Scrapy安装与应用教程
1 scapy介绍
scrapy是一个基于twisted(python)的开源的爬虫框架,注意它是一个框架,不同于requests和urllib,这两个是库,很多功能都需要自己去实现
scrapy优点
耦合度低,可扩展性强
可以快速灵活定制需求,例如实现log,参数配置,监控,数据处理
针对爬虫中遇到的各类问题(反爬虫策略,数据解析,数据持久化等),只需完成指定模块的开发就可以实现功能
异步实现,并发量大,适用于大规模爬取数据
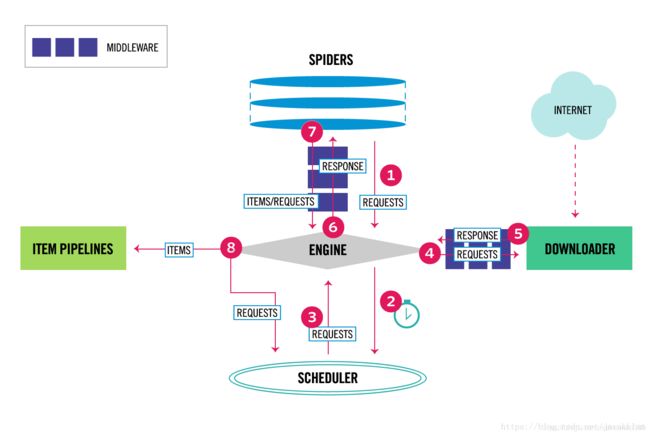
上图是scrapy的框架,包括以下几个部分
engine:负责处理整个系统的数据流,出发事务
spider:负责发起requests,解析response的数据内容为item,并将解析后的item返回给引擎
item pipelines:负责处理items,包括过滤,分析,存储等,常见的应用就是将数据存入数据库
downloader:负责根据request内容下载数据并返回response
middleware:处理request和response的中间件,常见应用包括设置数据请求头,代理和代理IP等
scheduler:负责接受引擎发送来的请求,并将其加入队列中。
2 scrapy安装
pip install scrapy
3 scrapy项目启动
#创建一个scrapy项目:scrapy startpoject 项目名称
scrapy startpoject baidu
#进入项目目录,不然下一步生成的spider将不再spider目录
cd baidu
#创建一个spider:scrapy genspider 爬虫名称 目标网址
scrapy genspider baidutest baidu.com
注:创建的spider名称不能是数字开头,如果是数字开头将会自动在自定义名称前加a
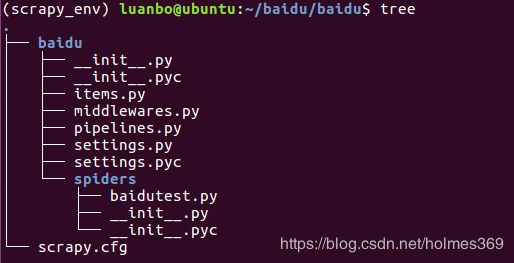
执行完成后系统将出现如下目录结构
4 scrapy实现
spider实现request请求和解析reponse
如果希望循环爬取多个网页的数据可以在def start_requests方法定义需要爬取的网址url
def start_requests(self):
url = "https://movie.douban.com/top250?p={0}"
for i in range(1, 5):
yield scrapy.Request(url, dont_filter=True,method='GET',callback=self.parse)
注:scrapy.Request可以设置内容包括(callback=None, method=‘GET’, headers=None, body=None,cookies=None, meta=None, encoding=‘utf-8’, priority=0,dont_filter=False, errback=None, flags=None, cb_kwargs=None)
常见的参数
callback回调方法,一般是spider中的parse
method类型,默认是GET
headers,设置请求头
body,设置body
cookies,设置cookies
dont_filter,默认为Flase,就是如果相同的url将会被过滤掉
实现parse方法
def parse(self, response):
movie_list = response.xpath("//ol[@class='grid_view']/li/div[@class='item']")
for movie in movie_list:
item = TutorialItem()
item['title'] = movie.xpath(".//div[@class='hd']/a/span[1]/text()").extract_first()
item['url'] = movie.xpath(".//div[@class='hd']/a/@href").extract_first()
item['description'] = movie.xpath(".//span[@class='inq']/text()").extract_first()
yield item
注:scrapy自带xpath功能,可以直接使用
对应的item实现
class MovieItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
url = scrapy.Field()
description = scrapy.Field()
对应itempipelines实现将数据持久化到mysql数据库中
import pymysql
from douban.settings import MYSQL_HOST, MYSQL_PORT, MYSQL_DB, MYSQL_USER,MYSQL_PASSWORD,MYSQL_CHARSET
class DouBanPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host = MYSQL_HOST,port=MYSQL_PORT,user = MYSQL_USER,password = MYSQL_PASSWORD,
database = MYSQL_DB,charset = MYSQL_CHARSET)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
#使用cursor.mogrify好处是内部执行参数化生成的SQL语句,对特殊字符进行了加\转义,避免注入语句生成。
insert_sql = self.cursor.mogrify(
"insert into tbl_movie (name,url,description )values(%s,%s,%s)" %
(item['name'],item['url'],item['description']))
self.cursor.execute(insert_sql)
self.conn.commit()
return item
settings里的配置
#LOG_LEVEL="INFO"
#LOG_FILE= 'log.txt'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
#设置下载延迟3秒
DOWNLOAD_DELAY = 3
#配置对应的pipelines
ITEM_PIPELINES = {
'douban.pipelines.DouBanPipeline': 300,
}
#默认USER_AGENT
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
#默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
####mysql配置#######
MYSQL_HOST='localhost'
MYSQL_PORT=3306
MYSQL_DB='douban'
MYSQL_USER='root'
MYSQL_PASSWORD='root'
MYSQL_CHARSET='utf8'
最后启动爬虫命令
启动有两种方式,第一种也是最常见的是直接使用scrapy自带命令行
srcapy crawl douban
第二种启动方式是scrapy启动的两种方式
新建一个.py文件,写入启动命令,例如run.py:
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'douban'])
注:crawl后面跟的是spider的名字,不是项目名
如果需要设置代理和ip代理池可以在middleware中实现,本文暂时不涉及
参考教程
https://scrapy-chs.readthedocs.io/zh_CN/1.0/index.html