Spring Cloud -Eureka 源码
服务端源码
图1
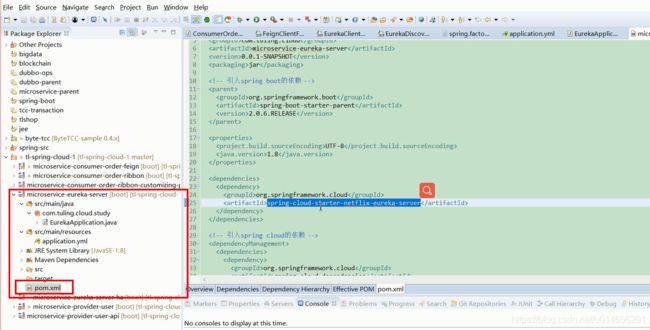
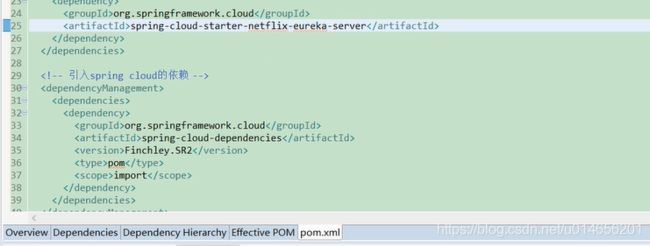
图2
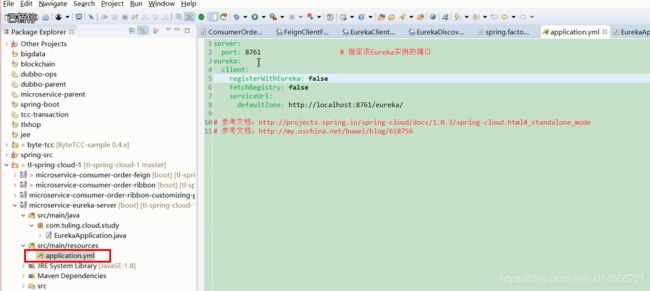
图3
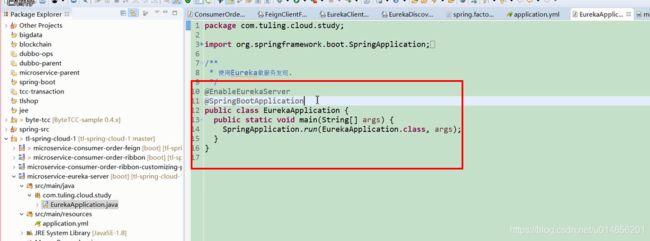 图4
图4
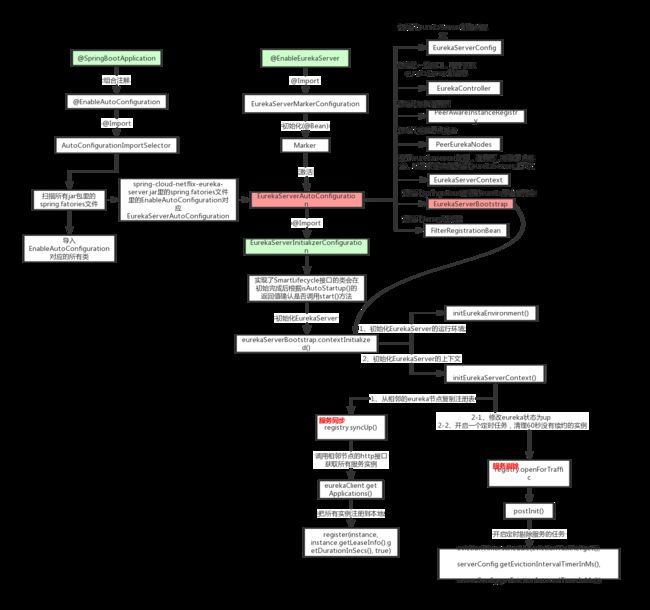
主类中最重要的是这个注解@SpringBootApplication
图5

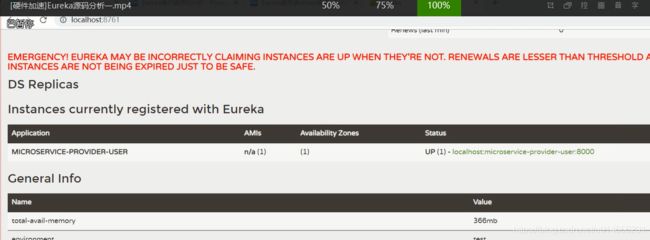
正常启动后的页面
图6
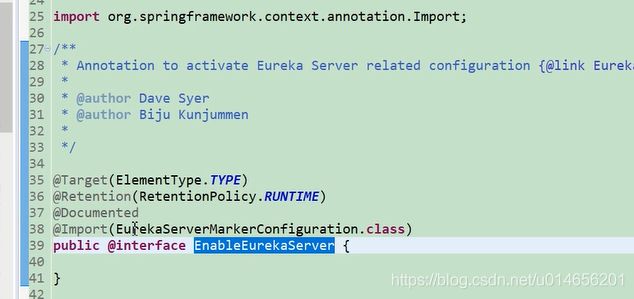
图7

这个类的作用就是激活EurekaServerAuoConfiguration 这个类。在spring 启动的时候启动。
图8
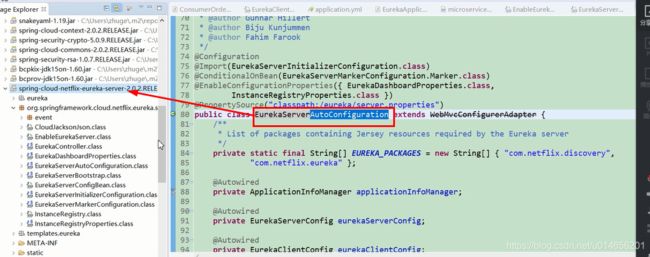
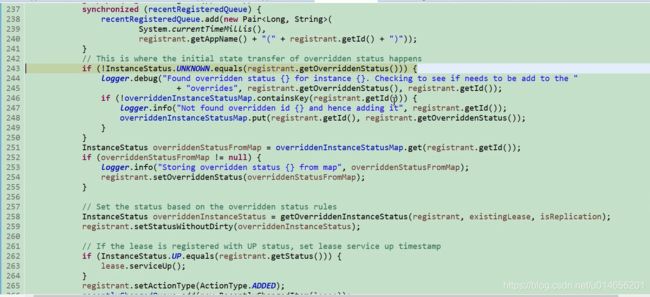
spring 在启动的时候会把这个类加载到容器中。但是并一定启动。 图9 。是否启动要看注解配置 @ConditionalOnBean ,是否在容器中有EurekaServerMarkerConfiguration这个类 ,才会真正的被spring容器中启动。EurekaServerAuoConfiguration,;还有其他的一些配置文件 @EnableConfigurationProperties 图12 ; @Import 的 EurekaServerInitializerConfiguration; 初始化一些东西 图13。
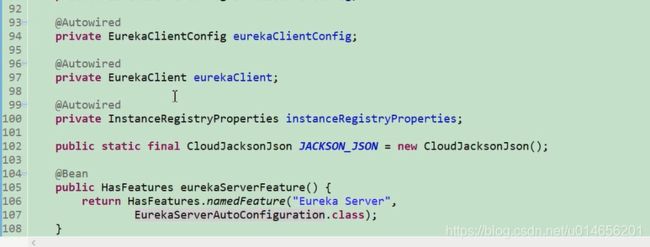
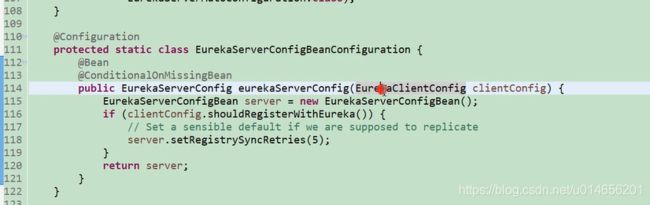
eureka的配置图10 ,初始化一个EurekaServer的一些配置。
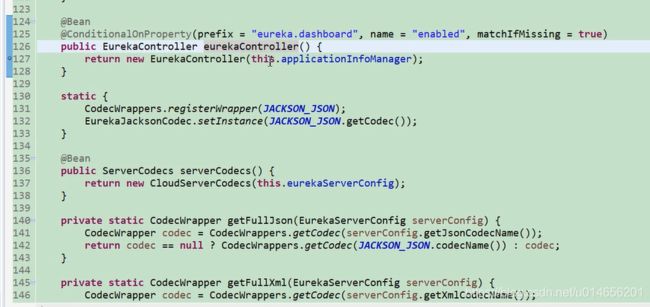
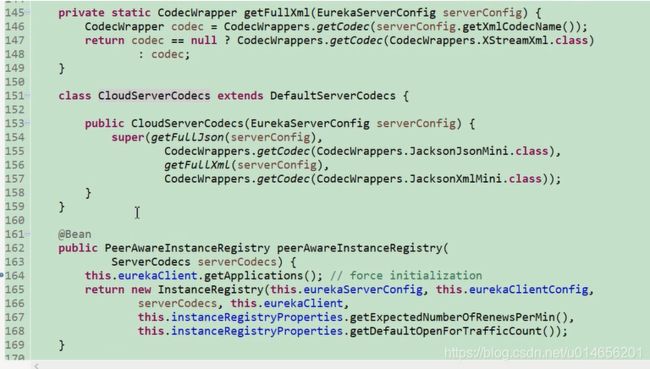
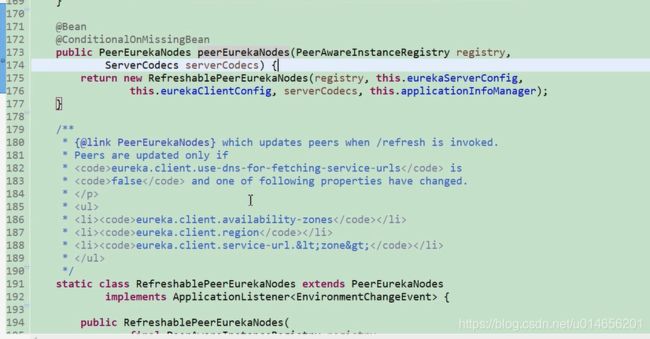

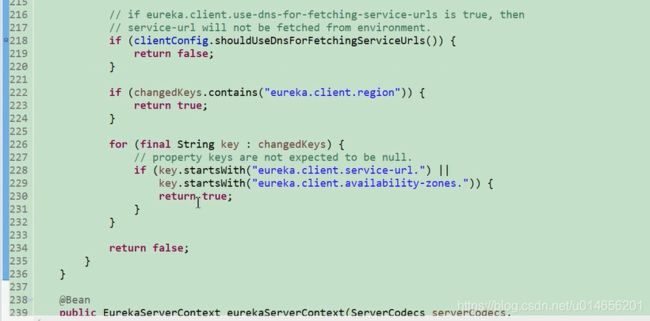
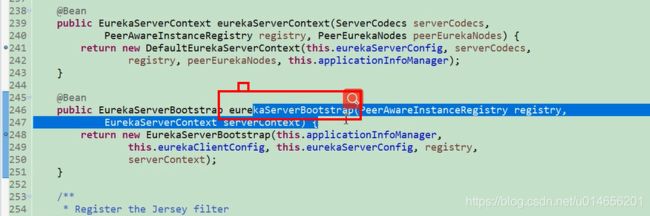
eurekaServer的启动。图
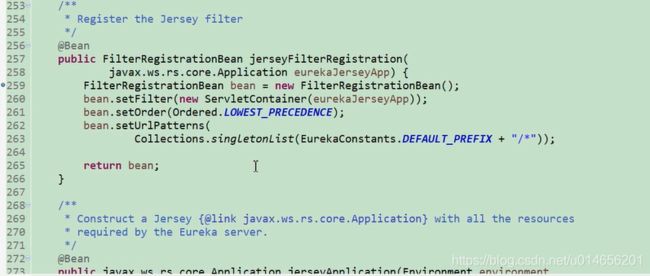
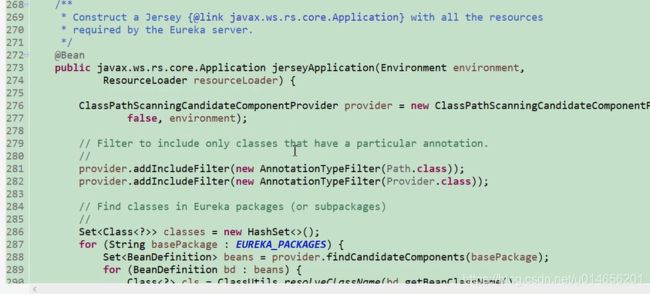
图9
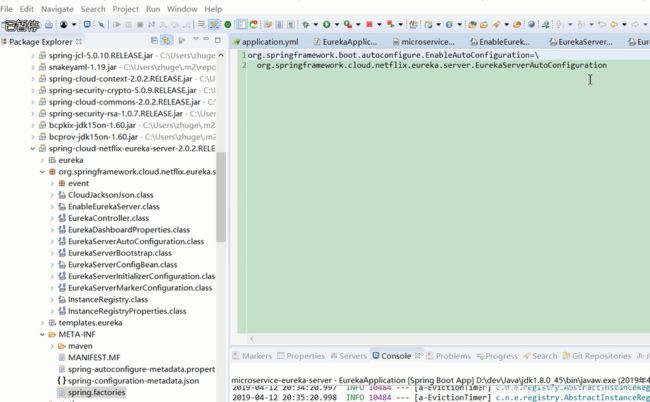
图10
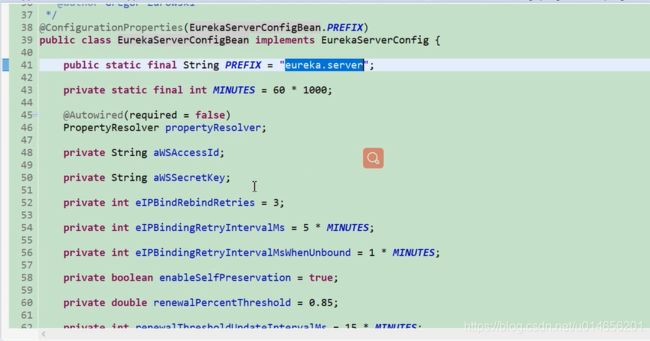


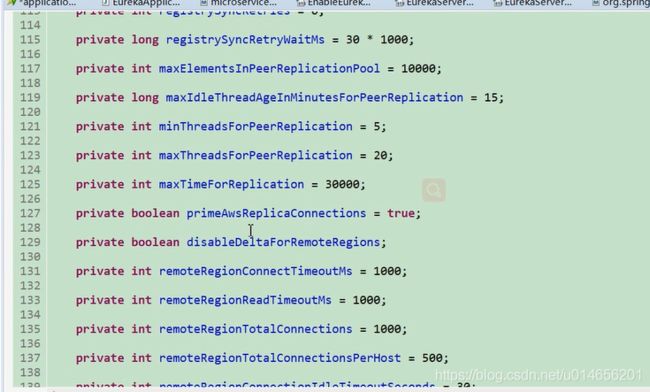
图11
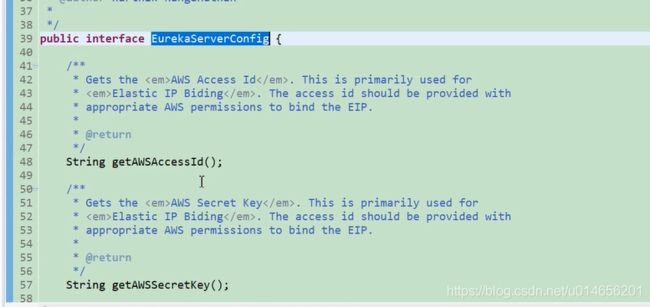
这个bean里面回放入我们很多的eureka里很多关键性的配置。
图12
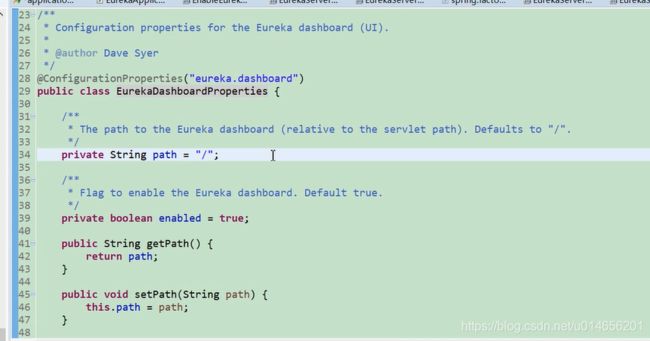
一些其他的配置文件。
图13
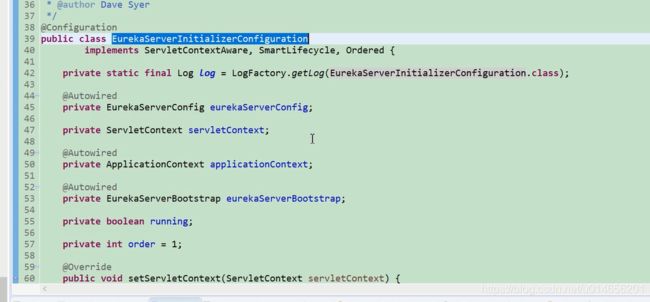
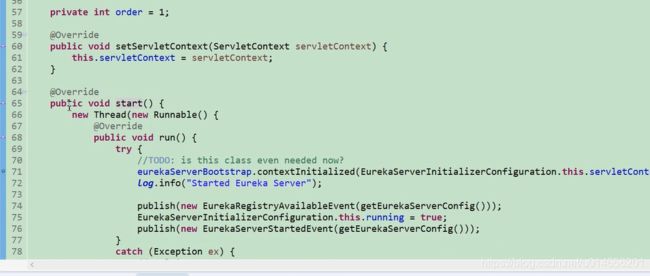

实现start()方法。

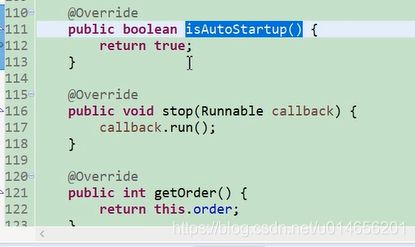
如果isAutoStartup ()方法返回true 的时候,spring回调上面的start方法。
图14
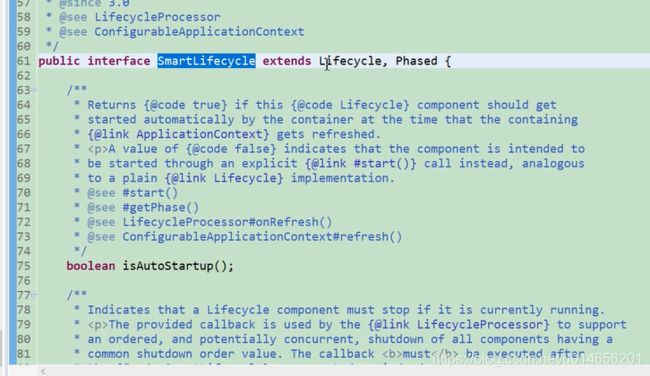

启动初始化。
图15
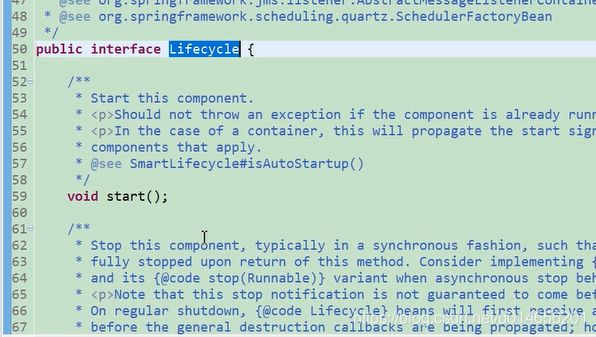
生命周期的接口
图16
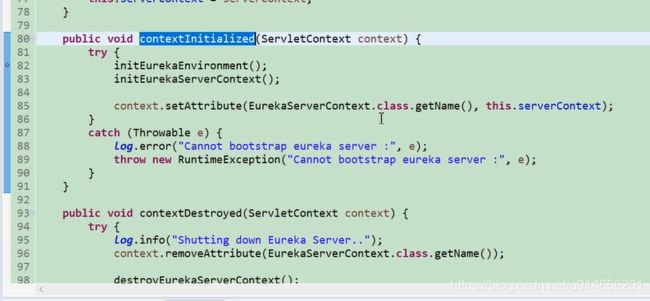
初始化运行时环境,初始化eureka 的上下文。
图17
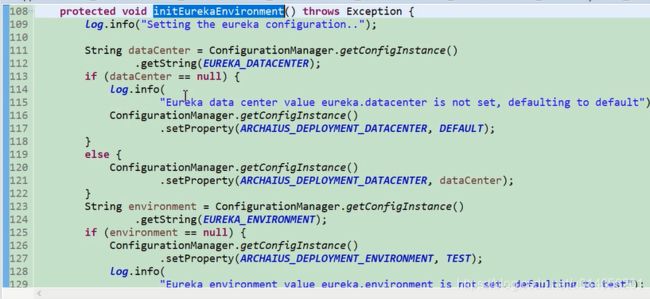
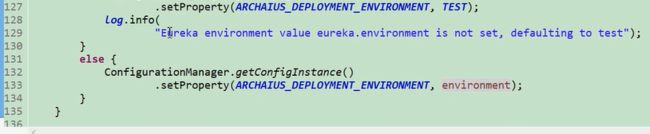
图18
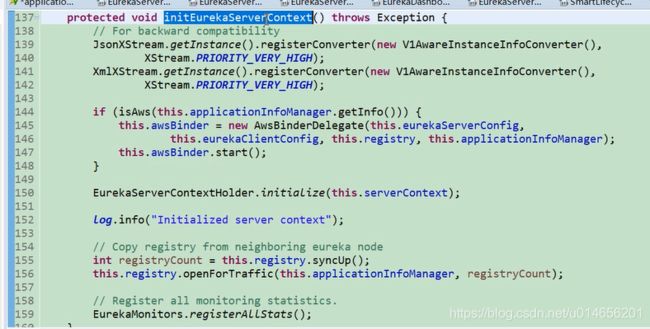
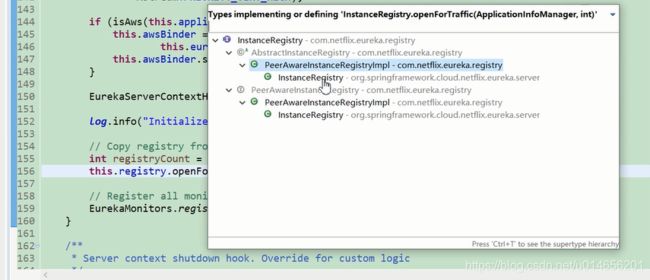
156行当我们要调用 registry. opetForTraffic() 这个方法是发现这个接口有多个实现,到底用那个类实现?看下registry的定义,图20
图19
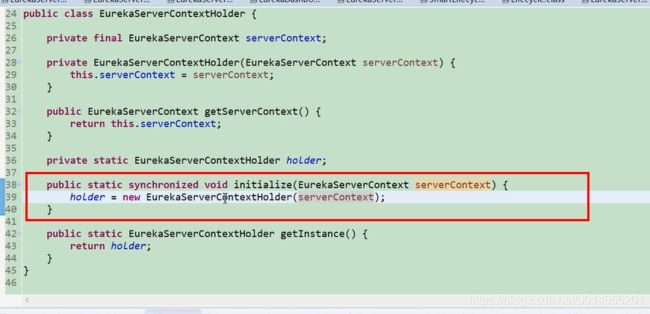
图20
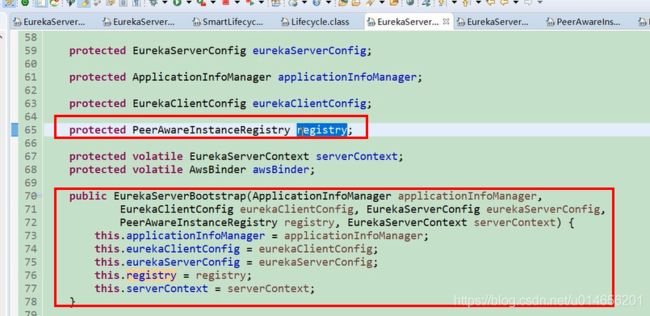
发现他是通过EurekaServerBootstrap方法示例化的,那在什么时候调用的呢,
图21
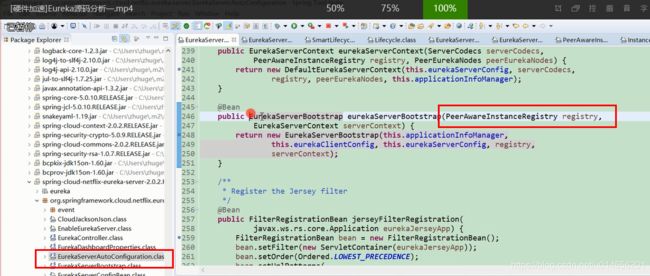 通过这个方法我们就能够确定registry是PeerAwareIntanceREgistry,那PeerAwareIntanceRegistry 怎么初始化的的,图22。
通过这个方法我们就能够确定registry是PeerAwareIntanceREgistry,那PeerAwareIntanceRegistry 怎么初始化的的,图22。
图22

初始化peerAwareInstanceRegistry.
图23
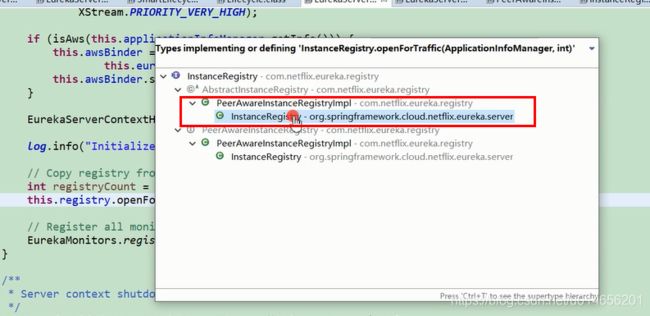
图24
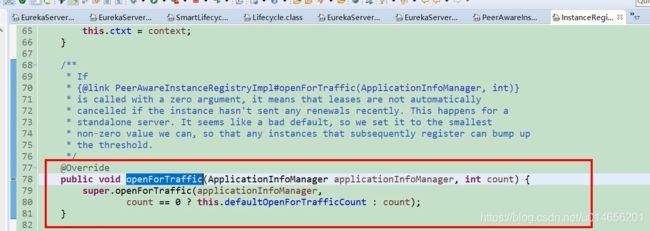
图25
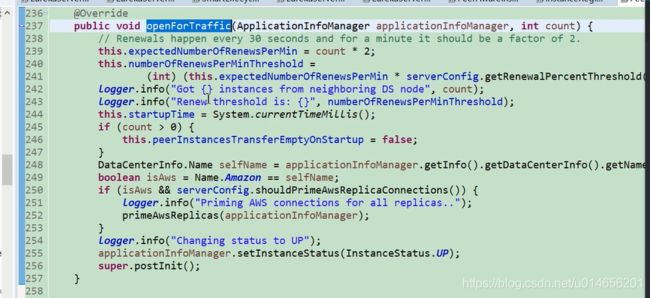


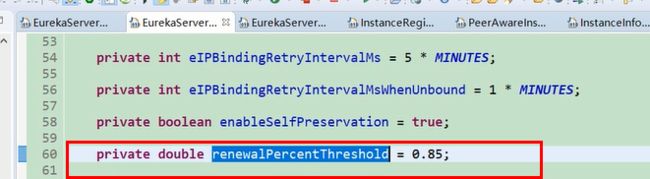
图26
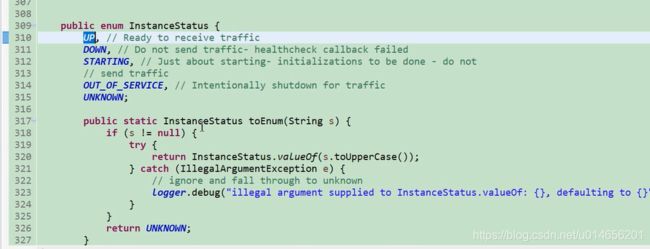
图27
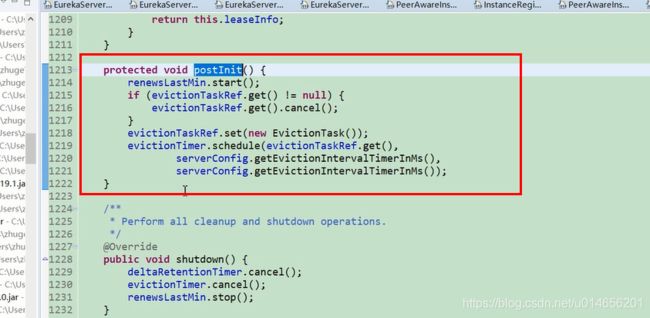
延迟多久,定时剔除没有心跳反应的机器。图 29
图28
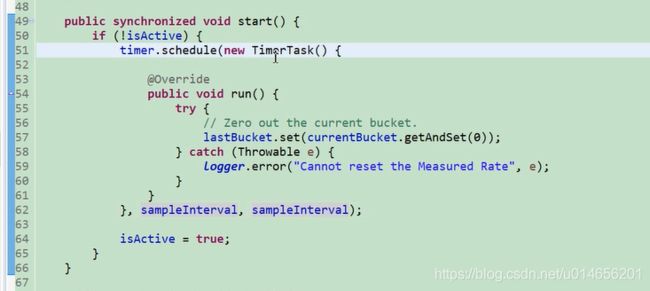
图29

图30
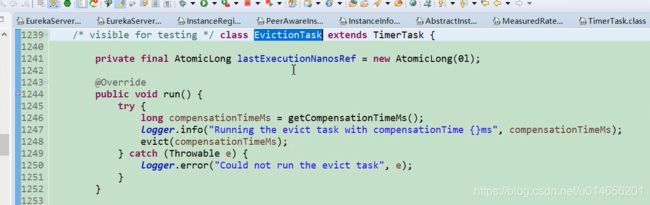
图31
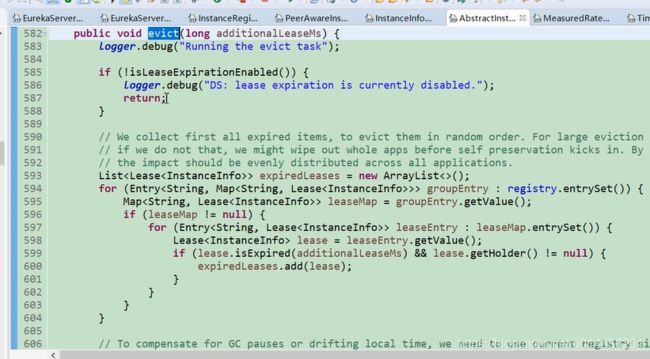
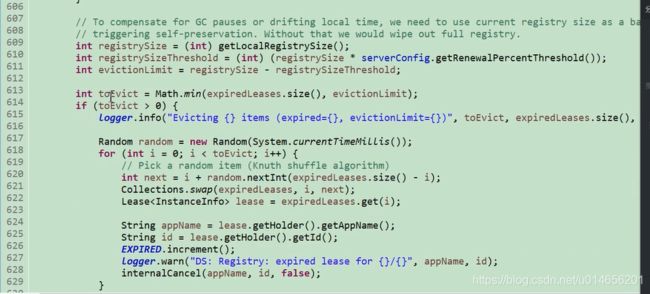
图32


客户端源码
图33
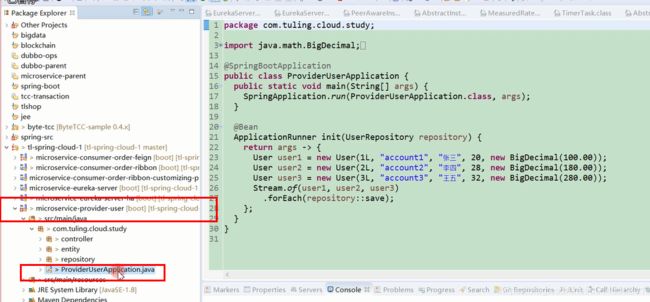
运行客户端程序。
图34
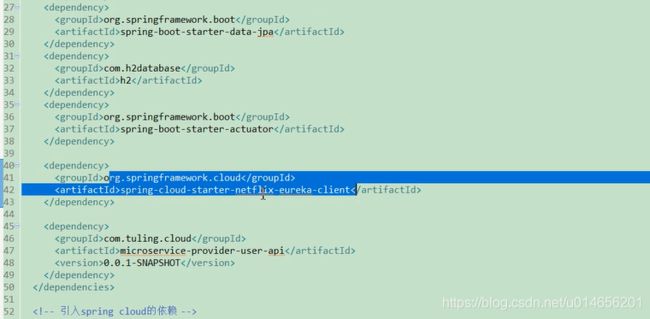
图35
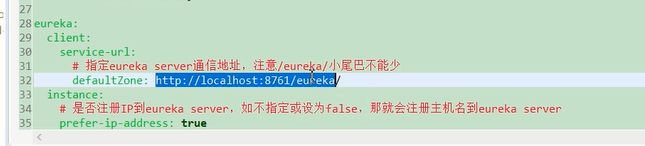
图36
我们的客户端启动,好像没有什么注解标识和服务端的关系,仅仅是因为我们在图35的配置文件配置了吗
图37

那我们先从依赖包看起,
图38
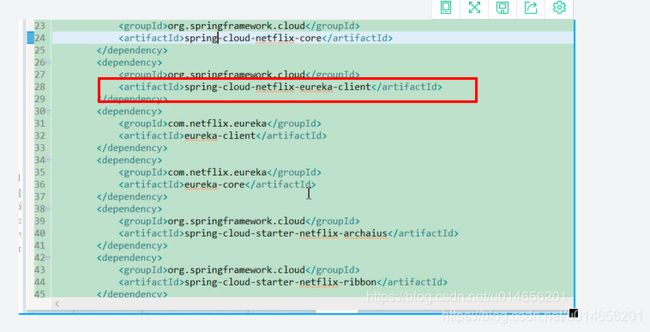
核心代码应该是28行。
图39
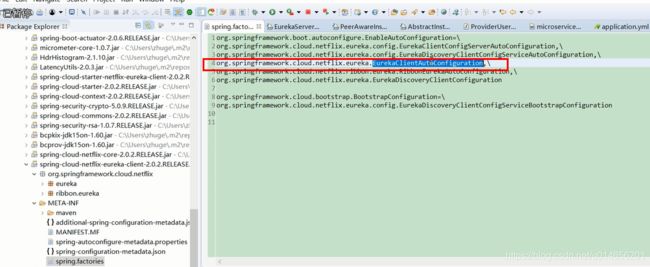
在这个包里看下,
图40
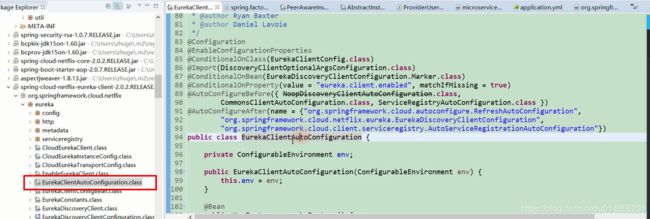
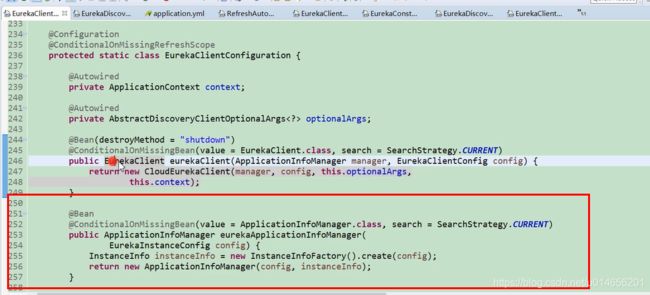
@ConditionalOnBean这个类是不是和服务端的很像啊, @AutoConfigureAfter这个注解的意思是加载 这个注解 之后的类以后,才加载EurekaClientAutoConfiguration这个类。 @AutoConfigureAfter注解中包含三个类,其中EurekaDiscoveryClientConfiguration和我们的client有关系。图42
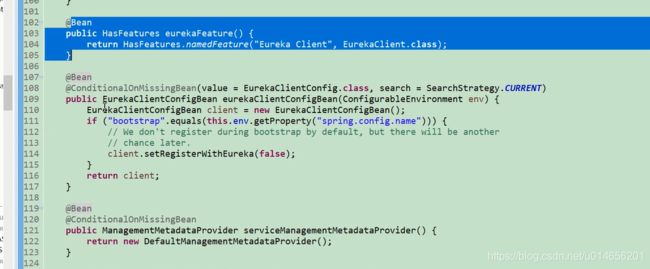
初始化EurekaClientConfigBean 109行,
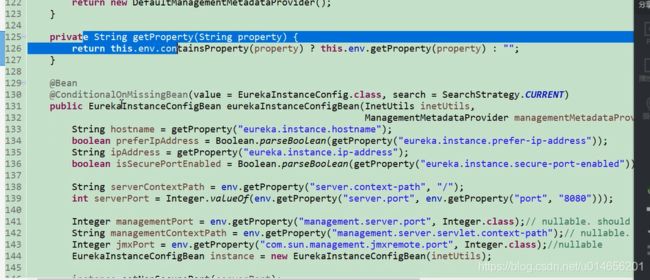
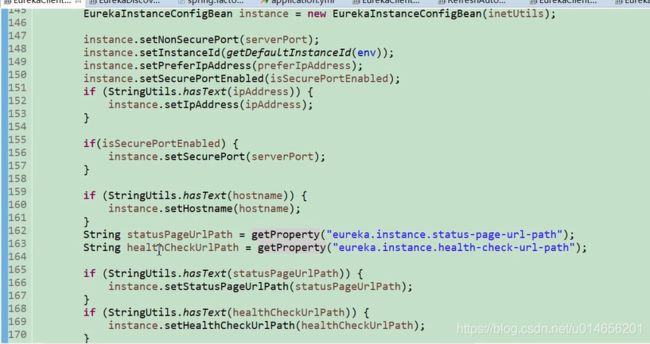
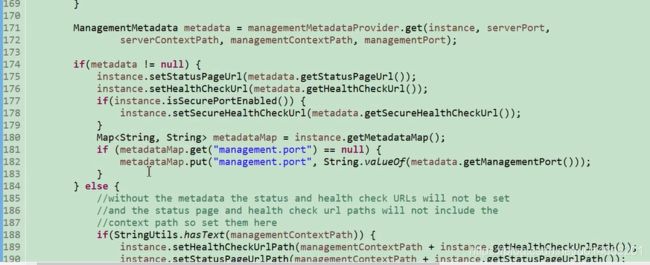
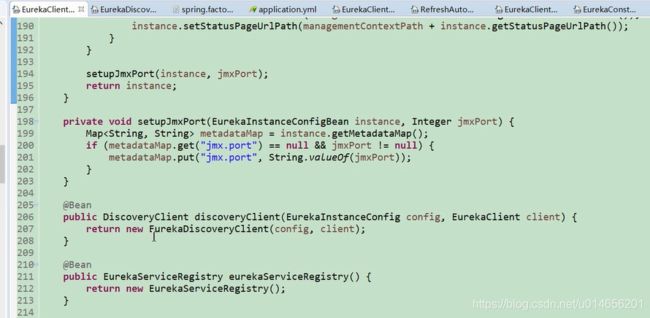

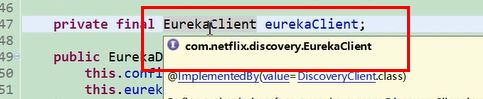
206行 DiscoveryClient是 spring 对eureka Clicent类的一种封装。 真正的eureka Client是 EurekaClient类,那么问题来了什么时候初始化的EurekaClient类呢,
详细代码图46
图41

图42
ConditionalOnProperty 这个注解,默认是true,只有这个注解,EurenkaDisccverClientConfiguration才会启作用。
图 43
图44
图45

图46
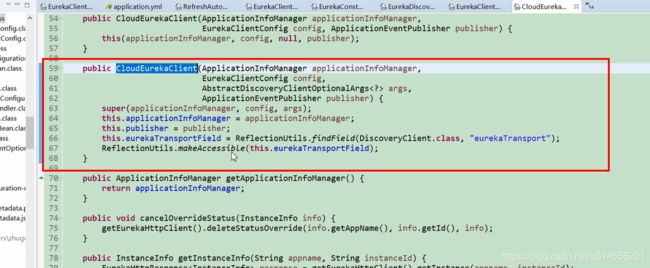 当调用63行,super时,图48
当调用63行,super时,图48
图47
父类是DiscoveryClient
图48

当我们269行,this时图49
图49
定时任务,心跳, 刷新。
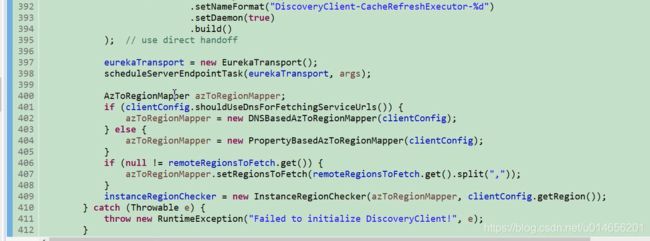
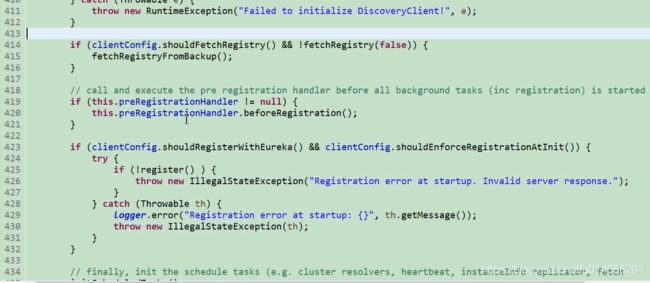
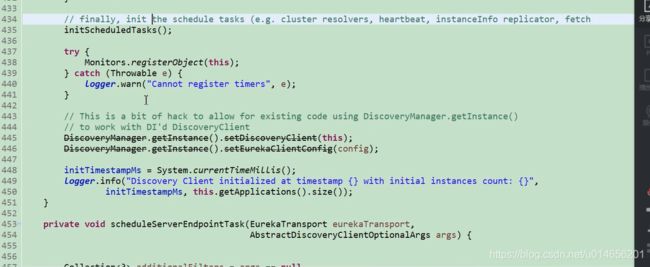 435行,我们看到注释 初始化定时任务,其中定时任务有集群解析, 心跳检测,示例的复制,拉取注册表
435行,我们看到注释 初始化定时任务,其中定时任务有集群解析, 心跳检测,示例的复制,拉取注册表
图50

定时拉取注册表的。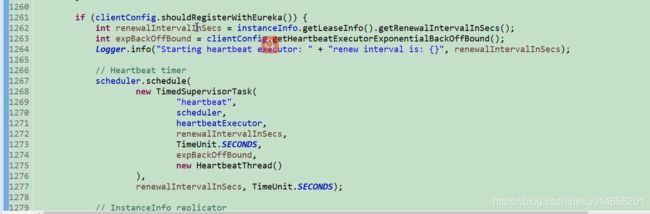
服务续约图59-0
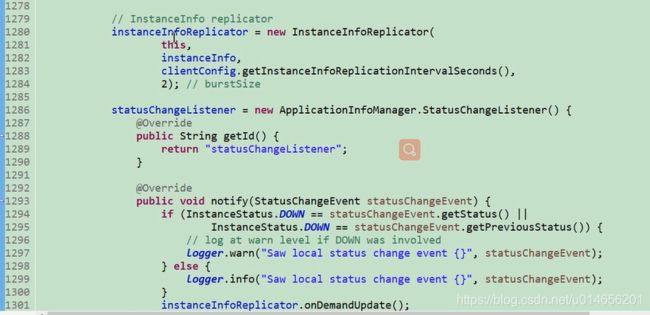
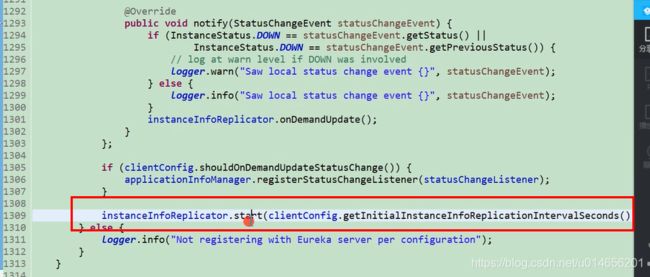
初始化注册任务。

相当于配置文件的这两个属性,如果不配置默认为true; 如果是服务端单节点的,需要配置两个为false的。对于客户端来说都会执行的,

这里写错了,应该是Eureka Server 也会维护一个只读的服务清单缓存。

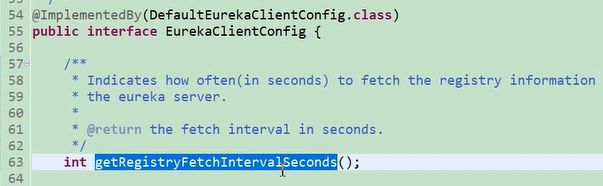


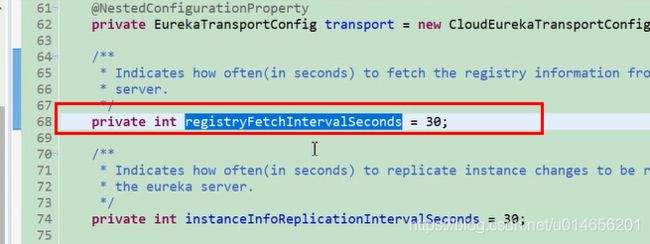
1248 行 定时任务,默认每30秒,从服务端获取服务列表。 scheduler.schedule() 这个方法是一次性调用,为什么说每隔30秒获取呢,
图51
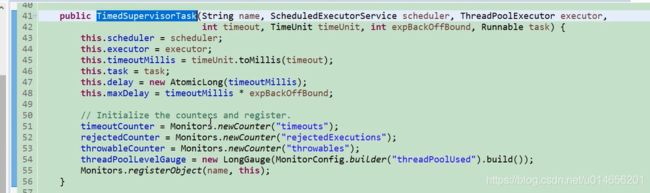
图52
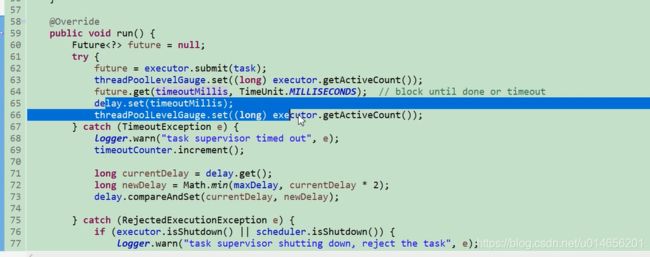

这里有三个闪光点,第一是并发编程的使用,第二是时间翻倍, future.get() 获取超时抛异常后(说明这个任务30秒不可能完成,所以给他翻倍),会获取他的值 ,把原来的值扩大两倍,然后取扩大后的值和最大值最小的那个值,作为延迟后的时间。 第三个是时间还原;如果是这个任务是偶尔一次性 30秒不能完成在把时间翻倍,就不太合适了。这里的做法是 future.get() 获取超时,如果第三次,第四次获取不超时就会把原来的值设置回去。65行。 如果用TimedSupervisorTask,不能实现这样灵活的时间翻倍。

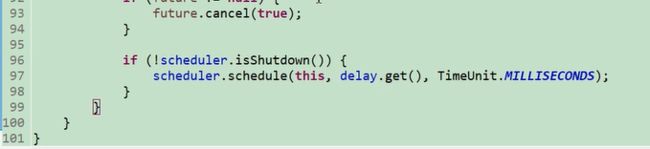
当我们看到96行才知道,在schenduler.schedule()的方法里面有重新调用了一次. schenduler.schedule(),所以他有每隔30秒。
图53
分析一下task;

![]()
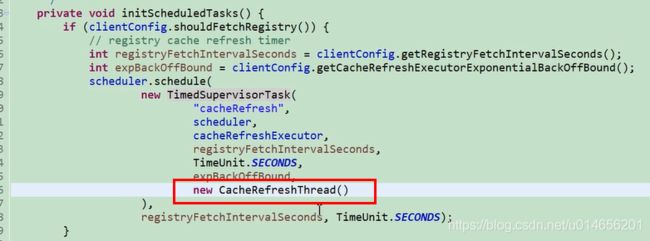
图54
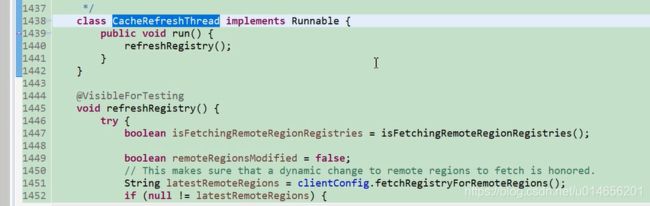
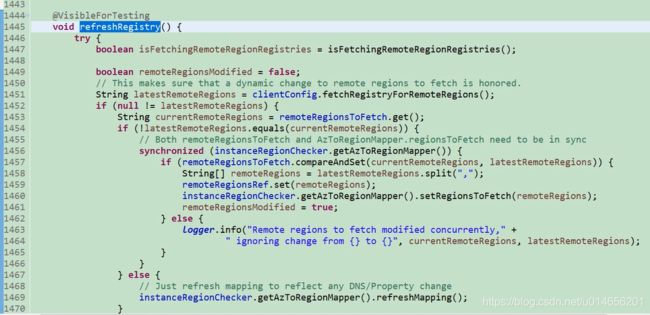
1451行到1470行 是亚马逊的整合部分,不用看,
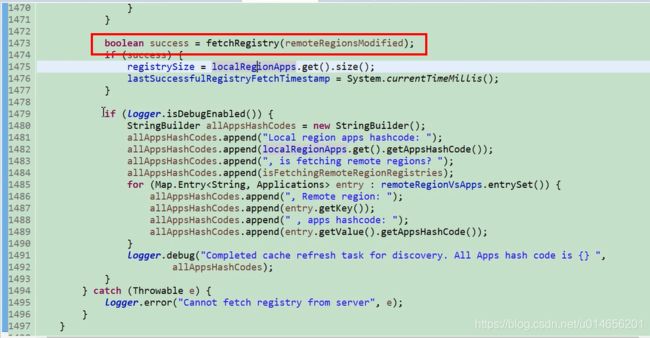
1473行拉去注册表。
图55
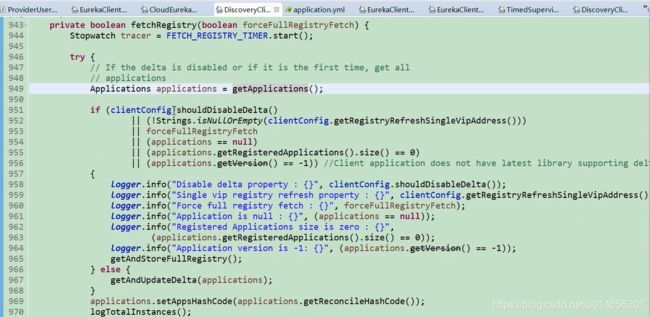 947,948行代码注释,如果增量被禁止,或者是第一次的时候拉去全部的注册表。当第一次的时候,applications肯定为空。判断是否增量拉取是否禁止。这个是可以配置。如果为true 就是全量拉取,如果为false就是增量获取 965行获取和存储注册表。图57
947,948行代码注释,如果增量被禁止,或者是第一次的时候拉去全部的注册表。当第一次的时候,applications肯定为空。判断是否增量拉取是否禁止。这个是可以配置。如果为true 就是全量拉取,如果为false就是增量获取 965行获取和存储注册表。图57
图56
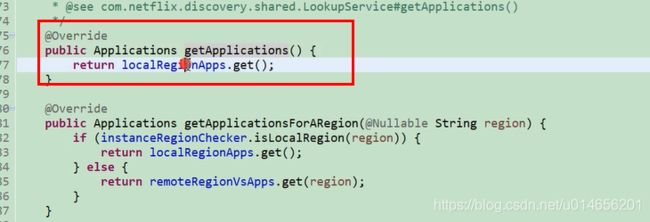

这个是本地缓存
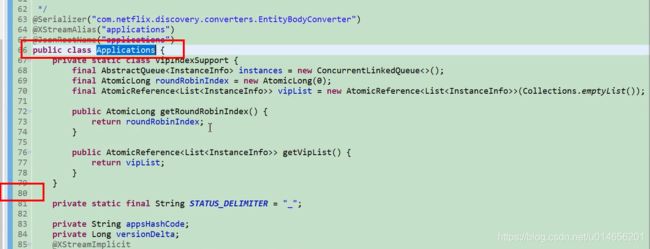

图57
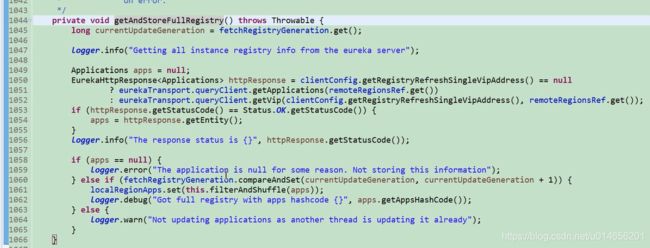

我们拉取全量的的注册表,并保存本地。1051行,获取全量注册表,利用Eureka client调用Euredka Server 方法返回。
1061行保存到本地缓存中。
图58

图59
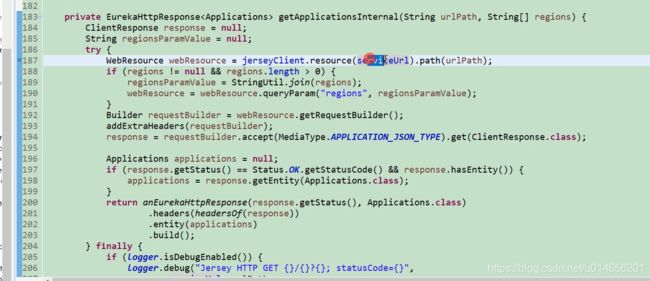

187行最终拼接的地址。
图59-0
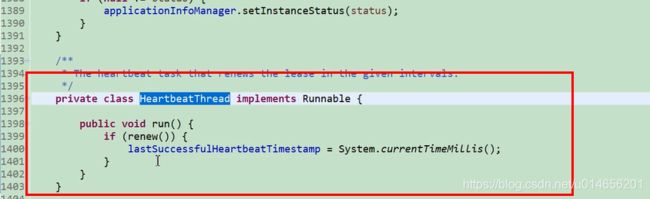
服务续约的任务
图59-1
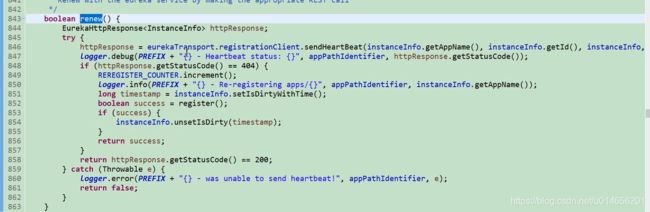
图59-2
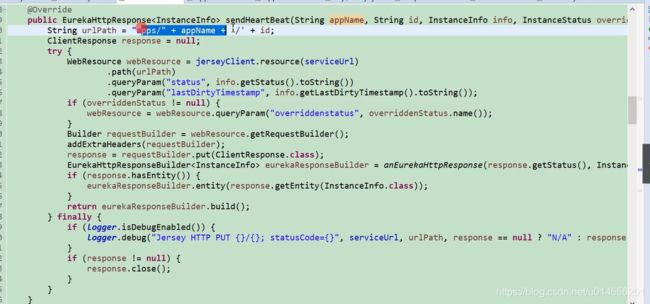
图59-3

服务注册
图59-4
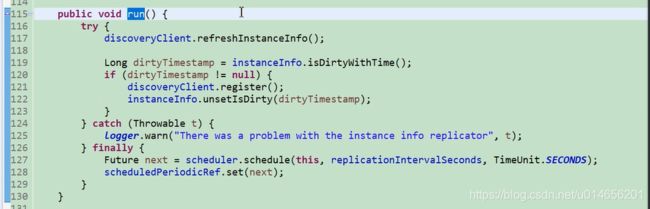
图59-5


图59-6
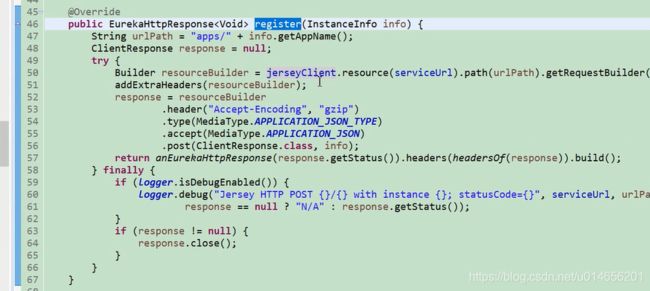
图59-7

根据这个接口去服务端找对应的接口。
图60

eureka server 对外提供的接口。
图61
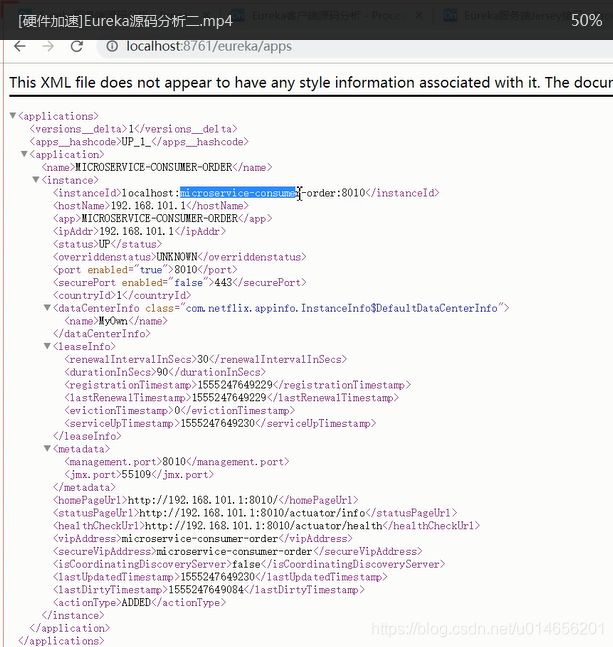
但是我们发现一个小问题,即便我们的服务器启动了,也要等一段时间才可以出数据。
增量的获取
图61-0
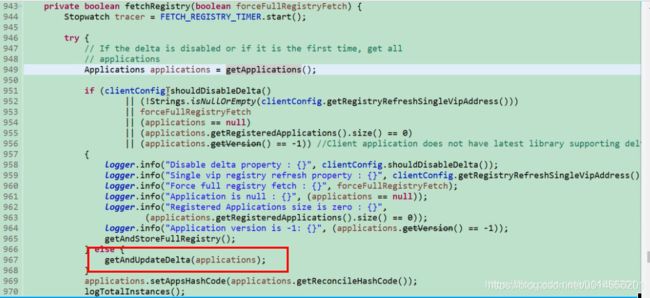
图61-2
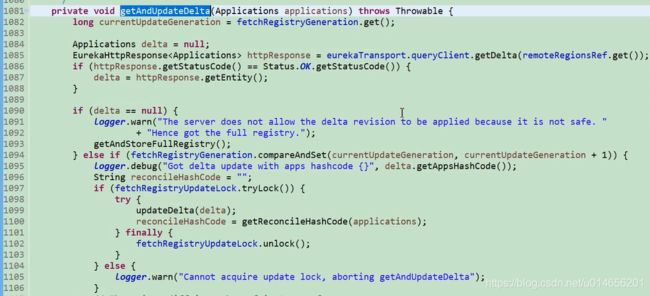
首先也是利用eureka client调用 增量接口。如果增量的数据为空,为了安全起见他有调用了全量获取。如果增量不为null 需要把原来的全量和增量合并所以需要加锁。如果不加锁 其他线程操作,数据就乱套了。现在有一种场景,客户端每30秒钟去服务端拉取 注册表,第一次是全量,第二次拉取的时候网络有问题导致没有拉取到,第三 ,四,五,六,次也没有拉取到,这个时候服务端也有一个缓存这个缓存3分钟会失效,正好3分钟后服务端缓存失效,那么客户端来拉取增量的时候为空,这种情况下 ,客户端的注册表和服务端的注册表是不一致的。1100行这个方法就是解决这个问题的。 图61-4 通过从增量中拉取的hashcode和 本地的hashcode做比较,不一致的话从新拉取全量。

不一致的话会全量调用。图61-5
图61-3
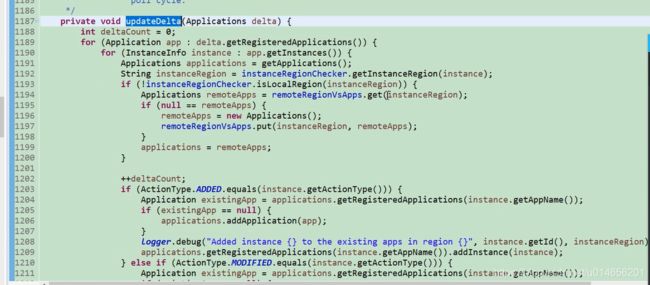
合并:遍历增量 ,通过增量的名字取本地的全量中查找如果没有直接 放入,

图61-4

getReconcileHashCode()
图61-5
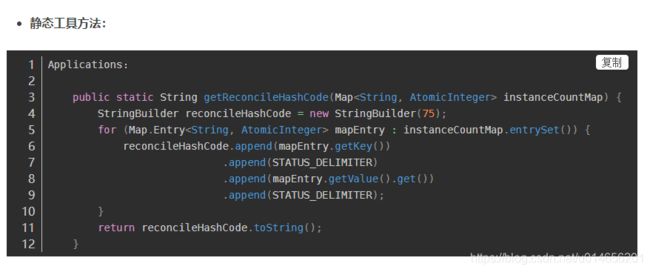
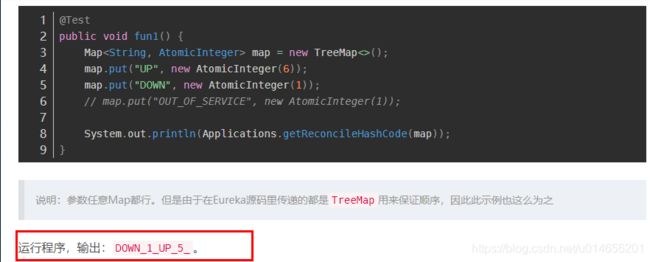
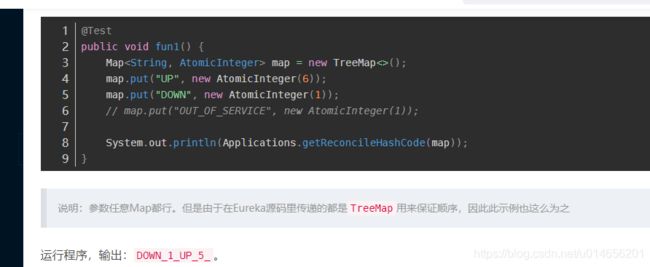
图61-5
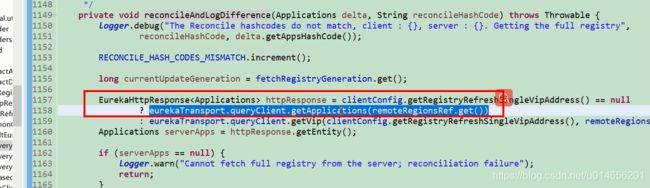
以下是服务端的源码
图62
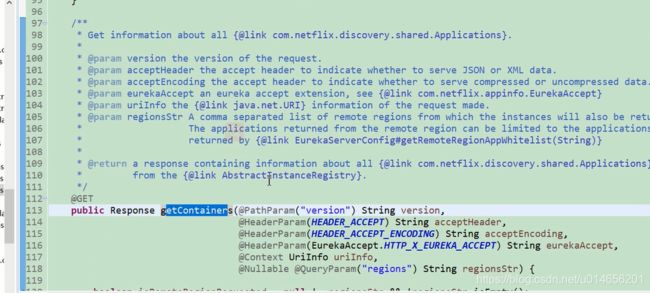

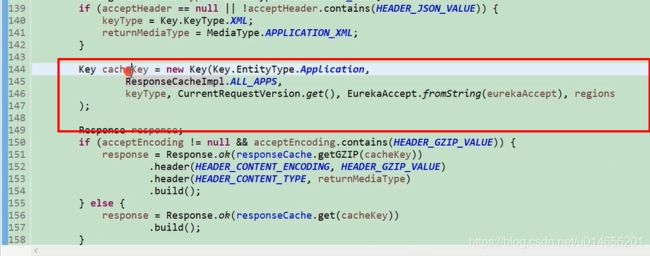
156行 关键代码 图64
图63
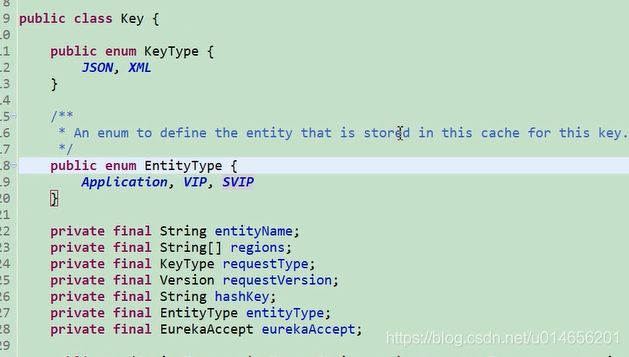

图64
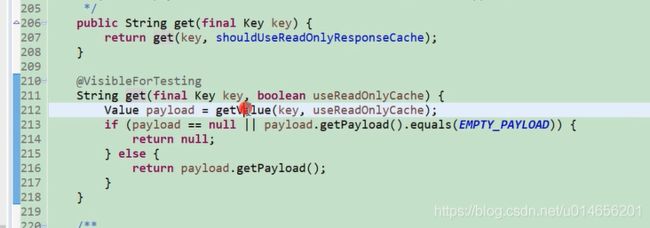
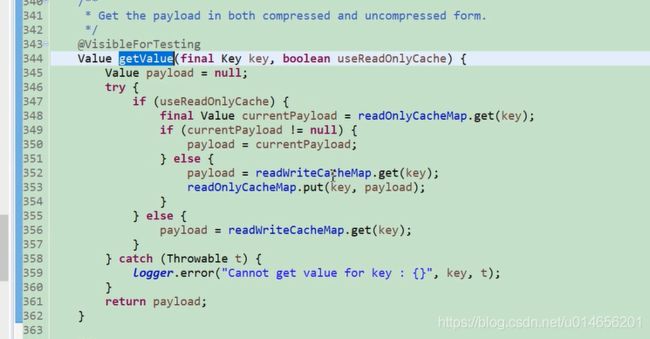
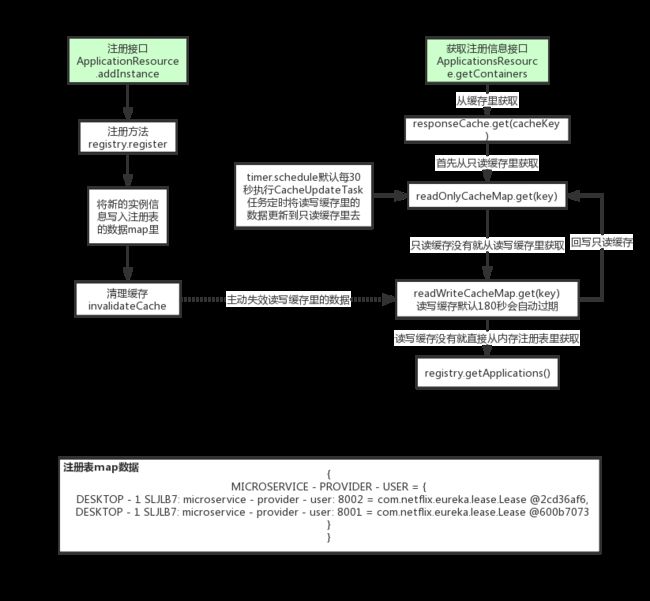
如果是只读缓存,先从读缓存中获取,如果对缓存 为空再从读写缓存中获取,并返回。 那问题又来了读写缓存也没有呢,图66
图65

图66
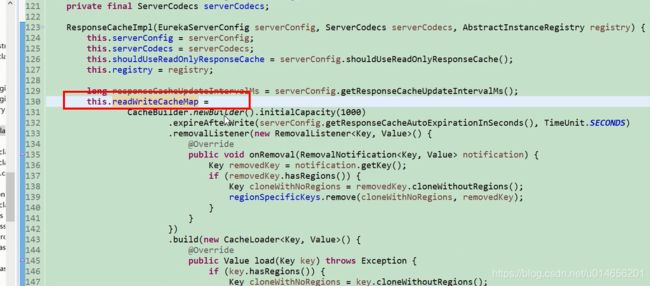
readWriteCacheMap 初始化, 初始化1000的容器,默认写多长时间实现,后面单位为秒。
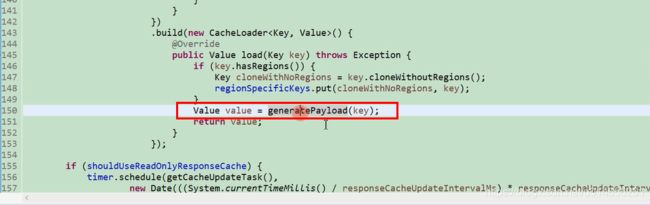
默认从这个里面获取。
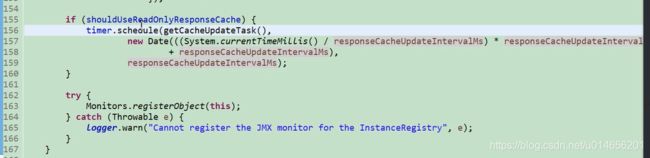
每30秒回刷新 我们的只读缓存
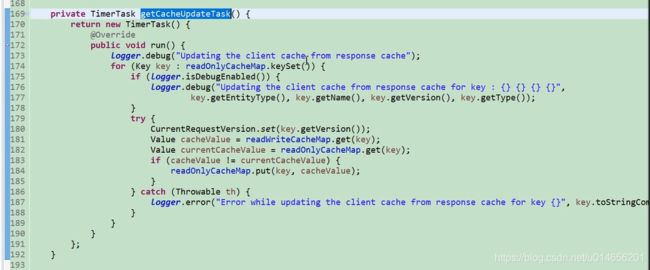
比较只读缓存和读写缓存的是否一致,不一致就更新。
图67
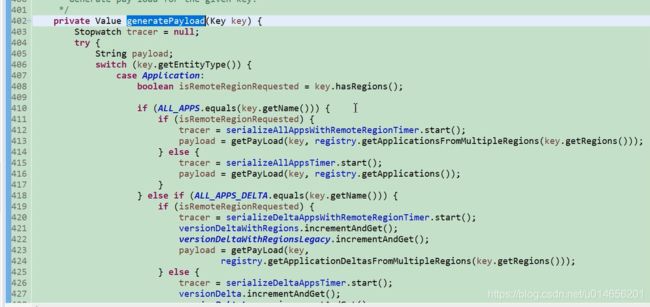
我们看All_Apps 411行亚马逊的不用看,416行重点。
图68

图69
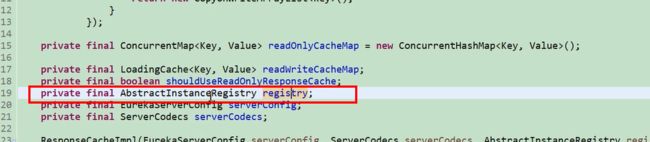
registry 是一个服务注册的一个注册表。

服务端注册的接口
图70
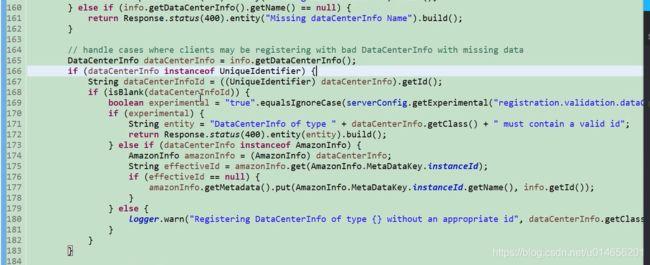

图71

图72

图 73
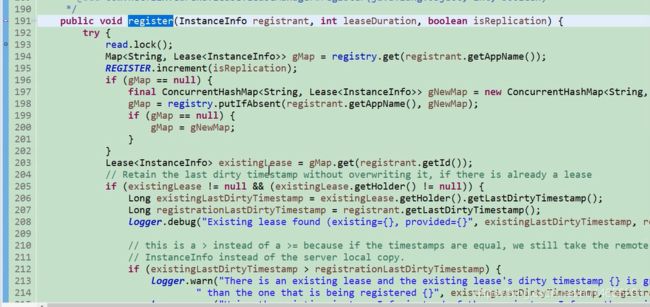
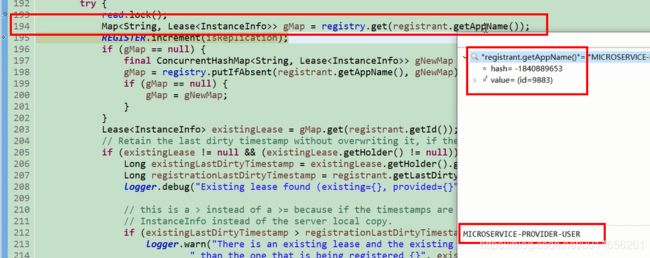
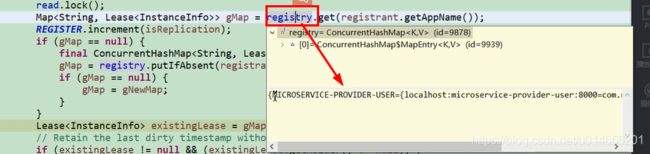

真正注册表的结构是这样
首先获取一个gmap 如果为空直接放一下,
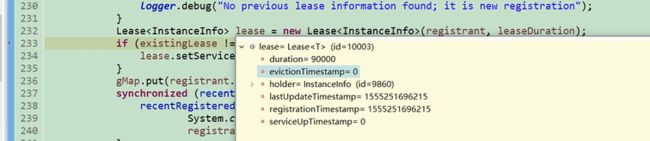
还有上次更新时间,注册时间,启动时间
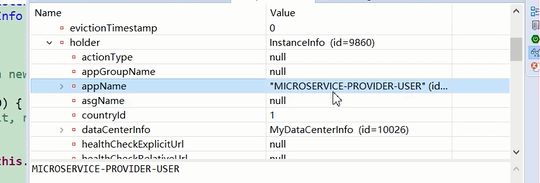
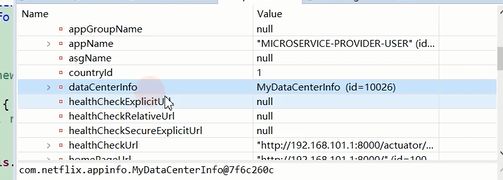
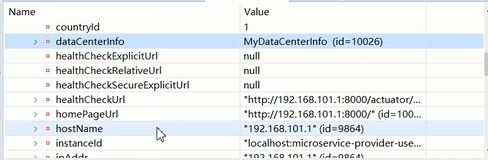

历史信息就是客户端注册过来的信息。

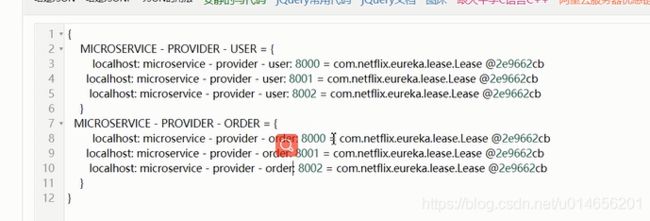
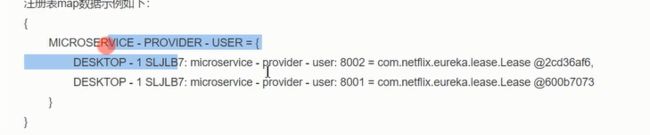
具体的示例。
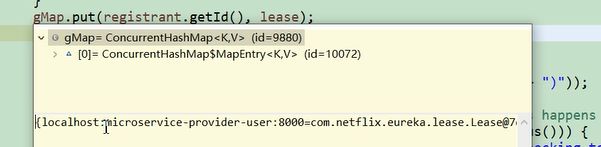

注册表的示例
放完之后的gMap

注册完之后,缓存失效。
图74

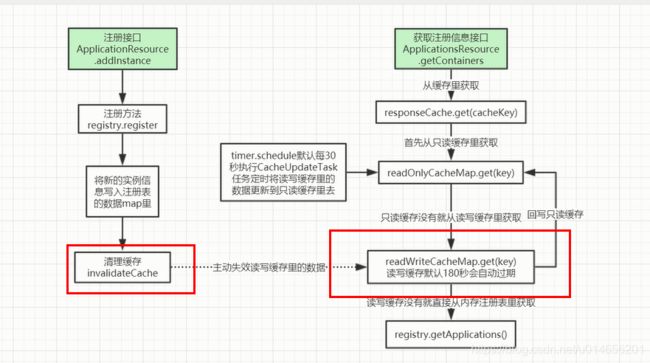
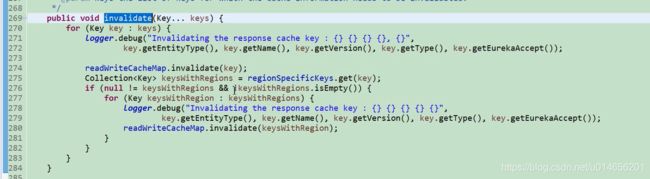 为什么要用两级缓存,解决频繁读写,读写分离; 比如想淘宝,这种大型的互联网公司,有几千个客户端,每30秒都要定时执行心跳任务续期,需要更新注册表的最后更新时间,每30分钟需定时拉新最新的注册表,读和写并且是互斥,这样的性能并不是很高。这样读的时候只读我读的map,写的时候只写那个 registy, 两个缓存定时失效。
为什么要用两级缓存,解决频繁读写,读写分离; 比如想淘宝,这种大型的互联网公司,有几千个客户端,每30秒都要定时执行心跳任务续期,需要更新注册表的最后更新时间,每30分钟需定时拉新最新的注册表,读和写并且是互斥,这样的性能并不是很高。这样读的时候只读我读的map,写的时候只写那个 registy, 两个缓存定时失效。
图75
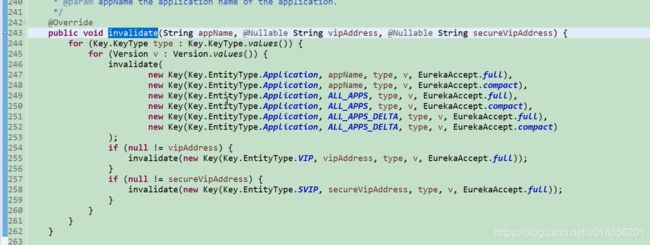
问题来了,如果将新的示例信息注册大数据map中,清理缓存,invalidateCache readWriteCacheMap 失效了,单是readOnlyCacheMap没有失效。数据不是不一致了吗 ,因为他是满足CAP 中的 AP思想 高可用的最终一致性。

图76
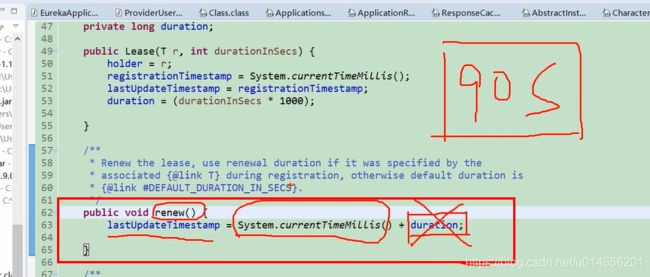
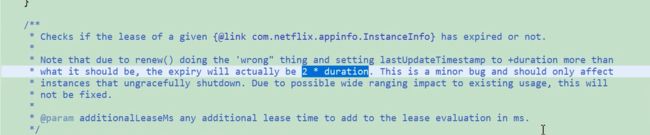
 evictionTimestamp标识当前的示例已经过期了 默认为0 已经做了标记,但是这个示例还在注册表还没有被移除 。lastUpdateTimesTamp上次续约的时间。
evictionTimestamp标识当前的示例已经过期了 默认为0 已经做了标记,但是这个示例还在注册表还没有被移除 。lastUpdateTimesTamp上次续约的时间。
剔除逻辑的bug,并不是90秒剔除,而是180秒剔除,因为有这个bug,duration默认是90秒。只需要更新当前时间就可以了,不应该加duration了。‘’看方法注释。

相关文档总结:感谢诸葛老师
Eureka服务端Jersey接口
Eureka服务端源码分析.png
Eureka客户端源码分析
