细说Python爬虫爬取小说
我们爬取的是诗词名句网的三国演义,这个会爬了其余都同理了
(你需要一点css定位基础,因为里面用到了bs4数据解析。不过不会也没事按照我给的格式去做照样可以的)
准备阶段:
我们指定爬取的网站,UA伪装,还有创建了一个本地的fiction.txt文件,待会爬取到的小说写到这里面。(如果你没有bs4,和requests库你需要在你的dos命令行下输入 pip install bs4 回车
pip install requests 回车)
from bs4 import BeautifulSoup
import requests
url = 'http://shicimingju.com/book/sanguoyanyi.html'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
fp=open('./fiction.txt','w',encoding='utf-8')
我们先在站内搜索三国演义这本小说如下:
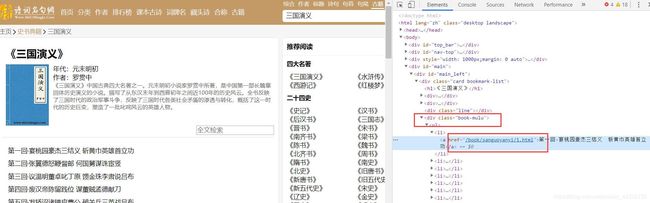
利用F12查看Elements,我们发现所有的章节都在class名为book-mulu的标签下面,每一章节都有一个a标签,地址不用猜就知道肯定是具体内容的页面
page_text = requests.get(url, headers=headers).text
soup = BeautifulSoup(page_text, 'lxml')
a_list = soup.select('.book-mulu a')
利用BeautifulSoup返回对象的select方法定位到这个div下面的所有a标签,返回的是一个a标签的列表。这个a标签里面包含了我们需要的具体内容的网址。
我们进入一个具体的页面,还是F12看看页面的元素,发现所有的内容都在class为chapter_content的div下面。
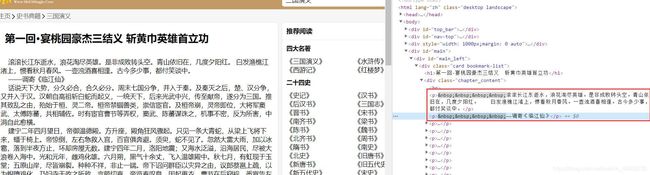
至此我们有了思路,先请求到小说首页,然后定位的div,得到这个下面所有的a标签。遍历每一个a标签的href地址,进入到详细内容的页面,再次定位到div,利用相关的属性得到这个div下面的内容。
(前后两个div的class名不同)
for a in a_list:
title=a.text
detail_url='http://shicimingju.com'+a['href']
detail_text=requests.get(detail_url,headers=headers).text
soup=BeautifulSoup(detail_text,'lxml')
content=soup.find('div',class_='chapter_content').text
fp.write(a.string+':'+content+'\n')
print(a.string+':\t'+' 爬取成功')
print('全部完成')
-
遍历之前获取到的a_list标签列表,a.text就是a标签里面的内容也就是每一回的标题。
-
a[‘href’]就是每个a标签的href属性所链接的地址,也就是详细内容的页面,但是链接时候你需要把前面的域名加上才是一个完整的URL地址。
-
那我们就利用requests发请求吧,返回的数据加载到BeautifulSoup里面,让它把我们的数据封装好,返回一个对象。
-
利用返回对象的find()方法,我们直接定位到class='chapter_content’的div。(class比较特殊代码写的时候需要加一个下划线)
-
然后利用其text属性,得到里面的内容,在写到文件里面。
·爬取过程如下
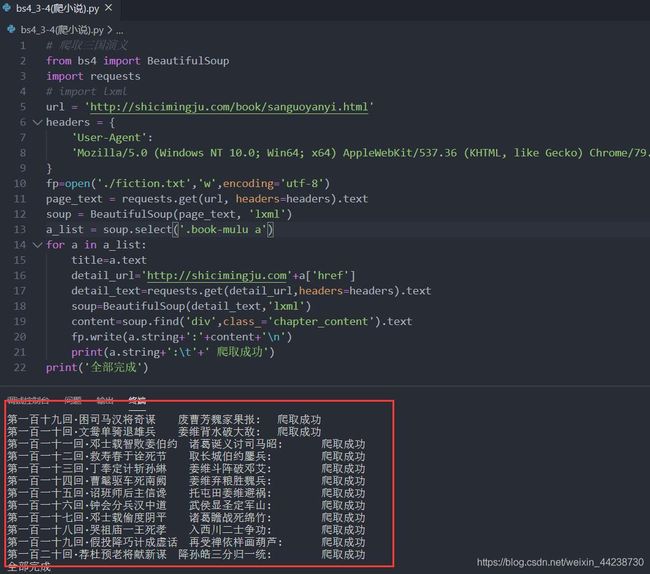
执行完上述代码之后就可以得到小说的内容了。我们打开fiction.txt查看内容如下。

如果上面的方法你学会了的话,你爬取一些基本的小说是完全没问题的。
完整代码如下,复制粘贴,直接运行即可。
from bs4 import BeautifulSoup
import requests
url = 'http://shicimingju.com/book/sanguoyanyi.html'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
fp=open('./fiction.txt','w',encoding='utf-8')
page_text = requests.get(url, headers=headers).text
soup = BeautifulSoup(page_text, 'lxml')
a_list = soup.select('.book-mulu a')
for a in a_list:
title=a.text
detail_url='http://shicimingju.com'+a['href']
detail_text=requests.get(detail_url,headers=headers).text
soup=BeautifulSoup(detail_text,'lxml')
content=soup.find('div',class_='chapter_content').text
fp.write(a.string+':'+content+'\n')
print(a.string+':\t'+' 爬取成功')
print('全部完成')
注意:最后送大家一套2020最新企业Pyhon项目实战视频教程,点击此处 进来获取 跟着练习下,希望大家一起进步哦!