用scrapy爬取妹子图片防盗链图(超详细)
前言:python爬虫爬取图片可以用BeautifulSoup类加Requests库,也可以用scrapy框架,这里主要介绍scrapy方法
tips:有些网站抓取时有可能会返回盗链图
解决方案:防止抓到盗链图
1构建scrapy项目:
在cmd输入scrapy startproject 项目名
输入 cd +目录
此处省略(可以参考我之前的文档scrapy从入门到放弃)``
2查看网页:找我们需要的数据
输入目标网站
浏览器右键查看源代码:

用css选择器
# -*- coding: utf-8 -*-
import scrapy
import os
from zhuamm.items import ZhuammItem
class DSpider(scrapy.Spider):
name = 'd'
allowed_domains = ['https://www.mzitu.com/']
start_urls = ['https://www.mzitu.com/page/1/']
picturelist = []
page = 1
item = ZhuammItem()
def parse(self, response):
print('==' * 70)
# print(response.status)
list1 = response.css('#pins li')
for l in list1:
imgsrc = l.css('img.lazy ::attr("data-original")').extract_first()
title = l.css('img.lazy ::attr("alt")').extract_first()
self.item['title'] = title
self.item['imgsrc'] = imgsrc
###一定要注意,这里是为了防止盗链图的,原理是要网站以为一直是同一个请求
self.item['ref'] = response.url
self.picturelist.append([imgsrc, title])
yield self.item
if self.page < 51:
next_url = 'https://www.mzitu.com/page/' + str(self.page)
url = response.urljoin(next_url)
self.page = self.page + 1
yield scrapy.Request(url=url, callback=self.parse, dont_filter=True)
pass
item类是提供一个模型类用来储存parse后的数据
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ZhuammItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
imgsrc = scrapy.Field()
ref = scrapy.Field()
pass
接下来就是写管道类了
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class ZhuammPipeline(ImagesPipeline):
#修改原来的管道类,继承ImagesPipeline(scrapy专门用于处理图片的类),重写get_media_requests方法(scrapy专门用于处理图片的方法)
def get_media_requests(self, item, info):
# 管道接收response的item并发送图片链接的请求
image_link = item['imgsrc']
print(item['ref'])
yield scrapy.Request(url=image_link, headers={'User-Agent': 'Mozilla/5.0','referer': item['ref']})
最后一定要注意配置settings文件
#打开管道
ITEM_PIPELINES = {
'zhuamm.pipelines.ZhuammPipeline': 300,
}
##注意这是图片保存的地址(我填的是绝对路径)
IMAGES_STORE='/Users/mac/Desktop/picture2'
#scrapy是遵守robots协议的
ROBOTSTXT_OBEY = False
#模拟浏览器
USER_AGENT = 'Mozilla/5.0'
运行完后结果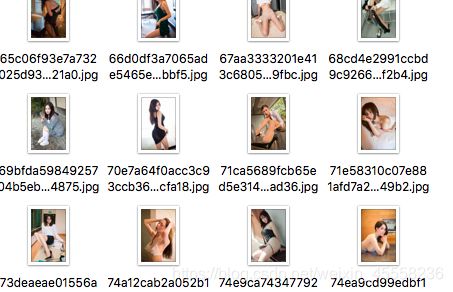
经过不懈的努力终于完成了这个项目,在这里还是要奉劝各位“少撸怡情,大撸伤身”,觉得本文对自己有用的朋友,点一下支持,您的支持,是我创作的不竭动力。