全国前100所大学数据的爬取,分析及绘表
import csv
import bs4
from urllib import request
from bs4 import BeautifulSoup
'''(1)获取网站页面'''
def getHTMLText(url):
try:
resp = request.urlopen(url)
html_data = resp.read().decode('utf-8')
return html_data
except:
return ""
'''(2)处理页面,提取相关信息'''
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: # 搜索'tbody'后面的子节点
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string,tds[2].string, tds[3].string])
'''(3)解析数据,格式化输出结果'''
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}"
print(tplt.format("排名", "学校名称", "省市", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3], chr(12288)))
def write_to_file2(items):
with open('savecollage.csv', 'a', encoding = 'utf_8_sig',newline='') as f:
fieldnames=["pm","sn","area","score"]
w=csv.DictWriter(f,fieldnames=fieldnames)
w.writerow(items)
pass
pass
if __name__ == '__main__':
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 100) # 输出前20个大学排名
for i in range(100):
#print(uinfo[i])
fieldnames = ["pm","sn","area","score"]
a=dict(zip(fieldnames,uinfo[i]))
print(a)
write_to_file2(a)
import matplotlib.pyplot as plt
import pandas as pd
#指定默认字体
import pylab as pl
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']=['sans-serif']
#解决符号乱码问题
plt.rcParams['axes.unicode_minus']=False
plt.style.use('ggplot')
#设置柱形图大小
fig=plt.figure(figsize=(8,5))
colors1="#6D6D6D"
#先导入原始数据
cloumns=['pm','sn','area','score']
#打开csv文件
df=pd.read_csv('savecollage.csv',encoding = "utf-8",header=None,names=cloumns,index_col='pm')
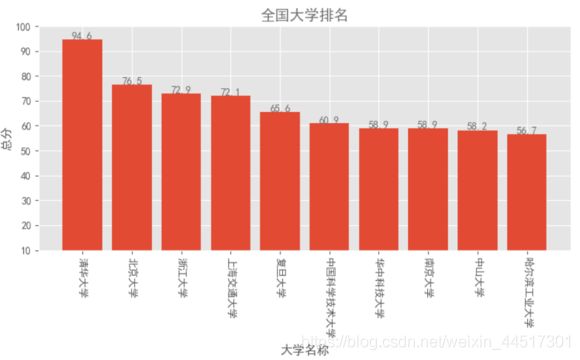
def annlysis1():
df_socre=df.sort_values('score',ascending=False)#asc False降序,True升序,,desc
name1=df_socre.sn[:10]#x轴坐标
score1=df_socre.score[0:10]#y轴坐标
plt.bar(range(10),score1,tick_label=name1)#绘制条形图,//range()能保持x轴一致
plt.ylim(10,100)
plt.title("全国大学排名",color=colors1)
plt.xlabel("大学名称")
plt.ylabel("总分")
for x,y in enumerate(list(score1)):
plt.text(x,y+0.01,'%s' %round(y,1),ha="center",color=colors1)
pl.xticks(rotation=270)
plt.tight_layout()
plt.show()
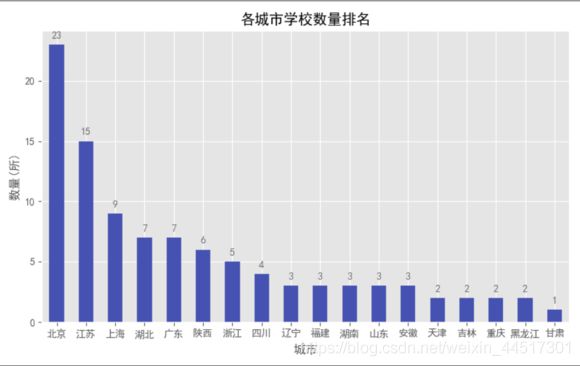
def annlysis2():
area_count = df.groupby(by = 'area').sn.count().sort_values(ascending = False)
# 绘图方法1
print(df)
area_count.plot.bar(color = '#4652B1') # 设置为蓝紫色
pl.xticks(rotation = 0) # x轴名称太长重叠,旋转为纵向
for x, y in enumerate(list(area_count.values)):
plt.text(x, y + 0.5, '%s' % round(y, 1), ha = 'center', color = colors1)
plt.title('各城市学校数量排名')
plt.xlabel('城市')
plt.ylabel('数量(所)')
plt.show()
pass
if __name__ == '__main__':
annlysis1()
annlysis2()