


在锁操作的客户端打日志
获取锁:
T13:31:51.230redisname-lock:hsetnx
E13:31:51.230GetConnection10.X.X.X
T13:31:51.231redisname-lock:hsetnx
设置超时时间:
T13:31:51.230redisname-lock:hsetnx
E13:31:51.230GetConnection10.X.X.X
T13:31:51.231redisname-lock:hsetnx
释放锁:
T13:31:51.230redisname-unlock:hsetnx
E13:31:51.230GetConnection10.X.X.X
T13:31:51.231redisname-unlock:hsetnx
从上面数据可以看到一个正常分布式锁操作,操作时间在1ms,因为是从客户端获取的,因为粒度只能是毫秒级。再从服务端看看是什么情况。
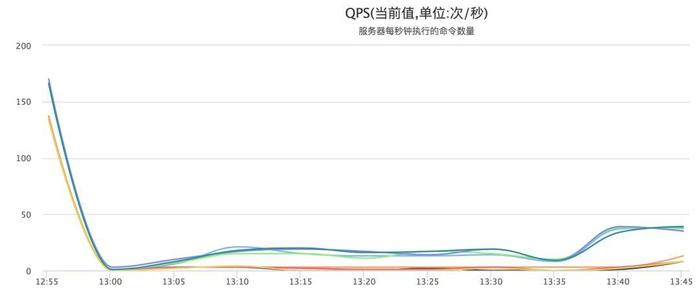
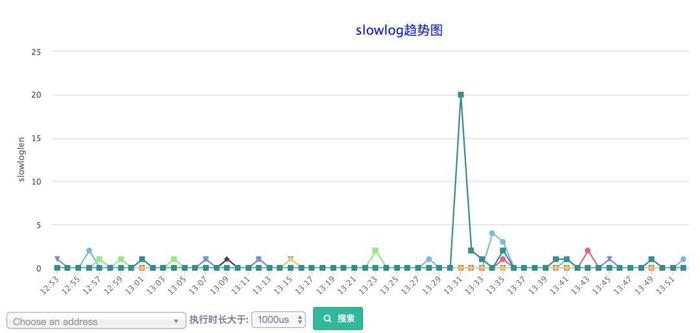
上面显示了大于1ms的慢查询情况,可以看到每秒几百个的QPS不会造成分布式锁本身的慢查询。耗时超过1ms的都是集群操作,分布式锁的lock和unlock操作时间都是us级。
如果lock和unlock中间没有任何逻辑的理想情况下,同一个锁可以支持每秒:
1000ms/ (1ms的lock+1ms的设置超时+1ms的unlock)=333(个)
结论
分布式锁本身lock和unlock耗时是us级,在理想情况下大概可支持每秒1000个原子操作,300多个从分配到释放流程结束。

举个栗子?:
秒杀场景下,秒杀的产品有1000件。如果使用了分布式锁,理想情况下可以在1m内处理完所有的秒杀成功请求,其他请求直接返回秒杀结束。
既然秒杀都没有问题,一般情况下,分布式锁不会是性能瓶颈。如果出现了性能问题,首先先排查业务逻辑。
目录
1:一个线程里lock成功,unlock失败?
2:有哪些抓手可以确定哪些逻辑耗时太多?
3:锁内部要避免的操作有哪些?
4:循环获取锁的时间间隔怎么算合理?
5:获取锁重试次数怎么算合理?
6:多次获取锁失败原因有哪些?
7:加了分布式锁还出现了并发问题?
1:一个线程里lock成功,unlock失败?
Q: 日志里报了多次的unlock失败,什么原因?
A: 之前的代码里try finally模式的unlock,是否lock成功都会unlock。
Q:加上了lock成功才unlock,还是有unlock失败?
A:这是锁住的逻辑耗时太多,超过了expire的时间,自动释放锁了。
2:有哪些抓手可以确定哪些逻辑耗时太多?
Q: 日志可以吗?
A: 目前的日志可以找到有问题的traceId,看整个链路都进行了哪些处理,大概几步时间消耗,但是具体sql的耗时分析没有
Q:CAT监控可以吗?
A:CAT监控可以找到耗时多的几个请求,看到每条sql的耗时情况,超过5秒的sql都是需要注意的
3:锁内部要避免的操作有哪些?
Q:逻辑上的?
A:避免显式的和隐式的循环。如:.stream().
Q:性能上的?
A:数据查询的条件是否建立了索引
4:循环获取锁的时间间隔怎么算合理?
A:获取锁与服务器通讯时间可以忽略不计,在跨机房的情况下理论上也不超过2ms
所以锁可以获取到的时间=一段分布式锁中间执行时间平均值
5:获取锁重试次数怎么算合理?
A:获取锁的重试次数理论上如果获取锁时间间隔合理的话,就与允许的同时扩容最大容器数接近,不大于最大容器数20%。
6:多次获取锁失败原因有哪些?
A:如果不符合可获取到的时间间隔计算,则考虑是否特定场景下有耗时操作。具体可参考 3:锁内部要避免的操作有哪些?
7:加了分布式锁还出现了并发问题?
Q:锁获取失败是怎么处理的?
A:锁获取失败并没有按请求失败处理,而是在无锁状态下继续执行会引发并发问题。
Q:锁获取成功了还是出现并发问题?
A:执行太慢了,超过了expire的时间锁失效了。

简介:
一个有逻辑、有观点、有温度、有调性的技术公众号~
作者是一个有日本东京、美国硅谷工作经验,有百项技术发明专利,十一年程序媛。
欢迎一起探索技术~
