语法分析(递归下降)以及中间代码生成
语法分析(递归下降)以及中间代码生成
- 语法分析
- 代码详解
- 分割字符
- 读入要分析的程序。
- 主程序。程序的入口(因为是用 jupyter notebook 写的)
- 判断是进入哪一个块。一开始程序的三大块。常量说明,变量说明,语句。
- Const 语句说明部分
- Var说明
- 语句说明
- 中间代码
代码在GitHub上:
https://github.com/lee-geng/B_bianyiyuanli/tree/master
语法分析
一开始我也不是很懂什么是语法分析,但是为了完成实验,还是看了一下过程。
 可以看到这语法分析,其实是一层一层套用的,程序是由常量说明,变量说明,语句这三部分组成,或者是仅有语句组成。[ ] 中括号括起来的表示可选。那么常量说明是什么呢?它在第二小点,也给出了定义就是由 一个Const, 加上常量定义,或者重复加上(、常量定义)。那么其余的也是如此。
可以看到这语法分析,其实是一层一层套用的,程序是由常量说明,变量说明,语句这三部分组成,或者是仅有语句组成。[ ] 中括号括起来的表示可选。那么常量说明是什么呢?它在第二小点,也给出了定义就是由 一个Const, 加上常量定义,或者重复加上(、常量定义)。那么其余的也是如此。
代码详解
-
分割字符
#全局的p,用来表示当前读到第几个字符,letter是一个list
#作用是把程序分割成一个 一个块。字母数字是一块,标点是一块,
#结果在letter 里。
def read_string():
global p,letter;
p1=p;
letter='';
for i in range(p,length):
#跳过前导空格和换行,
#一直读到非空格,和换行为止。
if (f_read[i]==' ')|(f_read[i]=='\n') :
p1=p1+1;
else:
break;
break;
flag_alnum=0;
flag_notalnum=0;
for i in range(p1,length):
#因为前面已经跳过空格和换行了
#这里在遇到空格和换行,就停止
if (f_read[i]==' ') | (f_read[i]=='\n'):
break;
else:
if f_read[i].isalnum():
#是否是字母或数字
if flag_notalnum==1:
#前面出现过不是字母和数字。
#那么就需要退出
break;
letter=letter+f_read[p1];
p1=p1+1;
flag_alnum=1;
else:#是标点,;()之类的
if flag_alnum==1:
#前面出现过字母和数字。
#那么就需要退出,标点和他们是分开的。
break
letter=letter+f_read[p1];
p1=p1+1;
flag_notalnum=1;
p=p1;把当前的p 更新到p1
return letter;
例子: api+3+b; 那么经过这个函数就会分成 api,+,3,+,b这5个部分(api是个变量名 )
a+3b;那么经过这个函数就会分成 a,+,3b 。这三个部分。
-
读入要分析的程序。
#读入 要分析的程序 放在f_read里
with open('examplse2.txt', 'r') as f1:
f_read=f1.read()
length = len(f_read);
如下图程序。
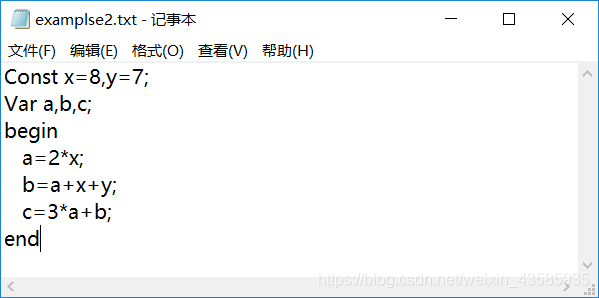
-
主程序。程序的入口(因为是用 jupyter notebook 写的)
#进行分析了。p初始值为0;
def lexer_analysiss():
global p;
while(p-
判断是进入哪一个块。一开始程序的三大块。常量说明,变量说明,语句。
#分析这个是要进入哪里了。
#是Const,还是Var 还是语句
def judge_which():
if 'Const'==letter:
print("Const_description();")
Const_description();
elif 'Var'==letter:
print("Var_description();")
Var_description();
elif letter[0].isalpha:
print("sentense");
sentense();
else:
print("错误Const");
-
Const 语句说明部分
#Const 语句说明
def Const_description():
read_string()
if is_iden()==1:
#判断是不是标识符,自己写的
print(black,"标识符 ",letter)
read_string();
if letter == '=':
print(black,"赋值符号",letter)
read_string();
if is_number()==1:
print(black,"常量",letter);
read_string();
if letter==',':
print(black,"逗号",letter)
Const_description();#循环调用
elif letter==';':
print(black,"分号",letter)
return 1;
else:
print("常量定义错误")
return 0;
else:
print("常量定义错误");
-
Var说明
def Var_description():
read_string()
if is_iden()==1:
print(black,"标识符 ",letter)
read_string();
if letter == ',':
print(black,"逗号",letter)
Var_description();
elif letter ==';':
print(black,"分号",letter);
return 1;
else:
print("Var说明错误")
return 0;
else:
print("Var说明错误");
-
语句说明

可以看到语句有好几个不同的分支语句组成,每个不同的分支语句里 又可以调用语句(这个总的函数)
def sentense():
global layer,letters;
#layer 和black 只是用对输出进行控制,输出几个空格的
#根据不同的letter 进入到不同的语句,并判断。
layer=layer+1;
black=layer*4*' ';
if letter == 'begin':
print(black,"复合语句, begin")
read_string();
while letter!='end':
if letter=='':
print(" 没有 end");
return ;
sentense();
if letters==0:
read_string();
letters=0;
print(black,letter);
elif letter == 'if':
print(black,"条件语句 if");
is_ifconditon();
if letter == 'then':
print(black,"then")
read_string();
sentense();
if letters==0:
read_string();
if letter == 'else':
print(black,letter);
read_string();
sentense();
else:
print("缺少 then");
elif letter =='while':
print(black,"循环语句 while");
is_ifconditon();
if letter=='do':
print(black,letter);
read_string();
sentense();
elif is_iden()==1:
print(black,"标识符",letter);
read_string();
if letter=='=':
print(black,letter);
is_expression();
#read_string();
if letter ==';':
print(black,"分号 ;");
else:
print("缺少分号");
else:
letters=1;
print("缺少等号,赋值语句错误");
print(black,letter)
layer=layer-1;
后面其实都是按照这个图片里,依葫芦画瓢。一步一步写下去。
我的代码只能识别,加减乘除,有括号的或者其他的我还没有完善。代码我就贴到GitHub上。
中间代码
中间代码的生成其实,是在语法分析的基础上,进行语义分析,然后生成中间代码。
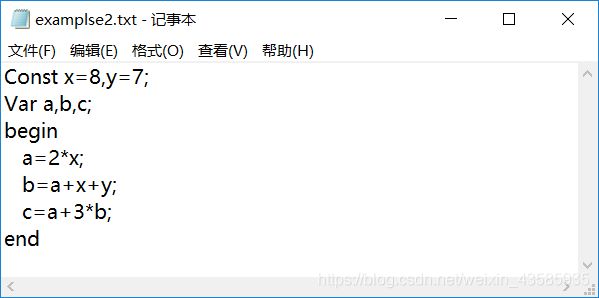
这里的 b = a + x + y ; b=a+x+y; b=a+x+y;我们读了 b = ,那么我们需要判断一下后面的是项吗?如果是项的话,那么它是因子乘以因子的形式,还是仅仅是一个因子的形式。

如果是因子乘以因子的形式,那么就需要先做这个部分的中间代码,这符合我们认识的规律,乘法的优先级高于加法,所以我们需要先做这部分中间代码;如果仅仅是一个因子,那么没关系,就顺序执行。这里的 b = a + x + y ; b=a+x+y; b=a+x+y; 是一个 a 因子,那么我们接下来读,是个 ‘+’,那么判断接下来的项是什么形式,和上面一样。结果还是单因子,所以继续读,读了一个’x’,那么我们现在就有了 ‘a+x’,这里就需要用中间代码来替换了。假设用t0,t0=a+x,那么把t0放到原来的队列里。现在队列里就变成了 b = t 0 + y ; b=t0+y; b=t0+y;,那么继续读,读到 ’+‘,还是按照上面的方法,判断。t1=t0+y;然后b=t1;因为右边只有一个 t1. 所以把 b 和 list1 里,t1 放在 list2 里。如果,下面遇到了 变量,那么我需要判断 这个变量是不是 在list1里,在的话,就需要替换成相对应list2的内容。
假设我们这里是 c = a + 3 ∗ b ; c=a+3*b; c=a+3∗b;读到’+‘,判断下面是一个什么形式的项。结果,这个项是因子乘以因子的形式,我们就需要把这个放在一个队列里,把这个项读完,这里是 3 ∗ b 3*b 3∗b的形式,用 t 2 = 3 ∗ b t2=3*b t2=3∗b,然后这里的b我们因为放在list1里所以需要用t1来表示。就成了 t 2 = 3 ∗ t 1 t2=3*t1 t2=3∗t1。那么 c = a + t 2 c=a+t2 c=a+t2。因为我们之前没有讲第一个式子, a = 2 ∗ x a=2*x a=2∗x。这里的a也可以用 某个 t ( n ) t(n) t(n)来表示。
总体思路就是这样,有 list1,list2,list3,list4.
| 步骤 | 列表 | 内容 |
|---|---|---|
| 1 | list1 | a= |
| 2 | list2 | 2*x(因为这里是个项) |
| 3 | list1 | a=t0 |
| 4 | list3 list4 | list3有a list4有t0 |
| 5 | list1 | b= |
| 6 | list2 | t0(原本是a,但是a在list3里了,所以替换成t0) |
| 7 | list1 | b=t0+ |
| 8 | list2 | x |
| 9 | list1 | b=t0+x |
| 10 | list1 | b=t1+ |
| 11 | list2 | y |
| 12 | list1 | b=t1+y |
| 13 | list1 | b=t2 |
| 14 | list3 list4 | list3 加一个b,list4 加一个t2 |
| 15 | list1 | c=t0+(这里快进了一下) |
| 16 | list2 | 3*t2(原本 3 ∗ b 3*b 3∗b) |
| 17 | list2 | t3 |
| 18 | list1 | c=t0+t3 |
| 19 | list1 | c=t4 |
| 20 | list3 list4 | list3加一个c list4加一个b |
思路就是上面所说的。代码我同样放到GitHub上了。