(TensorFlow)变分自编码器实现
变分自编码器(VAEs)是学习低维数据表示的强大模型。TensorFlow的分发包提供了一种简单的方法来实现不同类型的VAE。
在这篇文章中,我将引导你完成在MNIST上训练简单VAE的步骤,主要侧重于实战。
1.定义网络:
VAE由三部分组成:编码器q(z | x ),先验p(z ),解码器p(x | z )。
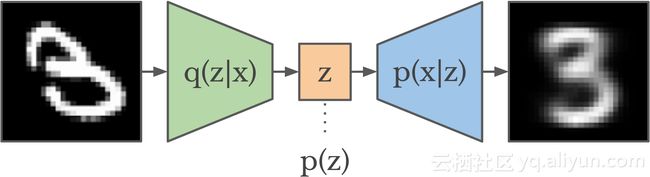
编码器将图像映射到针对该图像的代码的分布上。这种分布也被称为后验(posterior),因为它反映了我们关于代码应该用于给定图像之后的准确度。
import tensorflow as tf
tfd = tf.contrib.distributions
def make_encoder(data, code_size):
x = tf.layers.flatten(data)
x = tf.layers.dense(x, 200, tf.nn.relu)
x = tf.layers.dense(x, 200, tf.nn.relu)
loc = tf.layers.dense(x, code_size)
scale = tf.layers.dense(x, code_size, tf.nn.softplus)
return tfd.MultivariateNormalDiag(loc, scale)先验(prior)是固定的,上面我们还定义了我们期望的代码块分布。这对VAE可以使用的代码块提供了一个非常弹性的选择空间。它通常只是一个零均值和单位方差的正态分布。
def make_prior(code_size):
loc = tf.zeros(code_size)
scale = tf.ones(code_size)
return tfd.MultivariateNormalDiag(loc, scale)解码器需要编写一个代码块并将其映射回合理的图像分布。它允许我们重建图像,或为我们选择的任何代码块生成新图像。
import numpy as np
def make_decoder(code, data_shape):
x = code
x = tf.layers.dense(x, 200, tf.nn.relu)
x = tf.layers.dense(x, 200, tf.nn.relu)
logit = tf.layers.dense(x, np.prod(data_shape))
logit = tf.reshape(logit, [-1] + data_shape)
return tfd.Independent(tfd.Bernoulli(logit), 2)在这里,我们对数据使用伯努利分布,将像素建模为二进制值。根据数据的类型和领域,您可能需要以不同的方式对其进行建模,例如再次以正态分布的形式进行建模。
该tfd.Independent(..., 2)告诉TensorFlow,内部两个尺寸——(宽度和高度)。在我们的例子中,属于同一个数据点,即使他们有独立的参数。这使我们能够评估分布下图像的概率,而不仅仅是单个像素。
2.重新使用模型
我们希望使用解码器网络两次,计算下一节中描述的重构损失,以及一些随机采样的可视化代码块。
在TensorFlow中,如果您调用两次网络功能,它将创建两个独立的网络。TensorFlow模板允许您打包一个函数,以便多次调用它将重用相同的网络参数。
make_encoder = tf.make_template('encoder', make_encoder)
make_decoder = tf.make_template('decoder', make_decoder)
之前没有可训练的参数,所以我们不需要将其包装到模板中。
3.定义损失
我们希望找到为我们的数据集分配最高可能性的网络参数。然而,数据点的可能性取决于最好的代码块,这点在训练中是我们不知道。
代替的,我们将使用(ELBO)对数据可能性进行近似训练。

这里的重要细节是,ELBO仅使用给定我们当前对其代码块的估计的数据点的可能性,我们可以对其进行抽样。
data = tf.placeholder(tf.float32, [None, 28, 28])
prior = make_prior(code_size=2)
posterior = make_encoder(data, code_size=2)
code = posterior.sample()
likelihood = make_decoder(code, [28, 28]).log_prob(data)
divergence = tfd.kl_divergence(posterior, prior)
elbo = tf.reduce_mean(likelihood - divergence)一个直观的解释是,最大化ELBO可以最大限度地提供给定当前代码的数据的可能性,同时鼓励代码接近我们先前的代码应该是什么样子的信念。
4.运行训练
我们使用梯度下降来最大化ELBO。这是一个非常可行的方案,因为采样操作是在内部使用重新参数化技巧来实现的,所以TensorFlow可以通过它们反向传播。
optimize = tf.train.AdamOptimizer(0.001).minimize(-elbo)而且,我们从之前的样本中抽取一些随机代码来可视化VAE学到的相应图像。这就是上面我们使用tf.make_template()的原因 ,让我们再次调用解码器网络。
samples = make_decoder(prior.sample(10), [28, 28]).mean()最后,我们加载数据并创建一个会话来运行训练:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data/')
with tf.train.MonitoredSession() as sess:
for epoch in range(20):
test_elbo, test_codes, test_samples = sess.run(
[elbo, code, samples], {data: mnist.test.images})
print('Epoch', epoch, 'elbo', test_elbo)
plot_codes(test_codes)
plot_sample(test_samples)
for _ in range(600):
sess.run(optimize, {data: mnist.train.next_batch(100)[0]})如果你想玩代码,看看完整的代码示例,它也包含在这篇文章中其他省略的绘图,以及前几个训练阶段的解码样本。

正如你所看到的,潜在的空间很快就会被分成几组不同的数字。如果您为代码块和较大的网络使用更多维度,您还将看到生成的图像变得越来越清晰。
5.结论
我们已经学会在TensorFlow中建立一个VAE,并在MNIST数字上训练它。下一步,您可以自己运行代码并对其进行扩展,例如使用CNN编码器和解码器。
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《building-variational-auto-encoders-in-tensorflow》,
作者:Danijar Hafner:旨在建立基于人脑概念的智能机器的研究人员
译者:虎说八道,审阅:
文章为简译,更为详细的内容,请查看原文