跳表 (图解)
-
疯狂创客圈 经典图书 : 《Netty Zookeeper Redis 高并发实战》 面试必备 + 面试必备 + 面试必备 【博客园总入口 】
-
疯狂创客圈 经典图书 : 《SpringCloud、Nginx高并发核心编程》 大厂必备 + 大厂必备 + 大厂必备 【博客园总入口 】
-
入大厂+涨工资必备: 高并发【 亿级流量IM实战】 实战系列 【 SpringCloud Nginx秒杀】 实战系列 【博客园总入口 】
1.1 跳表图解
跳表,是基于链表实现的一种类似“二分”的算法。它可以快速的实现增,删,改,查操作。
我们先来看一下单向链表如何实现查找:

链表,相信大家都不陌生,维护一个有序的链表是一件非常简单的事情,我们都知道,在一个有序的链表里面,查找某个数据的时候需要的时间复杂度为O(n).
怎么提高查询效率呢?如果我们给该单链表加一级索引,将会改善查询效率。

如图所示,当我们每隔一个节点就提取出来一个元素到上一层,把这一层称作索引,上层的索引节点都加上一个down指针指向原始节点。
当我们查找元素11的时候,单链表需要比较6次,而加过索引的两级链表只需要比较4次。当数据量增大到一定程度的时候,效率将会有显著的提升。
如果我们再加多几级索引的话,效率将会进一步提升。这种链表加多级索引的结构,就叫做跳表。
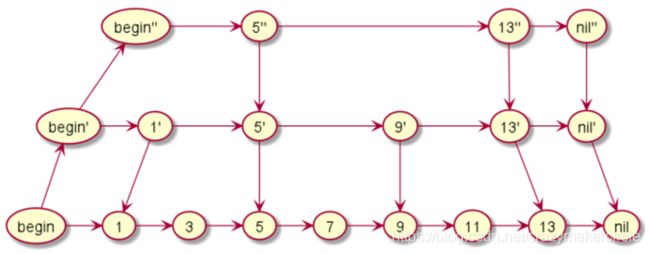
跳表的查询时间复杂度可以达到O(logn)
1.2 为什么Redis的有序集合SortedSet要使用跳表实现
跳表就是这样的一种数据结构,结点是跳过一部分的,从而加快了查询的速度。跳表跟红黑树又有什么差别呢?既然两者的算法复杂度差不多,为什么Redis的有序集合SortedSet要使用跳表实现,而不使用红黑树呢?
Redis 中的有序集合是通过跳表来实现的,严格点讲,其实还用到了散列表。
如果你去查看 Redis 的开发手册,就会发现,Redis 中的有序集合支持的核心操作主要有下面这几个:
-
插入一个数据;
-
删除一个数据;
-
查找一个数据;
-
按照区间查找数据(比如查找值在 [100, 356] 之间的数据);
-
迭代输出有序序列。
其中,插入、删除、查找以及迭代输出有序序列这几个操作,红黑树也可以完成,时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。对于按照区间查找数据这个操作,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。这样做非常高效。
当然,Redis之所以用跳表来实现有序集合,还有其他原因,比如,跳表更容易代码实现。虽然跳表的实现也不简单,但比起红黑树来说还是好懂、好写多了,而简单就意味着可读性好,不容易出错。还有,跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗
1.3 跳表的查询操作
假如我们要查询11,那么我们从最上层出发,发现下一个是5,再下一个是13,已经大于11,所以进入下一层,下一层的一个是9,查找下一个,下一个又是13,再次进入下一层。最终找到11。
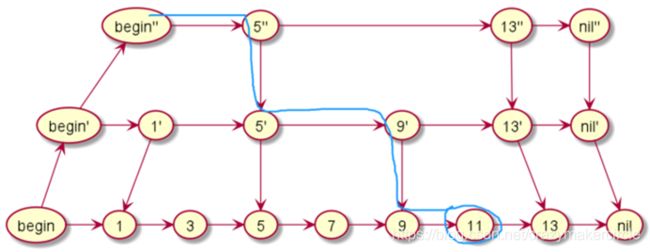
是不是非常的简单?我们可以把查找的过程总结为一条二元表达式(下一个是否大于结果?下一个:下一层)。理解跳表的查询过程非常重要,试试看查询其他数字,只要你理解了查询,后面两种都非常简单。
1.4 跳表的插入
接下来看插入,我们先看理想的跳跃表结构,L2层的元素个数是L1层元素个数的1/2,L3层的元素个数是L2层的元素个数的1/2,以此类推。从这里,我们可以想到,只要在插入时尽量保证上一层的元素个数是下一层元素的1/2,我们的跳跃表就能成为理想的跳跃表。那么怎么样才能在插入时保证上一层元素个数是下一层元素个数的1/2呢?很简单,抛硬币就能解决了!
假设元素X要插入跳跃表,很显然,L1层肯定要插入X。那么L2层要不要插入X呢?我们希望上层元素个数是下层元素个数的1/2,所以我们有1/2的概率希望X插入L2层,那么抛一下硬币吧,正面就插入,反面就不插入。那么L3到底要不要插入X呢?相对于L2层,我们还是希望1/2的概率插入,那么继续抛硬币吧!以此类推,元素X插入第n层的概率是(1/2)的n次。这样,我们能在跳跃表中插入一个元素了。
跳跃表的初试状态如下图,表中没有一个元素:

如果我们要插入元素2,首先是在底部插入元素2,如下图:
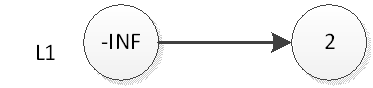
然后我们抛硬币,结果是正面,那么我们要将2插入到L2层,如下图
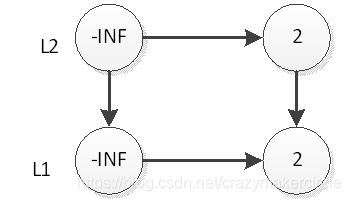
继续抛硬币,结果是反面,那么元素2的插入操作就停止了,插入后的表结构就是上图所示。接下来,我们插入一个新元素33,跟元素2的插入一样,现在L1层插入33,如下图:

然后抛硬币,结果是反面,那么元素33的插入操作就结束了,插入后的表结构就是上图所示。接下来,我们插入一个新元素55,首先在L1插入55,插入后如下图:
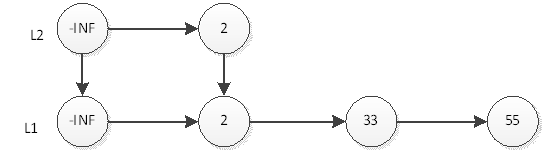
然后抛硬币,结果是正面,那么L2层需要插入55,如下图:

继续抛硬币,结果又是正面,那么L3层需要插入55,如下图:
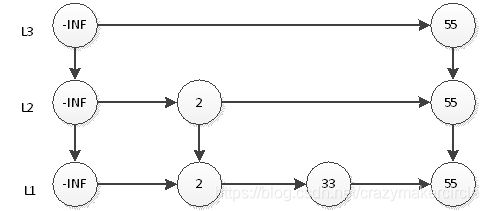
继续抛硬币,结果又是正面,那么要在L4插入55,结果如下图:

继续抛硬币,结果是反面,那么55的插入结束,表结构就如上图所示。
当然,不可能无限的进行层数增长。除了根据一种随机算法得到的层数之外,为了不让层数过大,还会有一个最大层数MAX_LEVEL限制,随机算法生成的层数不得大于该值。
以此类推,我们插入剩余的元素。当然因为规模小,结果很可能不是一个理想的跳跃表。但是如果元素个数n的规模很大,学过概率论的同学都知道,最终的表结构肯定非常接近于理想跳跃表。
当然,这样的分析在感性上是很直接的,但是时间复杂度的证明实在复杂,在此我就不深究了,感兴趣的可以去看关于跳跃表的paper。
1.5 跳表的删除
再讨论删除,删除操作没什么讲的,直接删除元素,然后调整一下删除元素后的指针即可。跟普通的链表删除操作完全一样。
插入和删除的时间复杂度就是查询元素插入位置的时间复杂度,这不难理解,所以是O(logn)。
回到◀疯狂创客圈▶
疯狂创客圈 - Java高并发研习社群,为大家开启大厂之门