class文件结构详细解析
之前一直好奇java文件经过编译后生成的class文件,到底存储了什么信息?是如何被jvm识别并执行的?我们可不可以通过外部力量修改class文件内容,以致可以修改程序的运行?于是我带着种种疑问,开始研究class文件。参考《深入理解Java虚拟机》(周志鹏著)和 oracle官网《java虚拟机规范》。
在深入分析class文件之前,我们先来探讨class文件存在原因:
无关性的基石:Java刚开始诞生时的宣传口号“一次编写,到处运行”,开发者早就料想到,各种不用的硬件体系结构、各种不同的操作系统将来肯定会长期并存发展,实现跨平台的基础就是实现在操作系统之上的应用层——虚拟机和字节码存储格式。Jvm不与包括Java语言在内的任何程序语言绑定,它只与“Class文件”关联。所以说Jvm和Class文件是Java语言的基石。
Class文件详解目录
- class文件结构
- 一、魔数
- 二、版本号
- 三、常量池
- 四、访问标志
- 五、类索引、父类索引和接口索引集合
- 六、字段表集合
- 七、方法表集合
- 八、属性表集合
- 总结
class文件结构
Class文件是一组以8位字节为基础单位的二进制流,内容是以《Java虚拟机规范》规定的一种固定的格式存储数据。存储数据用到了两个数据类型:“无符号数”和“表”。
- 无符号数:无符号数是基本数据类型,以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节的无符号数,无符号数可以用来描述数字、索引引用、数量表或者按照UTF-8编码构成字符串值。
- 表:由多个无符号数或者其他表作为数据项构成的复合数据类型,以“_info”结尾,用户描述有层次关系的复合结构的数据。
下图为《Java虚拟机规范》规定的Class文件的固定格式,所有Class文件均按照一下格式存储内容。(注意:每个class文件内容都是按照以下列表按列表中从上到下顺序组成,如果某些类型不涉及可以为空)
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u4 | magic | 1 | 4 | 魔数 |
| u2 | minor_version | 1 | 2 | 次版本 |
| u2 | major_version | 1 | 2 | 主版本 |
| u2 | constant_pool_count | 1 | 2 | 常量池容量计数值 |
| cp_info | constant_pool | constant_pool_count-1 | 表结构 | 常量池表 |
| u2 | access_flags | 1 | 2 | 类的访问标志 |
| u2 | this_class | 1 | 2 | 类索引 |
| u2 | super_class | 1 | 2 | 父类索引 |
| u2 | interfaces_count | 1 | 2 | 实现接口计数值 |
| u2 | interfaces | interfaces_count | 表结构 | 实现接口结构表 |
| u2 | fields_count | 1 | 2 | 类字段计数值 |
| field_info | fields | fields_count | 表结构 | 字段结构表 |
| u2 | methods_count | 1 | 2 | 类方法计数值 |
| method_info | methods | methods_count | 表结构 | 方法结构表 |
| u2 | attributes_count | 1 | 2 | class的属性数组长度 |
| attribute_info | attributes | attributes_count | 表结构 | 属性结构表 |
查看了表之后,想必大家对表中名称和含义两列表达的意思可以理解,但类型、数量和所占字节三列的内容模糊不太清楚,下面我自己编写一个java代码,javac编译后得到class文件,就自己的demo一一的来详解这三列所表达意思,和详解表中的类型所表达意思。下面请看代码和class文件:
package myCom.clazz;
public class Test {
private int a;
public int inc(){
return a+1;
}
}
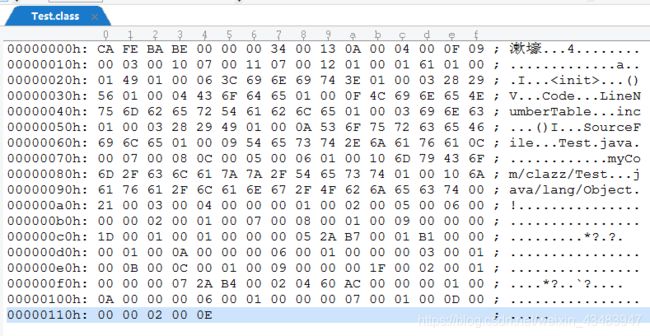
编译后用UEStudio打开class文件,UEStudio会将二进制文件自动转换为16进制,(注意:class文件是二进制流,用UEStudio打开显示的是16进制表示,这里不要误认为class是16进制流文件。下文所有的内容都是基于16进制来表达的)如下图:
一、魔数
查《class文件格式》表可知,class文件内容第一个类型是魔数
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u4 | magic | 1 | 4 | 魔数 |
魔数的类型是u4,u4代表4个字节,数量是1,查看UEStudio打开的16进制class文件,因为class文件格式是按顺序的,魔数是第一类型,从最开始数4个字节也就是角标0~3,如下图“CA FE BA BE”
每个class文件的头4个字节称为魔数,它唯一的作用是确定这个文件是否为一个能被虚拟机接受的Class文件。很多文件存储标准中都使用魔数来进行身份识别,譬如图片格式gif、jpg等。使用魔数而不是拓展名来进行识别主要是基于安全方面的考虑,因为文件拓展格式可以随意改动。
二、版本号
查《class文件格式》表可知,紧接着魔数后面的就是版本号
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | minor_version | 1 | 2 | 次版本 |
| u2 | major_version | 1 | 2 | 主版本 |
版本分为次版本和主版本,每个版本的类型都是u2,也就是都占用2个字节,数量都是1。所以class文件中第5、6个字节是次版本号(Minor Version),第7和第8个字节是主版本号(Major Version)。

由图可知7、8位16进制是0034,对应的10进制是52。下面表格是《Class文件版本号》,对照可知jdk版本是1.8,而我正是用jdk1.8编译的。高版本的JDK可以向下兼容以前版本的Class文件,但是无法运行以后版本的Class文件,即使文件格式并未发生变化,虚拟机也必须拒绝执行超过其版本号的Class文件。java虚拟机向上不兼容就是在虚拟机加载类文件时文件校验的这里。
|
Jdk版本 |
-target参数 |
十六进制Class版本号 |
十进制Class版本号 |
|---|---|---|---|
|
Jdk 1.1.8 |
不能带-target参数 |
00 03 00 2D |
45.3 |
|
Jdk 1.2.2 |
不带(默认为-target 1.1) |
00 03 00 2D |
45.3 |
|
Jdk 1.2.2 |
-target 1.2 |
00 00 00 2E |
46.0 |
|
Jdk 1.3.1_19 |
不带(默认为-target 1.1) |
00 03 00 2D |
45.3 |
|
Jdk 1.3.1_19 |
-target 1.3 |
00 00 00 2D |
47.0 |
|
Jdk 1.4.2_10 |
不带(默认为-target 1.2) |
00 00 00 2F |
46.0 |
|
Jdk 1.4.2_10 |
-target 1.4 |
00 00 00 30 |
48.0 |
|
Jdk 1.5.0_11 |
不带(默认为-target 1.5) |
00 00 00 31 |
49.0 |
|
Jdk 1.5.0_11 |
-target 1.4 -source 1.4 |
00 00 00 30 |
48.0 |
|
Jdk 1.6.0_01 |
不带(默认为-target 1.6) |
00 00 00 32 |
50.0 |
|
Jdk 1.6.0_01 |
-target 1.5 |
00 00 00 31 |
49.0 |
|
Jdk 1.7.0 |
不带(默认为-target 1.7) |
00 00 00 33 |
51.0 |
|
Jdk 1.7.0 |
-target 1.6 |
00 00 00 32 |
50.0 |
|
Jdk 1.7.0 |
-target 1.4 -source 1.4 |
00 00 00 30 |
48.0 |
|
Jdk 1.8.0 |
不带(默认为-target 1.8) |
00 00 00 34 |
52.0 |
三、常量池
查询《Class文件格式表》再往下看,来到了常量池,常量池是由constant_pool_count和constant_pool组成,constant_pool_count占用两个字节,表示的是常量池容量计数值。
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | constant_pool_count | 1 | 2 | 常量池容量计数值 |
| cp_info | constant_pool | constant_pool_count-1 | 数组结构 | 常量池表 |
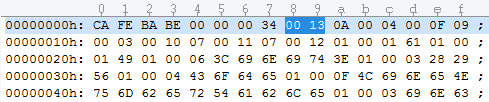
紧挨着版本号后面的两个字节是“0013”,转为十六进制是19。常量池的数量=constant_pool_count-1=18,这就代表常量池中有18项常量,索引值范围是1~18,也就是说每个常量都有个索引值,从class文件中出现的先后顺序,从1~18依次排列(这里提到的索引值,后续讲解每个常量类型表中对应的index值,读到下方的index(索引项),指的就是这里的索引值)。
解释完u2类型的constant_pool_count ,后面的constant_pool的类型是_info,不在前面说的魔数、版本号、常量池技术值的类型u4、u2等无符号数类型,而是_info文章之前所说的存储class数据类型的第二种类型表类型,常量池也是class文件结构中我们遇到的第一个表结构的数据类型。下面我们来详解表结构的常量池类型。
(在分析常量池之前我们需要了解一些概念
常量池中主要存放两大类常量:
1.字面量:比较接近于Java语言层面的常量概念,如文本字符串、被声明为final的常量值等。
2.符号引用:属于编译原理方面的概念,包括被模块导出或者开放的包(Package)、类和接口的权限定名、字段和方法的名称和描述符等
Class文件中不会保存各个方法、字段最终在内存中的布局信息,这些字段、方法的符号引用不经过虚拟机在运行期转换的话是无法得到真正的内存入口地址,也就无法直接被虚拟机使用的。当虚拟机做类的加载时,将会从常量池获得对应的符号引用,再在类创建时或运行时解析、翻译到具体的内存地址之中。)
常量池中每一项常量都是一个表,截止到JDK13《Java虚拟机规范》规定的常量类型有17种结构各不相同表结构数据,下表列出的是11种常见的常量池常量类型表:
| 类型 | 简介 | 项目 | 类型 | 描述 |
|---|---|---|---|---|
CONSTANT_Utf8_info |
utf-8缩略编码字符串 |
tag |
u1 |
值为1 |
| length |
u2 |
utf-8缩略编码字符串占用字节数 |
||
| bytes |
u1 |
长度为length的utf-8缩略编码字符串 |
||
| CONSTANT_Integer_info |
整形字面量 |
tag |
u1 |
值为3 |
| bytes |
u4 |
按照高位在前储存的int值 |
||
| CONSTANT_Float_info |
浮点型字面量 |
tag |
u1 |
值为4 |
| bytes |
u4 |
按照高位在前储存的float值 |
||
| CONSTANT_Long_info |
长整型字面量 |
tag |
u1 |
值为5 |
| bytes |
u8 |
按照高位在前储存的long值 |
||
| CONSTANT_Double_info |
双精度浮点型字面量 |
tag |
u1 |
值为6 |
| bytes |
u8 |
按照高位在前储存的double值 |
||
| CONSTANT_Class_info |
类或接口的符号引用 |
tag |
u1 |
值为7 |
| index |
u2 |
指向全限定名常量项的索引 |
||
| CONSTANT_String_info |
字符串类型字面量 |
tag |
u1 |
值为8 |
| index |
u2 |
指向字符串字面量的索引 |
||
| CONSTANT_Fieldref_info |
字段的符号引用 |
tag |
u1 |
值为9 |
| index |
u2 |
指向声明字段的类或接口描述符CONSTANT_Class_info的索引项 |
||
| index |
u2 |
指向字段描述符CONSTANT_NameAndType_info的索引项 |
||
| CONSTANT_Methodref_info |
类中方法的符号引用 |
tag |
u1 |
值为10 |
| index |
u2 |
指向声明方法的类描述符CONSTANT_Class_info的索引项 |
||
| index |
u2 |
指向名称及类型描述符CONSTANT_NameAndType_info的索引项 |
||
| CONSTANT_InterfaceMethodref_info |
接口中方法的符号引用 |
tag |
u1 |
值为11 |
| index |
u2 |
指向声明方法的接口描述符CONSTANT_Class_info的索引项 |
||
| index |
u2 |
指向名称及类型描述符CONSTANT_NameAndType_info的索引项 |
||
| CONSTANT_NameAndType_info |
字段或方法的部分符号引用 |
tag |
u1 |
值为12 |
| index |
u2 |
指向该字段或方法名称常量项的索引 |
||
| index |
u2 |
指向该字段或方法描述符常量项的索引 |
查表后,发现这11类表都有一个共同的特点,表结构起始的第一位都是个u1类型的标志位(tag,取表中描述列的值),下面就我们的demo来分析一个常量类型:
紧接着constant_pool_count常量池数量“0013”后面的第一个标志位tag是0A,转换为16进制是10,对应常量类型表中的CONSTANT_Methodref_info(类中方法的符号引用),查表可知,紧接着的u2类型的index(指向声明方法的类描述符CONSTANT_Class_info的索引值,看下图可知“0A”后面的两个字节是“0004”,也就是说这个4指向的是常量池中第四个常量Class_info类型),下面的u2类型index(指向名称及类型描述符CONSTANT_NameAndType_info的索引值,“000F”16进制是15,index指向的是常量池中第15个NameAndType_info类型常量),看下图
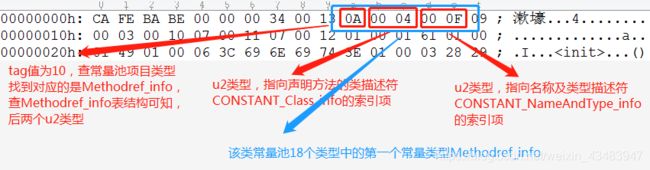
下图是该class文件中常量池中所有的常量,每一个线段代表一个常量,正好是18个线段,与之前的constant_pool_count常量池数量“0013”吻合。

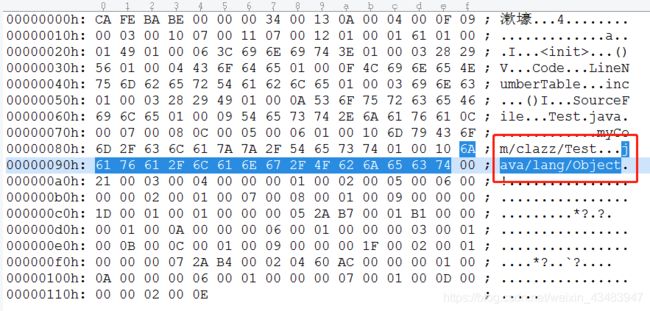
接下来我们接着分析第一个常量类型“0A 0004 000F”的index“0004”,指向的常量池中第四个类型,由上图可知字节码是“07 0012”,tag“07”查常量池的项目类型表确实Class_info类型,如下表:
| 类型 | 简介 | 项目 | 类型 | 描述 |
|---|---|---|---|---|
| CONSTANT_Class_info |
类或接口的符号引用 |
tag |
u1 |
值为7 |
| index |
u2 |
指向全限定名常量项的索引 |
四、访问标志
查《class文件格式》表可知,紧接着常量池后面的就是访问标志(access_flags)
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | access_flags | 1 | 2 | 类的访问标识 |
u2类型,占用2个字节,这个标志用于识别一些类或者接口层次的访问信息(这里是类的访问标志,下文还会提及到字段访问标志,注意区分),具体的标志位及其含义详见下表:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x00 01 | 是否为Public类型 |
| ACC_FINAL | 0x00 10 | 是否被声明为final,只有类可以设置 |
| ACC_SUPER | 0x00 20 | 是否允许使用invokespecial字节码指令的新语义(jdk1.0.2版本后该标志位为真) |
| ACC_INTERFACE | 0x02 00 | 标志这是一个接口 |
| ACC_ABSTRACT | 0x04 00 | 是否为abstract类型,对于接口或者抽象类来说,次标志值为真,其他类型为假 |
| ACC_SYNTHETIC | 0x10 00 | 标志这个类并非由用户代码产生 |
| ACC_ANNOTATION | 0x20 00 | 标志这是一个注解 |
| ACC_ENUM | 0x40 00 | 标志这是一个枚举 |
我上文中所写的demo是一个普通的java类,并不是接口、枚举、注解或者模块,被public修饰,但没有被final、abstract修饰,不符合表中含义的不取值,所以查表符合表中的只有ACC_PUBLIC和ACC_SUPER,所以access_flags:0x0001 | 0x0020 = 0x0021

五、类索引、父类索引和接口索引集合
查《class文件格式》表可知,紧接着访问标志后面的就是类索引、父类索引、实现接口计数值
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | this_class | 1 | 2 | 类索引 |
| u2 | super_class | 1 | 2 | 父类索引 |
| u2 | interfaces_count | 1 | 2 | 实现接口计数值 |
| u2 | interfaces | interfaces_count | 表结构 | 实现接口结构表 |
this_class、super_class、interfaces_count这三项都按顺序的排列在访问标志之后,由他们来确定class文件的继承和实现关系。this_class和super_class用两个u2类型的索引值表示,他们各自指向一个类型为CONTSTANT_Class_info的类描述符常量,通过CONSTANT_Class_info类型的常量中的索引值可以找打定义在CONSTANT_Utf-8_info类型的常量中的字符串。如下图:
index:0003
index:0011
length:16
bytes:myCom/clazz/Test

类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名。由于java语言不允许多重继承,所以父类索引只有一个,除了Object之外,所有的java类都有父类,因此除了Object外,所有java类的父类索引都不为0。实现接口计数值的字节码是“00 00”,所以实现了0个接口,那么后面的实现接口结构表也就不存在了。
六、字段表集合
查《class文件格式》表可知,紧接着接口结构表后面的就是字段表集合
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | fields_count | 1 | 2 | 类字段计数值 |
| field_info | fields | fields_count | 表结构 | 字段结构表 |
字段表集合查表后得到,一个u2类型的“类字段计数值”和表结构的“字段结构表”组成。是用来描述接口或者类中声明的变量,包括类级变量以及实例级变量,但不包括在方法内部的局部变量。u2的field_count好理解就是类中声明了多少个变量,值就是多少;那表结构field_info到底是什么样子的,都有什么属性来修饰变量呢,来看下面的字段表结构:
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | access_flags | 1 | 2 | 字段访问标志 |
| u2 | name_index | 1 | 2 | 字段的名称索引 |
| u2 | descriptor_index | 1 | 2 | 字段描述符索引 |
| u2 | attribute_count | 1 | 2 | 属性计数值 |
| attribute_info | attributes | attribute_count | 表结构 | 属性表 |
u2的字段的修饰符access_flags和前面所学的类的访问标志(access_flags)类似,下面表中信息是该access_flags的标志位和含义:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x00 01 | 是否为Public类型 |
| ACC_PRIVATE | 0x00 02 | 是否为Private类型 |
| ACC_PROTECTED | 0x00 04 | 是否为Protected类型 |
| ACC_STATIC | 0x00 08 | 是否为static类型 |
| ACC_FINAL | 0x00 10 | 是否被声明为final |
| ACC_VOLATILE | 0x00 40 | 是否被声明为volatile |
| ACC_TRANSIENT | 0x00 80 | 是否被声明为transient |
| ACC_SYNTHETIC | 0x10 00 | 标志这个字段并非由用户代码产生 |
| ACC_ENUM | 0x40 00 | 标志这是一个枚举 |
下面结合demo一一介绍这5个类型,如下图:
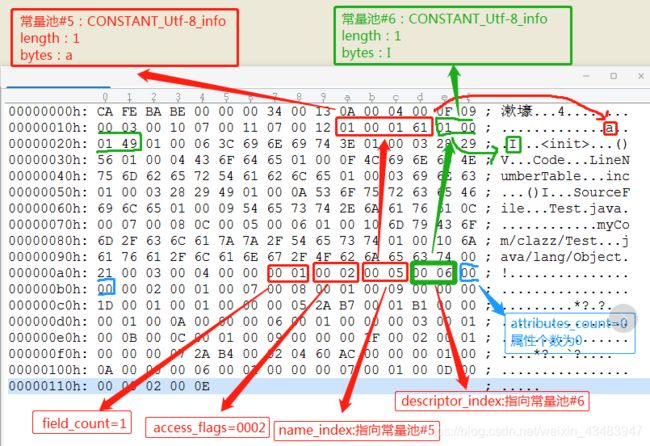
1.field_count:“0001”,字段计数值为1,代表有一个变量;
2.access_flags=0x0002(查表可知是private);
3.name_index指向常量池第5个常量,第5个常量是一个utf-8的字符串类型,指向是的“a”,说明字段名称是a;
4.descriptor_index指向常量池第6个常量,第6个常量是一个utf-8的字符串类型,指向是的“I”;
5.attribute_count:”0000“;说明字段属性为0(这里属性先不介绍,后文会详细介绍)
这几个类型除了描述符”I“的含义,其他都好理解。那来说说描述符:描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,定义了如下规则表(此规则表和下面即将提到的”方法的描述符“共用一套规则),查表可知”I“描述符,代表的就是int类型的字段。由此我们就能推断出这个字段的含义:private int a;正好和之前的Test.java中定义的一样。(字段表集合中不会出现从父类或者父类接口中继承而来的字段)
| 标志字符 | 含义 |
|---|---|
| B | 基本类型byte |
| C | 基本类型char |
| D | 基本类型double |
| F | 基本类型float |
| I | 基本类型int |
| J | 基本类型long |
| S | 基本类型short |
| Z | 基本类型boolean |
| V | 特殊类型void,这里的void和返回值类型void不是同义。这里的V既包含返回值类型void,又包含无返回值的类型,比如实例构造器 |
| L | 对象类型,如Ljava/lang/Object |
七、方法表集合
查《class文件格式》表可知,紧接着字段表后面的就是方发表,和字段表集合一样,计数值后面接一个方法结构表
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | methods_count | 1 | 2 | 类方法计数值 |
| method_info | methods | methods_count | 表结构 | 方法结构表 |
方法表结构和字段表结构一模一样,见下表:依次是访问标志(access_flags)、名称索引(name_index)、描述符索引(descriptor_index)、属性表集合(attributes)几项
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | access_flags | 1 | 2 | 方法访问标志 |
| u2 | name_index | 1 | 2 | 方法的名称索引 |
| u2 | descriptor_index | 1 | 2 | 方法描述符索引 |
| u2 | attribute_count | 1 | 2 | 属性计数值 |
| attribute_info | attributes | attribute_count | 表结构 | 属性表 |
我们来看看这里的访问标志和类、字段的访问标志有什么不同,如下:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x00 01 | 是否为Public类型 |
| ACC_PRIVATE | 0x00 02 | 是否为Private类型 |
| ACC_PROTECTED | 0x00 04 | 是否为Protected类型 |
| ACC_STATIC | 0x00 08 | 是否为static类型 |
| ACC_FINAL | 0x00 10 | 是否被声明为final |
| ACC_SYNCHRONIZED | 0x00 20 | 是否被声明为synchronized |
| ACC_BRIDGE | 0x00 40 | 方法是不是由编译器产生的桥接方法 |
| ACC_VARARGS | 0x00 80 | 方法是否接受不定参数 |
| ACC_NATIVE | 0x01 00 | 方法是否为native |
| ACC_ABSTRACT | 0x04 00 | 方法是否为abstract |
| ACC_STRICT | 0x08 00 | 方法是否为strictfp |
| ACC_SYNTHETIC | 0x10 00 | 标志这个方法并非由用户代码产生,由编译器自动产生 |
我们就我们demo实例来研究方法表集合,如下图:我们来看中间红色方框映射出去的解释一一涵盖了方法表集合的类型。想必大家看完后会有疑问:各个类型的含义和具体指向都能理解,可是具体对应的结果值肯定会不懂,比如:method_count=2,demo中只定义了一个方法,方法名是"
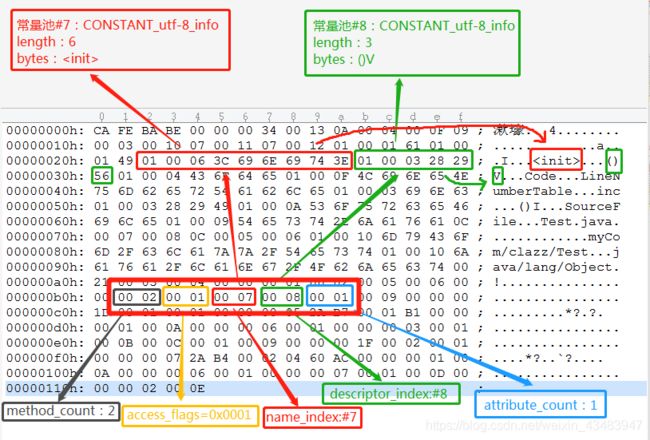
(注意:与字段表集合相对应地,如果父类方法在子类中没有被重写,方法表集合中就不会出现来自父类的方法信息。有可能会出现由编译器自动添加的方法,最常见的就是实例构造器
八、属性表集合
查《class文件格式》表可知,紧接着字段表后面的就是属性表,同时我们在字段表和方法表集合中都携带自己的属性表集合,属性表集合也是u2类型的计数值和结构表组成,如下:
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | attributes_count | 1 | 2 | 属性计数值 |
| attribute_info | attributes | attributes_count | 表结构 | 属性结构表 |
属性表结构:
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | attribute_name_index | 1 | 2 | 属性名索引 |
| u4 | attribute_length | 1 | 4 | 属性长度 |
| u1 | info | 1 | attribute_length | 属性 |
属性表集合不同于其他数据类型,因为Class文件、字段表集合、方法表集合都可以携带自己的属性表集合,最开始《java虚拟机规范》定义了9项属性,后来到了java SE12版本增加到了29项(如需了解更多属性详情请参考《java虚拟机规范-属性》)。由于每个属性的表结构都不相同,使用位置也不同,篇幅有限就不罗列出各个属性的表结构,结合demo将对关键的、常用的属性进行讲解,我们接着方法表集合中未分析的属性来研究,如下图:
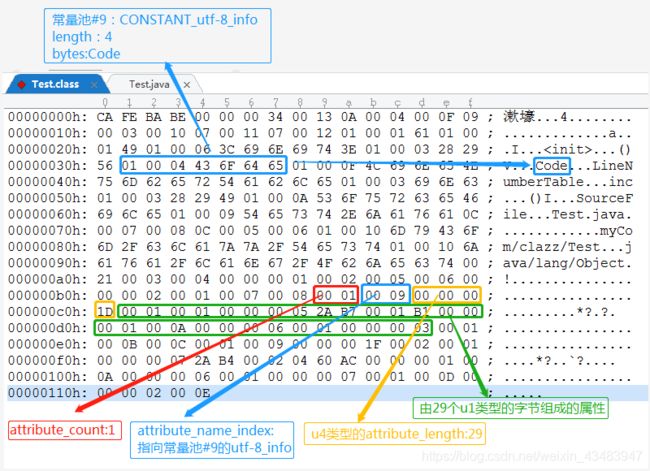
由属性名字索引指向常量池第9个字符串常量,我们可知该属性为“Code”属性,虚拟机规范规定code属性,使用位置在方法表,含义是java代码编译成的字节码指令 Java程序方法体内里面的代码经过javac编译器处理后,最终变为字节码指令存储在Code属性内。 属性长度为29,那么这29个u1字节什么含义呢,下面我们来看看Code属性表结构,如下表:
| 类型 | 名称 | 数量 | 占用字节数 | 含义 |
|---|---|---|---|---|
| u2 | max_stack | 1 | 2 | 表示最大的操作数栈的深度 |
| u2 | max_locals | 1 | 2 | 表示局部变量表存储的空间 |
| u4 | code_length | 1 | 4 | 代表字节码长度 |
| u1 | code | code_length | 1 | 存储字节码指令的字节流 |
| u2 | exception_table_length | 1 | 2 | Exception属性表长度 |
| exception_info | exception_table | exception_table_length | 表结构 | Exception属性表 |
| u2 | attribute_count | 1 | 2 | 属性数量 |
| attribute_info | attributes | attribute_count | 表结构 | 属性表 |
有了Code属性表结构,我们就可以清晰的分析29个u1字节所代表含义:
1.max_atack:“00 01”,操作数栈最大深度为1
2.max_locals:“00 01”,局部变量表存储空间为1
3.节码指令的字节码长度:“00 00 00 05”,字节码长度为5
4.节码指令的字节流:“2A B7 00 01 B1”(指令具体含义要参照《字节码指令表》,这里不做介绍)
5.Exception属性表(这里属性表长度为0就不做介绍了)
6.属性表(虚拟机规范的29项属性,有部分属性不仅作用于Class、方法、属性,还作用于Code属性)
Code属性是Class文件中最重要的一个属性,如果把一个Java程序中的信息分为代码(Code,方法体里面的java代码)和元数据(MetaData,包括类、字段、方法定义及其他信息)两部分,那么在整个Class文件里,Code属性用于描述代码,所有的其他数据项目都用于描述元数据。
总结
以实例代码及其class文件,我们详细的剖析了其中的各个组成部分,发现其实class文件就是一个有特定结构的打的表,它是由各种表和无符号数按一定的顺序和规则组成,而这个顺序和规则是Java虚拟机规范定义好的。现在我们知道了class文件的详细结构,我们再回到文章开始提出的问题,我们确实可以通过二进制编辑器按照class文件结构修改class文件,但是能确保程序按你的意思执行吗?还得继续研究,接下来学习虚拟机类加载机制,来看看虚拟机是怎么加载class并执行的。