Java 中文分词引擎对比
本文包含基于Java的Ansj、jieba、word分词引擎的安装、简单调用、功能介绍。
一、jieba
源码:https://github.com/huaban/jieba-analysis
1、支持分词模式
* Search模式,用于对用户查询词分词
* Index模式,用于对索引文档分词
2、特性
* 支持多种分词模式
* 全角统一转成半角
* 用户词典功能
* conf 目录有整理的搜狗细胞词库
* 因为性能原因,最新的快照版本去除词性标注。
3、新特性:tfidf算法提取关键词
安装
在github上下载源码,解压。
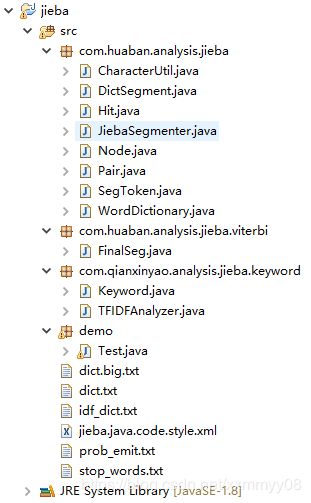
创建自己的项目,将源码中的相应文件拷贝到自定义文件中。需要拷贝的文件如下。
jieba-analysis-master\src\main\java\com\huaban\analysis\jieba全部8个文件;
jieba-analysis-master\src\main\java\com\huaban\analysis\jieba\viterbi全部1个文件;
jieba-analysis-master\src\main\java\com\qianxinyao\analysis\jieba\keyword全部2个文件。
jieba-analysis-master\src\main\resources下的全部6个文件。
完成后自定义项目目录如下:
简单调用
public class Test {
public static void main(String[] args) throws IOException{
JiebaSegmenter segmenter = new JiebaSegmenter();
String[] sentences =
new String[] {"我叫李太白,我是一个诗人,我生活在唐朝" };
int topN=5;
TFIDFAnalyzer tfidfAnalyzer = new TFIDFAnalyzer();
for (String sentence : sentences) {
System.out.println(segmenter.process(sentence, JiebaSegmenter.SegMode.SEARCH).toString());
List list=tfidfAnalyzer.analyze(sentence,topN);
for(Keyword word:list)
System.out.println(word.getName()+":"+word.getTfidfvalue()+",");
}
}
} 结果
main dict load finished, time elapsed 890 ms
model load finished, time elapsed 48 ms.
[[我, 0, 1], [叫, 1, 2], [李太白, 2, 5], [,, 5, 6], [我, 6, 7], [是, 7, 8], [一个, 8, 10], [诗人, 10, 12], [,, 12, 13], [我, 13, 14], [生活, 14, 16], [在, 16, 17], [唐朝, 17, 19]]
李太白:0.2191,
唐朝:0.1517,
诗人:0.1373,
生活:0.0927,
一个:0.0564,
二、word
源码:https://github.com/ysc/word
word分词是一个Java实现的分布式的中文分词组件,提供了多种基于词典的分词算法,并利用ngram模型来消除歧义。
能准确识别英文、数字,以及日期、时间等数量词,能识别人名、地名、组织机构名等未登录词。
能通过自定义配置文件来改变组件行为,能自定义用户词库、自动检测词库变化、支持大规模分布式环境,能灵活指定多种分词算法,能使用refine功能灵活控制分词结果,还能使用词频统计、词性标注、同义标注、反义标注、拼音标注等功能。
提供了10种分词算法,还提供了10种文本相似度算法,同时还无缝和Lucene、Solr、ElasticSearch、Luke集成。
注意:word1.3需要JDK1.8
安装
github上提供了网址下载编译好的jar包。解压。
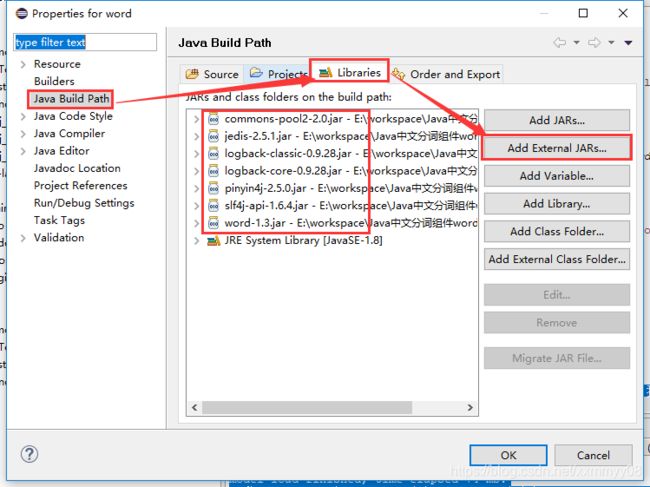
在自定义文件夹中导入jar包。
导入方法如下:
右击项目,选择properties。弹出下框,选择需要的jar包。
简单调用
public class Test {
public static String automaticSelection(String title) {
//移除停用词进行分词
List list = WordSegmenter.seg(title);
//保留停用词
List lists = WordSegmenter.segWithStopWords(title);
return listWordToString(lists);
}
//将List转为String
private static String listWordToString(List words) {
StringBuffer sb = new StringBuffer();
for (Word word : words) {
sb.append(word.getText());
sb.append("、");
}
return sb.toString();
}
public static void main(String[] args) {
String result = automaticSelection("我叫李太白,我是一个诗人,我生活在唐朝");
System.out.println(result);
}
} 结果
我、叫、李太白、我、是、一个、诗人、我、生活、在、唐朝、
三、Ansj
源码:https://github.com/NLPchina/ansj_seg
使用手册:http://nlpchina.github.io/ansj_seg/
这是一个基于n-Gram+CRF+HMM的中文分词的java实现.
分词速度达到每秒钟大约200万字左右(mac air下测试),准确率能达到96%以上
目前实现了.中文分词. 中文姓名识别 . 词性标注、用户自定义词典,关键字提取,自动摘要,关键字标记等功能
可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目.
安装
github上提供了ansj_seg.jar和nl-lang.jar的下载网址。
下载后,导入到自定义项目中,导入方法如上所示。
简单调用
public class Test {
public static void main(String[] args) {
String str = "我叫李太白,我是一个诗人,我生活在唐朝" ;
Result result = ToAnalysis.parse(str);
System.out.println(result);
KeyWordComputer kwc = new KeyWordComputer(5);
Collection keywords = kwc.computeArticleTfidf(str);
System.out.println(keywords);
}
} 结果
我/r,叫/v,李太白/nr,,/w,我/r,是/v,一个/m,诗人/n,,/w,我/r,生活/vn,在/p,唐朝/t
[李太白/24.72276098504223, 诗人/3.0502185968368885, 唐朝/0.8965677022546215, 生活/0.6892230219652541]
四、总结
1、速度
速度由快到慢:jieba,Ansj,word
个人觉得简单的一句话,word用时就挺久的,也许是因为要加载很多的文件,但分词的速度与待分词字符串长度是否有关还有待研究。
2、因为个人接下来的研究需要用到词性标注,而新版本jieba不提供该功能,所以很遗憾不能使用。当然也可以自己在分词结束后的基础上根据词性表对应找到词性。
3、github中提示的maven,这是一个类库管理工具,也就是说如果我们创建的是maven项目,就可以通过项目中的pom.xml文件引入项目需要的jar包,而不是像本文中一个一个导入jar包。本文的导入jar包方式和maven方式任选一个就好。