|
| 增 |
put(Object hk,Object hv) |
|
| 查 |
get(object hk) |
ops方法类似 |
| 删 |
delete() |
ops方法类似 |
| 其他 |
|
|
redis和json
json作为现在比较流行的数据格式在redis中有重要得作用。在存储数据时往往可以把数据转换为json格式字符串然后存进redis,取出来后在进行解析,或者传给前端使用,都比较方便。这里以阿里出品的fastjson为例讲解
代码为
@GetMapping("/jsonstr")
public Object jsonStr() {
BoundValueOperations jsonstr = redisTemplate.boundValueOps("jsonstr");
// 创建user对象
User user1 = new User(1, "小明", 19);
//将user对象解析为JSON字符串
String s = JSON.toJSONString(user1);
// 将json字符串存进redis
jsonstr.set(s);
// 获取redis中的json字符串
String s1 = jsonstr.get(0, -1);
System.out.println("json字符串"+s1);
// 重新解析为user对象
User user = JSON.parseObject(s1, User.class);
System.out.println("json解析后的user对象"+user);
return user;
}此时存在redis的是json格式的字符串

后台输出结果

当然实际的json操作远不止现在所说的两种,后面会继续总结。
总结
在web2.0时代,数据和流量成为至关重要的一部分,而大数据量的直接访问数据库,势必会带来难以修复大麻烦,而通过redis等一些非关系型数据库作为数据库与用户之间的一个缓存区,大大降低对数据库的直接访问。并且通过redis的中间拦截和判断,也能够阻拦一些恶意的攻击。
redis的学习还要继续。
能力尚浅,有待进步,如有不足,不吝赐教!