正确率、召回率、F值例子
例子来源:http://bookshadow.com/weblog/2014/06/10/precision-recall-f-measure/
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
理解成:
正确率 = 正确识别的 /识别出的数量
召回率 = 正确识别的 / 原始语料中的数量
F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率 )
上面的介绍网址来源:http://blog.sina.com.cn/s/blog_9b03e9eb0102xa4s.html
第一种代码:
# -*- coding: utf-8 -*-
import re
f1 = open('yuce.txt','r')#,encoding = 'utf-8')
f_r = f1.readlines()
N1 = 0
N2 = 0
N3 = 0
tag1 = 0
tag2 = 0
for line in f_r:
if line != '\n':
each_line = line.strip().split()
if each_line[1] == 'B-SX':
tag1 = 1
N2 = N2 + 1
if each_line[2] == 'B-SX':
tag2 = 1
N3 = N3 + 1
list_1 = []
list_2 = []
for line in f_r:
if line != '\n':
each_line = line.strip().split()
#下面的程序代码是实现原来标记的存储
if each_line[1] == 'B-SX':
list_1.append('1')
elif each_line[1] == 'I-SX':
list_1.append('0')
elif each_line[1] == 'E-SX':
list_1.append('-1')
else: # each_line[1] == 'O':
list_1.append('O')
#下面的程序代码是实现模型跑出来的标记的存储
if each_line[2] == 'B-SX':
list_2.append('1')
elif each_line[2] == 'I-SX':
list_2.append('0')
elif each_line[2] == 'E-SX':#标记结束则用-1表示
list_2.append('-1')
elif each_line[2] == 'O':
list_2.append('O')
else:#下面的是用于读到换行的地方
list_1.append('n')
list_2.append('n')
n = len(list_1)
s = len(list_2)
flag = 0
for i in range(n):
if list_1[i] == 'n':#遇到换行符则进行跳出此处的循环,进行下一次的循环
continue
if flag == 1 and list_1[i] == '1':
N1 = N1+1
flag = 0
#print 111111
if flag == 1 and i == n-1:
N1 = N1+1
flag = 0
#print 11111
continue
if flag == 0:
if list_1[i] == '1':
if list_2[i] == '1':
flag = 1
else:
flag = 0
else:
flag = 0
else:
if list_1[i] == '0':
if list_2[i] == '0':
flag = 1
continue
else:
flag = 0
elif list_1[i] == '1':
if list_2[i] == '1':
N1 = N1 + 1
flag = 0
else:
flag = 0
elif list_1[i] == 'O':
if list_2[i] == 'O':
N1 = N1 + 1
flag = 0
else:
flag = 0
elif list_1[i] == '-1' :
if list_2[i] == '-1':
N1 = N1 + 1
flag = 0
else:
flag = 0
if flag == 1 and i == n-1:
N1 = N1+1
#print 333
print ('系统识别正确的MNP数量为 :')
print(N1)
print ('语料中实际的MNP数量为 :')
print(N2)
print ('系统识别的MNP数量为 :')
print (N3)
P = float(N1 )/float( N3)
R = float(N1) /float( N2)
p = 1
F = float((1 * 1 + 1) * P * R) / float((R + 1 * 1 * P))
print ('准确率为:')
print(P)
print ('召回率为:')
print(R)
print ('F值为:')
print(F)
f1.close()
第二种代码:
# Python version of the evaluation script from CoNLL'00-
# Originates from: https://github.com/spyysalo/conlleval.py
# Intentional differences:
# - accept any space as delimiter by default
# - optional file argument (default STDIN)
# - option to set boundary (-b argument)
# - LaTeX output (-l argument) not supported
# - raw tags (-r argument) not supported
'''
第一列是词语 第二列是答案,最后一列是预测
'''
import sys
import re
import codecs
from collections import defaultdict, namedtuple
ANY_SPACE = ''
class FormatError(Exception):
pass
Metrics = namedtuple('Metrics', 'tp fp fn prec rec fscore')
class EvalCounts(object):
def __init__(self):
self.correct_chunk = 0 # number of correctly identified chunks
self.correct_tags = 0 # number of correct chunk tags
self.found_correct = 0 # number of chunks in corpus
self.found_guessed = 0 # number of identified chunks
self.token_counter = 0 # token counter (ignores sentence breaks)
# counts by type
self.t_correct_chunk = defaultdict(int)
self.t_found_correct = defaultdict(int)
self.t_found_guessed = defaultdict(int)
def parse_args(argv):
import argparse
parser = argparse.ArgumentParser(
description='evaluate tagging results using CoNLL criteria',
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
arg = parser.add_argument
arg('-b', '--boundary', metavar='STR', default='-X-',
help='sentence boundary')
arg('-d', '--delimiter', metavar='CHAR', default=ANY_SPACE,
help='character delimiting items in input')
arg('-o', '--otag', metavar='CHAR', default='O',
help='alternative outside tag')
arg('file', nargs='?', default=None)
return parser.parse_args(argv)
def parse_tag(t):
m = re.match(r'^([^-]*)-(.*)$', t)
return m.groups() if m else (t, '')
def evaluate(iterable, options=None):
if options is None:
options = parse_args([]) # use defaults
counts = EvalCounts()
num_features = None # number of features per line
in_correct = False # currently processed chunks is correct until now
last_correct = 'O' # previous chunk tag in corpus
last_correct_type = '' # type of previously identified chunk tag
last_guessed = 'O' # previously identified chunk tag
last_guessed_type = '' # type of previous chunk tag in corpus
for line in iterable:
line = line.rstrip('\r\n')
if options.delimiter == ANY_SPACE:
features = line.split()
else:
features = line.split(options.delimiter)
if num_features is None:
num_features = len(features)
elif num_features != len(features) and len(features) != 0:
raise FormatError('unexpected number of features: %d (%d)' %
(len(features), num_features))
if len(features) == 0 or features[0] == options.boundary:
features = [options.boundary, 'O', 'O']
if len(features) < 3:
raise FormatError('unexpected number of features in line %s' % line)
guessed, guessed_type = parse_tag(features.pop())
correct, correct_type = parse_tag(features.pop())
first_item = features.pop(0)
if first_item == options.boundary:
guessed = 'O'
end_correct = end_of_chunk(last_correct, correct,
last_correct_type, correct_type)
end_guessed = end_of_chunk(last_guessed, guessed,
last_guessed_type, guessed_type)
start_correct = start_of_chunk(last_correct, correct,
last_correct_type, correct_type)
start_guessed = start_of_chunk(last_guessed, guessed,
last_guessed_type, guessed_type)
if in_correct:
if (end_correct and end_guessed and
last_guessed_type == last_correct_type):
in_correct = False
counts.correct_chunk += 1
counts.t_correct_chunk[last_correct_type] += 1
elif (end_correct != end_guessed or guessed_type != correct_type):
in_correct = False
if start_correct and start_guessed and guessed_type == correct_type:
in_correct = True
if start_correct:
counts.found_correct += 1
counts.t_found_correct[correct_type] += 1
if start_guessed:
counts.found_guessed += 1
counts.t_found_guessed[guessed_type] += 1
if first_item != options.boundary:
if correct == guessed and guessed_type == correct_type:
counts.correct_tags += 1
counts.token_counter += 1
last_guessed = guessed
last_correct = correct
last_guessed_type = guessed_type
last_correct_type = correct_type
if in_correct:
counts.correct_chunk += 1
counts.t_correct_chunk[last_correct_type] += 1
return counts
def uniq(iterable):
seen = set()
return [i for i in iterable if not (i in seen or seen.add(i))]
def calculate_metrics(correct, guessed, total):
tp, fp, fn = correct, guessed-correct, total-correct
p = 0 if tp + fp == 0 else 1.*tp / (tp + fp)
r = 0 if tp + fn == 0 else 1.*tp / (tp + fn)
f = 0 if p + r == 0 else 2 * p * r / (p + r)
return Metrics(tp, fp, fn, p, r, f)
def metrics(counts):
c = counts
overall = calculate_metrics(
c.correct_chunk, c.found_guessed, c.found_correct
)
by_type = {}
for t in uniq(list(c.t_found_correct) + list(c.t_found_guessed)):
by_type[t] = calculate_metrics(
c.t_correct_chunk[t], c.t_found_guessed[t], c.t_found_correct[t]
)
return overall, by_type
def report(counts, out=None):
if out is None:
out = sys.stdout
overall, by_type = metrics(counts)
c = counts
out.write('processed %d tokens with %d phrases; ' %
(c.token_counter, c.found_correct))
out.write('found: %d phrases; correct: %d.\n' %
(c.found_guessed, c.correct_chunk))
if c.token_counter > 0:
out.write('accuracy: %6.2f%%; ' %
(100.*c.correct_tags/c.token_counter))
out.write('precision: %6.2f%%; ' % (100.*overall.prec))
out.write('recall: %6.2f%%; ' % (100.*overall.rec))
out.write('FB1: %6.2f\n' % (100.*overall.fscore))
for i, m in sorted(by_type.items()):
out.write('%17s: ' % i)
out.write('precision: %6.2f%%; ' % (100.*m.prec))
out.write('recall: %6.2f%%; ' % (100.*m.rec))
out.write('FB1: %6.2f %d\n' % (100.*m.fscore, c.t_found_guessed[i]))
def report_notprint(counts, out=None):
if out is None:
out = sys.stdout
overall, by_type = metrics(counts)
c = counts
final_report = []
line = []
line.append('processed %d tokens with %d phrases; ' %
(c.token_counter, c.found_correct))
line.append('found: %d phrases; correct: %d.\n' %
(c.found_guessed, c.correct_chunk))
final_report.append("".join(line))
if c.token_counter > 0:
line = []
line.append('accuracy: %6.2f%%; ' %
(100.*c.correct_tags/c.token_counter))
line.append('precision: %6.2f%%; ' % (100.*overall.prec))
line.append('recall: %6.2f%%; ' % (100.*overall.rec))
line.append('FB1: %6.2f\n' % (100.*overall.fscore))
final_report.append("".join(line))
for i, m in sorted(by_type.items()):
line = []
line.append('%17s: ' % i)
line.append('precision: %6.2f%%; ' % (100.*m.prec))
line.append('recall: %6.2f%%; ' % (100.*m.rec))
line.append('FB1: %6.2f %d\n' % (100.*m.fscore, c.t_found_guessed[i]))
final_report.append("".join(line))
return final_report
def end_of_chunk(prev_tag, tag, prev_type, type_):
# check if a chunk ended between the previous and current word
# arguments: previous and current chunk tags, previous and current types
chunk_end = False
if prev_tag == 'E': chunk_end = True
if prev_tag == 'S': chunk_end = True
if prev_tag == 'B' and tag == 'B': chunk_end = True
if prev_tag == 'B' and tag == 'S': chunk_end = True
if prev_tag == 'B' and tag == 'O': chunk_end = True
if prev_tag == 'I' and tag == 'B': chunk_end = True
if prev_tag == 'I' and tag == 'S': chunk_end = True
if prev_tag == 'I' and tag == 'O': chunk_end = True
if prev_tag != 'O' and prev_tag != '.' and prev_type != type_:
chunk_end = True
# these chunks are assumed to have length 1
if prev_tag == ']': chunk_end = True
if prev_tag == '[': chunk_end = True
return chunk_end
def start_of_chunk(prev_tag, tag, prev_type, type_):
# check if a chunk started between the previous and current word
# arguments: previous and current chunk tags, previous and current types
chunk_start = False
if tag == 'B': chunk_start = True
if tag == 'S': chunk_start = True
if prev_tag == 'E' and tag == 'E': chunk_start = True
if prev_tag == 'E' and tag == 'I': chunk_start = True
if prev_tag == 'S' and tag == 'E': chunk_start = True
if prev_tag == 'S' and tag == 'I': chunk_start = True
if prev_tag == 'O' and tag == 'E': chunk_start = True
if prev_tag == 'O' and tag == 'I': chunk_start = True
if tag != 'O' and tag != '.' and prev_type != type_:
chunk_start = True
# these chunks are assumed to have length 1
if tag == '[': chunk_start = True
if tag == ']': chunk_start = True
return chunk_start
def return_report(input_file):
with codecs.open(input_file, "r", "utf8") as f:
counts = evaluate(f)
return report_notprint(counts)
def main(argv):
args = parse_args(argv[1:])
if args.file is None:
counts = evaluate(sys.stdin, args)
else:
with open(args.file) as f:
counts = evaluate(f, args)
report(counts)
if __name__ == '__main__':
sys.exit(main(sys.argv)) 运行的命令:python3 conlleval.py 预测的文件名字
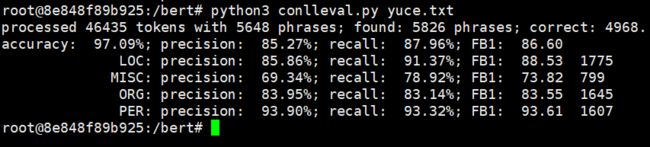
上面的第一种代码是自己根据特定的任务进行写的代码
第二种代码是从网上下载下来的代码