跳表Skiplist
前言 二分查找
一般而言,针对在某个数组中查找等于某个给定值的数组元素的下标问题,我们一般可以想到二分查找(Bianry Search)的方法来实现时间复杂为O(logn)的查询性能。
代码如下所示:
while(low<=high){
int mid=low+(high-low)/2;
if(s[mid]==n) return mid;
esleif(s[mid]n)
high=mid-1;
}
二分查找时间复杂度低,用来查找数据效率很高,但是二分查找的应用场景局限性很大。二分查找依赖的是顺序表结构,简单点说是数组 支持下标随机访问,如果换成链表 链表查询常规的时间复杂度是O(n)),而且二分查找针对的是有序数据(无序的数据在运用二分查找前需要进行排序操作),所以二分查找不适合有频繁插入删除擦操作的数据。
那么相对于链表,我们也想实现能够快速查询元素 时间复杂度低于O(n),可以实现吗?? 答案是可以的,这就引出了本篇文章要讲述的知识点跳表
1. 什么是跳表?
对于一个单链表,即使链表是有序的,如果我们想要在其中查找某个数据,也只能从头到尾遍历链表,这样效率自然就会很低,时间复杂度是O(n)。
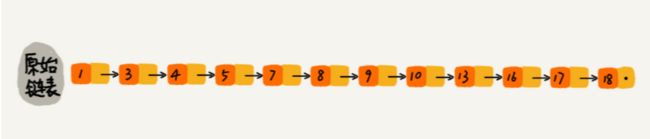
假如我们对链表建立一级索引,具体而言就是每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引或者索引层,如下图所示。

这时候,我们要查找某一个数据的时候,就可以先在索引里面查找出一个大的范围,然后再下降到原始链表中精确查找。
比如,我们要查找 16,我们发现 16 位于 13 和 17 之间,这时候,我们就从 13 的地方下降到原始链表,然后再往后查询。原来我们查找 16,需要遍历 10 个结点,现在只需要遍历 7 个结点。
我们发现,加一层索引后,查找一个结点需要遍历的次数减少了,也就是查找效率提高了。
那么我们再多加一级索引呢?效果会不会有更大提升?
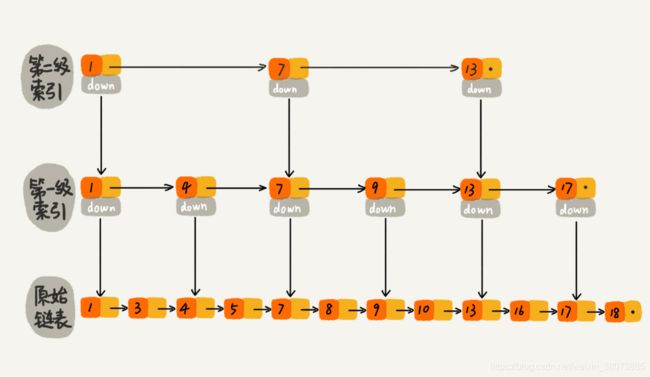
这一次,我们只需要遍历 6 个结点了。
数据量不大的时候这种方法可能效率提高得还不是很明显,下面看一个包含 64 个结点的例子,这次我们建立了五级索引。
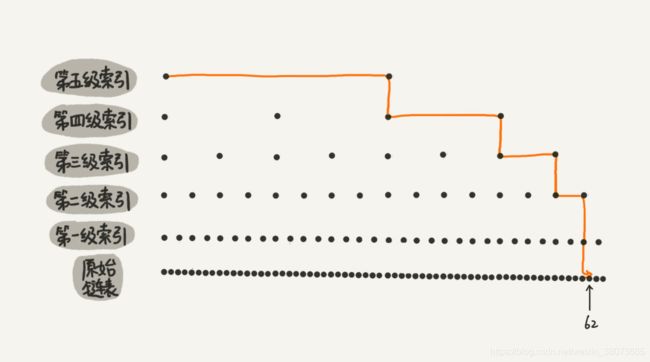
如果链表中没有采取索引这种方法,查找 62 的时候原来需要遍历 62 次,现在只需要 11 次即可。针对链表长度比较大的时候,构建索引查找效率的提升就会非常明显。
上述这种链表基础上加多级索引的结构,就是跳表。我们可以看到跳表确实是可以有效减少查询次数的 提高链表的查询效率。
2. 跳表查询的性能分析?
如果链表中总共有 n 个结点,那么第一级索引就有 n/2 个结点,第二级索引就有 n/4 个结点,以此类推,那么第 k 级索引就有 n/2k 个结点。假设索引有k级,如果最高级索引有 2 个结点,通过n/2k=2得到总的索引级数 k=log2n−1,如果我们算上原始链表的话,那也就是总共有 log2n 级。我们在跳表中查询某个数据时,如果每一层访问m个节点,那跳表中查询一个数据的时间复杂度是O(mlogn)
在第 k 级索引中,假设我们要查找的数据为 x,当我们查找到 y 结点时,发现 y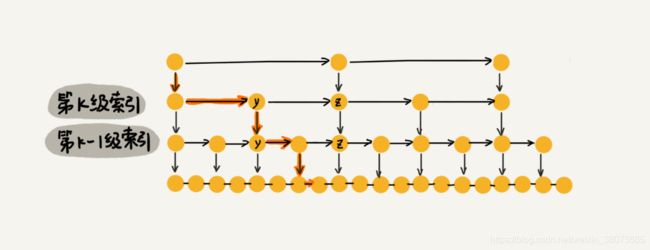
而总的级别数为 log2n,因此查找的时间复杂度就为 O(logn)。
跳表查找的时间复杂度和二分查找一样,实际上跳表是以空间来换时间的设计思路。
跳表的所有额外索引结点总数为 n/2+n/4+n/8+…+4+2=n−2,所以跳表的空间复杂度为 O(n)。
但如果我们每3个结点建立一个索引,这时候额外需要的结点总数为 n/2,虽然空间复杂度依然为 O(n),但减少了一半的索引节点存储空间。
实际上,在实际开发中,原始链表中存储的可能是很大的对象,而索引结点只需要存储关键值和几个指针,其额外占用的空间可以被忽略掉。
3. 跳表实现高效的动态插入和删除
跳表这种动态数据结构,支持查找操作,还支持动态的插入、删除操作,而且插入 删除的时间复杂度是O(logn)
插入数据
下图为插入一个数据的过程:

删除数据
从链表中删除结点的时候,如果结点在索引中也有出现,那么我们除了要删除原始链表中的结点,还要删除索引中的。
跳表索引动态更新
当我们不停地往跳表中插入数据的时候,如果我们不更新索引,就有可能出现某两个结点之间数据非常多的情况。极端情况下,跳表还会退化为单链表。

因此,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表结点变多了,索引值就相应地增加一些,避免查找 插入 删除操作的性能下降。
当我们往跳表中插入数据的时候,我们可以选择同时也将这个数据插入到部分索引层中。而插入到哪些索引层中,则由一个随机函数生成一个随机数字来决定。如果这个数字为 K,那我们就将数据插入到第一级到第 K 级索引中。

跳表的应用
Skip list(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的。Skip list让已排序的数据分布在多层链表中,以0-1随机数决定一个数据的向上攀升与否,通过“空间来换取时间”的一个算法,在每个节点中增加了向前的指针,在插入、删除、查找时可以忽略一些不可能涉及到的结点,从而提高了效率。
在Java的API中已经有了实现:分别是
- 1: ConcurrentSkipListMap. 在功能上对应HashTable、HashMap、TreeMap。 在并发环境下,Java也提供ConcurrentHashMap这样的类来完成hashmap功能。
- 2: ConcurrentSkipListSet . 在功能上对应HashSet.
确切来说,SkipList更像Java中的TreeMap。TreeMap基于红黑树(一种自平衡二叉查找树)实现的,时间复杂度平均能达到O(log n),TreeMap输出是有序的,ConcurrentSkipListMap和ConcurrentSkipListSet 输出也是有序的(本博测试过)。下例的输出是从小到大,有序的。
package MyMap;
import java.util.*;
import java.util.concurrent.*;
/*
* 跳表(SkipList)这种数据结构算是以前比较少听说过,它所实现的功能与红黑树,AVL树都差不太多,说白了就是一种基于排序的索引结构,
* 它的统计效率与红黑树差不多,但是它的原理,实现难度以及编程难度要比红黑树简单。
* 另外它还有一个平衡的树形索引机构没有的好处,这也是引导自己了解跳表这种数据结构的原因,就是在并发环境下其表现很好.
* 这里可以想象,在没有了解SkipList这种数据结构之前,如果要在并发环境下构造基于排序的索引结构,那么也就红黑树是一种比较好的选择了,
* 但是它的平衡操作要求对整个树形结构的锁定,因此在并发环境下性能和伸缩性并不好.
* 在Java中,skiplist提供了两种:
* ConcurrentSkipListMap 和 ConcurrentSkipListSet
* 两者都是按自然排序输出。
*/
public class SkipListDemo {
public static void skipListMapshow(){
Map map= new ConcurrentSkipListMap<>();
map.put(1, "1");
map.put(23, "23");
map.put(3, "3");
map.put(2, "2");
/*输出是有序的,从小到大。
* output
* 1
* 2
* 3
* 23
*
*/
for(Integer key : map.keySet()){
System.out.println(map.get(key));
}
}
public static void skipListSetshow(){
Set mset= new ConcurrentSkipListSet<>();
mset.add(1);
mset.add(21);
mset.add(6);
mset.add(2);
//输出是有序的,从小到大。
//skipListSet result=[1, 2, 6, 21]
System.out.println("ConcurrentSkipListSet result="+mset);
Set myset = new ConcurrentSkipListSet<>();
System.out.println(myset.add("abc"));
System.out.println(myset.add("fgi"));
System.out.println(myset.add("def"));
System.out.println(myset.add("Abc"));
/*
* 输出是有序的:ConcurrentSkipListSet contains=[Abc, abc, def, fgi]
*/
System.out.println("ConcurrentSkipListSet contains="+myset);
}
}
Skip list的性质
- (1) 由很多层结构组成,level是通过一定的概率随机产生的。
- (2) 每一层都是一个有序的链表,默认是升序
- (3) 最底层(Level 1)的链表包含所有元素。
- (4) 如果一个元素出现在Level i 的链表中,则它在Level i 之下的链表也都会出现。
- (5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
ConcurrentSkipListMap具有Skip list的性质 ,并且适用于大规模数据的并发访问。多个线程可以安全地并发执行插入、移除、更新和访问操作。与其他有锁机制的数据结构在巨大的压力下相比有优势。
TreeMap插入数据时平衡树采用严格的旋转(比如平衡二叉树有左旋右旋)来保证平衡,因此Skip list比较容易实现,而且相比平衡树有着较高的运行效率。
小结
跳表通过在链表的基础上构建多级索引,实现高效的插入 删除 查找操作(时间复杂度是O(logn)),它是一种典型的空间换时间的数据结构。跳表的空间复杂度是O(n)。
跳表的原理并不复杂,相比于红黑树 他的原理好懂,但是代码实现起来并不简单,java实现代码以供读者参考。
本篇文章参考:
极客时间专栏《数据结构与算法之美》
https://blog.csdn.net/bigtree_3721/article/details/51291974