Python初学-变量这小东西
Python初学-变量这小东西
1. 和C++,Java的区别
- 动态类型
- 查看变量a的类型的方法有
type(a),a.__class__或者a.__doc__
- 查看变量a的类型的方法有
- 一切都是对象:python中一切变量都是对象
2. 数字
- 自动转换类型<-动态类型
decimal
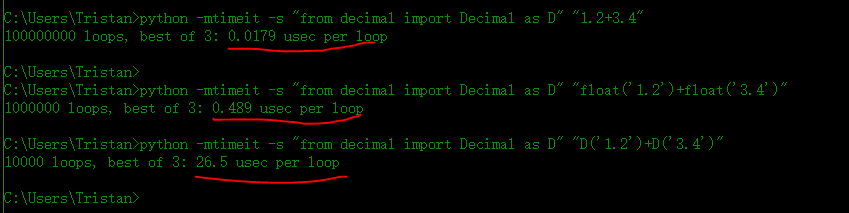
- 缺点:执行时间会比float长很多,从下图中可以明显看到时间的剧增
- 优点:当你的运算结果出现了
OL等数据类型不够的情况时,用decimal可以很方便的解决这个问题。输入from decimal import Decimal as D以后就可以使用decimal了,如:
-
from decimal import Decimal as D
D(0.3)/D(3)
D(1)/D(2**10000)
-
- 缺点:执行时间会比float长很多,从下图中可以明显看到时间的剧增
常用库
- math
- random
- numpy
- 产生数组或矩阵,正态分布的随机数
- 矩阵运算
- scipy
- 拟合,线性插值,样条插值
- 积分,微分
- 解非线性方程
- 滤波器设计
在这里纪念一下我用python画出来的第一张图:
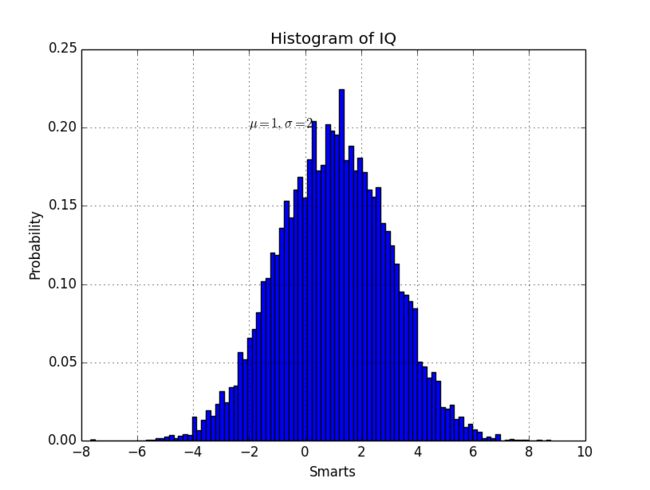
相应的代码如下:
import numpy as np
from matplotlib import pyplot as plt
mu ,sigma =1,2
s=np.random.normal(mu,sigma,10000)
n,bins,patches=plt.hist(s,100,normed=True)
plt.xlabel('Smarts')
plt.ylabel('Probability')
plt.title('Histogram of IQ')
plt.text(-2,.2,r'$\mu=1,\ \sigma=2$')
plt.grid(True)
plt.show()3. 字符串
切片,索引
s="use python do something"
s[1]
s[-1] 最后一个字符,同理s[-2],s[-3]
s[1:3] [start : stop],其中stop那位不显示
s[1:6:2] [start : stop : step]
s[:-1] 除了最后一位
s[:] 和s的效果是一样的
s.split() 把字符串分解成一个list
a=s.split(' ')
b=','.join(a)把list再连接成str
常用方法
"let us "+s两个字符串连接
s*2 重复s两次,但s本身没改,返回的一个新的str
s.replace('python','java')替换
print "%s like %s" %('we','python') 把百分号后面的字符串依次填入前面的百分号
禁止转义r’ ‘
s='lalal\nlalllg'
print s 输出的结果是如下的两行
lalal
lalllg
print r'lalal\nlalllg这样输出就不会转义,直接输出
lalal\nlalllg
如果在程序里面如果要用到中文的时候,需要在文件头加上# coding: utf-8
4. 字符串-re模块
是用来处理正则表达式的模块
re: Regular Expression
- re.match(p,text)
- re.search(p,text)
- re.findall(p,text)
- re.split(p,text)
- re.sub(p,s,text)
在待处理的字符串如'hello\n'前面加上字母r可以禁止字符串转义
整体介绍:
11个元字符 ,\,^,$,.,|,?,*,+,(),[],{}
具体分类:
1. 特殊含义,\,.,
2. 可选,|,[],
3. 重复,*,+,?,{},(贪婪模式)
4. 6个字符类,\d,\D,\s,\S,\w,\W
5. 4个位置类,\b,\B,\A,\Z,(^,$)
6. 分组,(),
5. 日期和时间
datatime:
1. Datatime.date.today() #日期
2. datetime.datetime.now()#日期和时间
3. datetime.timedelta(day=1000)#1000天之后
4. Isoformat(),strftime()#打印格式的问题
5. strptime()#字符串转换
time:
1. Datetime.time(12,11,30)
2. Time.time() #实际时间
3. Time.clock() #cpu时间
4. Time.sleep() #以s为单位,等待一段时间`
6. 列表
常用操作:
1. a_copy=a[:]
2. a.append(300) #加上一个元素
3. a.insert(1,50) #把50插入到下标1的位置
4. a.pop() #把第一个元素给弹出来
5. a.sort() #按照value值排序
6. a.reverse() #把a这个list反过来
7. del a[1] #删去下标为1的元素 b=[a,a_ref,a_copy]
8.#b是三个列表嵌套起来的列表 c=[1, 2, ‘123’, ‘abc’]
9.#多种类型并存 +, *
10.#运算符重载 Count(val)` #对某个元素计数,多态的方法
11.
7. 元组
元组相当于一个不可变的list
如(a, b, c)不能在原处修改
常用操作:
1. index
2. count,对某个元素计数
3. +, * #运算符重载
4. 转换:tuple()
8. 字典
是一个没有顺序的数据结构,是个散列表,适合插入、查询操作,用空间换了速度
Key不一定是字符串,但一定是不可变的对象:数字、字符串、元组
有排序的方法:
[(k,dict[k])] for k in sorted(dict.keys())]
或者直接调用sorted()函数,以后再说,这个比较复杂
常用操作
1. dictName.Keys(), dictName.values(), dictName.items()
在dictName.items()这个方法返回的内容中,键值对将会以tuple元组的形式返回。
需要注意的是在python2里,这两个方法返回的是一个list,而在python3里,返回的则是dict_keys(…),这样做事有利的,特别是字典较大的时候,因为不需要用时间和内存去产物和存储一个你有可能不会用到的list,如果你真的需要返回一个list,可以调用
list()方法。—《introducing Python》
dictName.Get()dictName.Update(another dict)
这个方法能够用来combine dictdel dictName('key')
删去某个键值对Clear
清空字典内的所有内容
再谈引用和拷贝
- 引用
L=[4, 5, 6]
X=L*4, Y=[L]*4
L[1]=0
print X, Y #X不会变,而Y会变,[L]*4里面是引用浅拷贝
- 不考虑嵌套,只拷贝第一层
D.copy()或者copy.copy(D)- 列表L[:]
深拷贝
copy.deepcopy(D)
产生dict的操作,概括一下:
# coding: utf-8
#----------用dict直接生成字典
name_age=(('xiaoli',33), ('xiaowang',20), ('xiaozhang',40))
a=dict(name_age)
b=dict(xiaoli=33,xiaowang=20,xiaozhang=40)
#----------如何将两个等长度的list合并成dict
text = 'C++ python shell ruby java javascript c'
code_num = [1,2,3,4,5,6]
text_list=text.split(' ')
code_dict = dict(zip(text_list,code_num))
#zip把两个list中的对应元素组成元组
#----------key, keys, items, values
code_dict['python']
code_dict.keys()
code_dict.valuse()
code_dict.items()
#----------get
a=code_dict.get('fortran',None)
#----------ref and copy
a_ref = code_dict
a_copy = code_dict.copy()
#----------update, del, copy, clear
other_code = {'php':7,'objective-c':8}
code_dict.update(other_code)
del code_dict['C++']
a_ref
a_copy
a_ref.clear()
#----------sort key and values
[(k,a_copy[k]) for k in sorted(a_copy.keys())]发现一个对List,Dictrionary,Tuple三者联系和区别的回答写的非常好,引用一下:
一、首先,看看三者最基本的区别:
1. List是顺序的,可变的.
2. Dictrionary是无顺序的,可变的.Dictionary是内置数据类型之一,它定义了键和值之间一对一的关系.每一个元素都是一个 key-value 对,整个元素集合用大括号括起来.
3. Tuple 是顺序的,不可变 list.一旦创建了一个 tuple 就不能以任何方式改变它.定义 tuple 与定义 list 的方式相同,除了整个元素集是用小括号包围的而不是方括号
你说的对,Tuple 是不可变 list.一旦创建了一个 tuple 就不能以任何方式改变它.二、Tuple 与 list 的相同之处
定义 tuple 与定义 list 的方式相同,除了整个元素集是用小括号包围的而不是方括号.
Tuple 的元素与 list 一样按定义的次序进行排序.Tuples 的索引与 list 一样从 0 开始,所以一个非空 tuple 的第一个元素总是 t[0].
负数索引与 list 一样从 tuple 的尾部开始计数.
与 list 一样分片 (slice) 也可以使用.注意当分割一个 list 时,会得到一个新的 list ;当分割一个 tuple 时,会得到一个新的 tuple.三、Tuple 不存在的方法
- 您不能向 tuple 增加元素.Tuple 没有 append 或 extend 方法.
- 您不能从 tuple 删除元素.Tuple 没有 remove 或 pop 方法.
- 您不能在 tuple 中查找元素.Tuple 没有 index 方法.
- 然而,您可以使用 in 来查看一个元素是否存在于 tuple 中.四、用 Tuple 的好处
Tuple 比 list 操作速度快.如果您定义了一个值的常量集,并且唯一要用它做的是不断地遍历它,请使用 tuple 代替 list.
如果对不需要修改的数据进行 “写保护”,可以使代码更安全.使用 tuple 而不是 list 如同拥有一个隐含的 assert 语句,说明这一数据是常量.如果必须要改变这些值,则需要执行 tuple 到 list 的转换.五、Tuple 与 list 的转换
Tuple 可以转换成 list,反之亦然.内置的 tuple 函数接收一个 list,并返回一个有着相同元素的 tuple
而 list 函数接收一个 tuple 返回一个 list.从效果上看,tuple 冻结一个 list,而 list 解冻一个 tuple.六、Tuple 的其他应用
一次赋多值
>>> v = (‘a’,’b’,’e’)
>>> (x,y,z) = v
9. 文件
常用操作
1. F=open(path,'r')返回对象为file-like object,还可以是内存,网络等。
- path是路径(包括文件名)
- r是模式,模式还有w和a
- r代表的是read
- w代表的是write,它会把原文件清空,如果这个文件不存在,则会新建一个文件
F.read()#读一个字节或者一个单位F.reanline()F.write()F.close()
对中文的支持
import codecs
f=codecs.open(filename,mode,encoding)文件操作
import os
os.path.exists(filename)
os.rename(old,new)相关的第三方库:
- Shelve库
- Pickle/cPickle库
10. 作业
编写验证e-mail的正则表达式。邮箱名可以是英文字母或数字或
-, _符号,邮箱后缀网址名可以是英文字母或数字,域名可以是com, org, edu
如:[email protected]利用随机函数产生一个用户的用户名,密码,并利用文件将用户名和密码保存下来。
上面的文件中密码没有加密,不安全,请将文件内容取出后将密码字段通过md5的库处理后,再保存至另一个文件。
>import hashlib #md5加密处理库 hashlib.md5(password).hexdigest()()
作业的解答
- Solution:
# coding: utf-8
#copyRight by TristanHuang
import re
text = '[email protected]'
#match the name of e-mail
print re.findall('([a-zA-Z0-9-_]+)@([a-zA-Z0-9]+)\.(com|org|edu)',text)
#reference answer
import re
text='[email protected] [email protected] [email protected] [email protected] aaa@111 com'
print re.findall(r'(\w+[-\w]*)@([a-zA-Z0-9]+)\.(com|org|edu)',text)- solution:
# coding utf-8
import random
character = 'abcdefghijklmnopqrstuvwxyz0123456789'
len=len(character)
#产生用户名
a=[0]*4
a[0]=character[random.randint(0,len-1)]
a[1]=character[random.randint(0,len-1)]
a[2]=character[random.randint(0,len-1)]
a[3]=character[random.randint(0,len-1)]
name = ''.join(a)
#产生密码
b=[0]*6
b[0]=character[random.randint(0,len-1)]
b[1]=character[random.randint(0,len-1)]
b[2]=character[random.randint(0,len-1)]
b[3]=character[random.randint(0,len-1)]
b[4]=character[random.randint(0,len-1)]
b[5]=character[random.randint(0,len-1)]
password = ''.join(b)
#创建和写入文件
f = open('a.txt','w')
f.write(name+','+password+'\n')
f.close()- solution
#读入文件
f = open('a.txt','r')
name_password = f.readline().strip().split(',')
#md5加密
import hashlib
password_md5 = hashlib.md5(name_password[1]).hexdigest()
#重新写入文件
f = open('a_md5.txt','w')
f.write(name_password[0]+','+password_md5+'\n')
f.close()