赠V100算力卡 | 百度首次公开PaddlePaddle全景图,11项模块发布
4 月 23 日,首届 WAVE SUMMIT 2019 深度学习开发者峰会在北京举办,现场超千位开发者与来自百度、英特尔、清华大学等的科学家,就框架与深度学习展开了详细的讨论。在 WAVE 上,百度从建模、训练到部署,首次对外公布了 PaddlePaddle 全景图。
-
PaddlePaddle新特性完整PPT:https://pan.baidu.com/s/100iWwz-JDvX1dQ2XcJMJQg
-
提取码:9cxi
此外,百度还重磅推出算力支持计划,宣布为开发者提供总计 1 亿元免费算力。免费算力主要以两种模式提供,第一种是一人一卡模式,V100 的训练卡包括 16G 的显存,最高 2T 的存储空间。另外一种是远程集群模式,PaddlePaddle 提供高性能集群,供开发者免费使用。其中最吸引人的是是一人一卡,而我们正好获得了一张算力卡,它提供 Tesla V100 GPU 这种强大的计算力资源。
这张算力卡提供了一个邀请码,在 AI Studio 的单机模式中输入邀请码就能获得基础的 48 小时 V100 算力,而且该卡可以获得 3 个新的邀请码,对方每接受一次则增加 24 小时的 V100 算力。所以总的而言,这张算力卡可获得 120 小时的 Tesla V100 使用时间。

现在这张算力卡免费赠送机器之心读者啦~只要你在微信中留言最期待的 PaddlePaddle 更新或改进,那么截至 26 号中午 12 点,获得点赞量最多的留言将获得这张算力卡。
PaddlePaddle 全景图
正如百度深度学习技术平台部总监马艳军所言:「PaddlePaddle 其实从去年开始就有一个核心理念的变化,即将其定位为端到端的深度学习平台,而不仅仅是框架。」这也就意味着,PaddlePaddle 从底层框架、模型库,到基于它们构建的各种工具,再到完整的开发和服务平台,整个流程应该是端到端的,是一种『智能时代的操作系统』。」
会上,百度首次对外公布了 PaddlePaddle 的全景图,它从三个层面囊括了众多工具与组件。在这次 WAVE 中,百度发布了众多新工具与模块,下图黄色框的组件就是这次发布的重点。
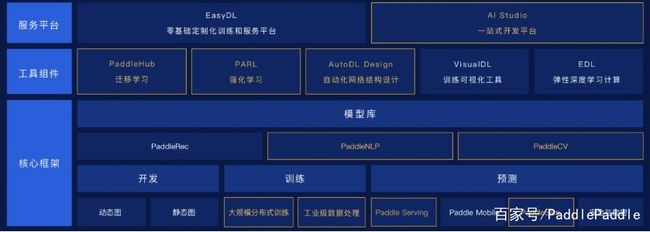
总体而言,PaddlePaddle 是集核心框架、工具组件和服务平台为一体的端到端开源深度学习平台。此次,PaddlePaddle 发布了 11 项新特性及服务,包含 PaddleNLP、视频识别工具集、Paddle Serving、PaddleSlim 等多种深度学习开发、训练、预测的便捷方法,也包含 PaddleHub 和 Auto Design 等面向具体领域的高效用具。
值得注意的是,百度还在 WAVE 现场宣布了「1 亿元」的 AI Studio 算力支持计划,通过提供 Tesla V100 免费使用时长,帮助使用者获得更强大的算力。最后,百度还公布了 PaddlePaddle 的中文名「飞桨」,它的寓意是「PaddlePaddle 是一个快速成长、性能优异的深度学习平台」。
新特性概览
PaddlePaddle 发布的新特性可以分为开发、训练、预测、工具和服务五大部分。其中开发主要是构建深度学习的过程,它需要更简洁与易于理解的编写方式。而训练与预测主要追求的是「快」,即在不影响性能的情况下,训练越快越好、预测越快越好。后面的工具则具体针对某些问题提出了一系列解决方案,从而简化开发过程。
1. 开发:
-
PaddleNLP
-
视频识别⼯工具集
PaddleNLP 是百度发布的完整 NLP 工具包,NLP 领域开发者可以方便地复现 baseline 模型,也可以进行二次开发,解决自己的问题。而百度发布的视频识别工具集能够为开发者提供处理视频理解、视频编辑、视频生成等一系列任务的解决方案。该工具集包含 7 个主流视频识别模型,下图中标黄的 3 个模型为百度独有的优秀模型。

PaddlePaddle 视频识别⼯工具集。
我们知道百度一直特别注重 NLP 方面的研究,这次 PaddleNLP 将很多 NLP 模型做了一套共享的骨架代码,这样跑不同模型用一套 API 和模式就行了。
除了发布已有的官方模型,如下图所示 PaddleNLP 还提供了针对一系列任务的处理工具,包括预处理和后处理,并且这块功能也是百度持续完善的点。

2. 训练:
-
分布式训练
-
⼯业级数据处理
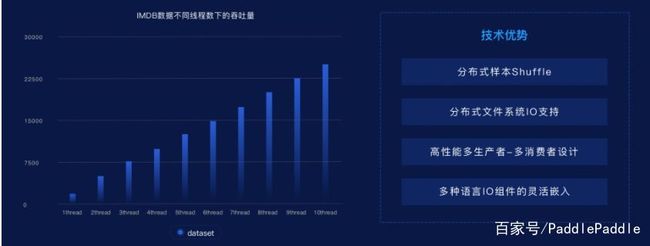
第一个是大规模分布式训练相关的能力升级,包括多机多卡的全面、全方位的支持;CPU 下的大规模稀疏参数服务器;以及各种容器下的高速大规模分布式训练。其次工业级的数据处理主要关注数据吞吐量,百度优化了分布式 IO,并增加远程文件系统流式读取能力。
如下所示为不同线程的数据吞吐能力,它们近似成线性增长,这种属性对于可扩展性非常重要。
3. 预测:
-
Paddle Serving
-
PaddleSlim
基于多硬件的支持,全新发布的 Paddle Serving 已支持服务器端的快速部署。Paddle Serving 目前在百度的很多产品线都在使用,它提供非常完备的在线服务能力。其次 PaddleSlim 是一个模型压缩工具库,它能够在精度损失较⼩的情况下高效进⾏模型的计算和体积压缩。
如下所示为 Paddle Serving 的整体架构图,它分为离线和在线两种基本实现。Server 端最上面部署了不同硬件的推理引擎。此外 Paddle Serving 还有基本的 Built-in 预处理执行器,是一套完整的模型部署框架。

4. 工具:
-
AutoDL Design
-
PARL
-
PaddleHub
正式发布的 AutoDL Design 利用强化学习实现神经网络架构搜索,搜索的结果在很多特定场景下都优于人类设计的网络,百度也开源了 6 个自动搜索到的模型。PARL 是一个强化学习的工具,这次升级在算法的覆盖、高性能通讯以及并行训练方面做了大量的支持和扩展。
最后发布的工具 PaddleHub 是预训练的一站式管理平台,它提供了非常好的封装,方便用户基于大模型做迁移学习。一般只需 10 行代码左右,我们就可以实现一次迁移学习,将其应用到我们自己的任务场景。

AutoDL Design 设计的网络在 CIFAR-10 上达到当前最优的 98.01% 准确率。
最后的服务则主要通过 AI Studio 支持免费算力,我们可以获得单人单卡(Tesla V100)的强大计算力,也可以获得远程集群模式免费算力。
以上仅概览了 PaddlePaddle 的新特性,而其中很多特性值得详细介绍。下面我们就从开发者的角度,了解 PaddleSlim、PaddleHub 和动态计算图等新特性。
一个优雅的模型压缩模块 PaddleSlim
PaddleSlim 是 PaddlePaddle 框架的一个子模块,它首次在 PaddlePaddle 1.4 版本中发布。该模块是非常优雅的模型压缩工具包,不仅保证了性能,同时还兼顾了易用性,只需几行代码就能 work。
PaddleSlim 中实现了目前主流的网络剪枝、量化、蒸馏三种压缩策略,主要用于压缩图像领域模型。在后续版本中,百度会添加更多的压缩策略,以及完善对 NLP 领域模型的支持。
PaddleSlim 示例和文档:https://github.com/PaddlePaddle/models/tree/develop/PaddleSlim
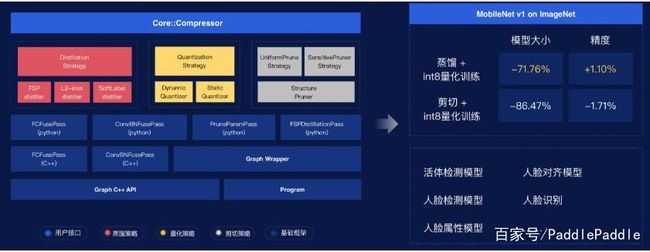
如上所示,这三种最常见的压缩方法都建立在复杂的基础架构上,从而提供更好的压缩效果。如右图所示,即使是非常精简的 MobileNet,也能得到很可观的压缩效果。尽管底层比较复杂,但它在实际使用起来却非常简单,我们只需要几行代码就能调用自动化的模型压缩能力。
如下所示为剪枝示例,具体过程可查看前面的 PaddleSlim 文档地址。我们可以直接调用压缩脚本,并给出对应的压缩配置,PaddlePaddle 就能自动在训练过程中对模型完成压缩。
PaddleSlim 的使用很简单,不论是我们想降低运算量(FLOPS),还是想降低模型大小(权重所占空间),它都能快速办到。
新颖的 PaddleHub
现在介绍一个新颖的工具 PaddleHub,它是基于 PaddlePaddle 开发的预训练模型管理工具,可以借助预训练模型更便捷地开展迁移学习工作。
PaddleHub 项目地址:https://github.com/PaddlePaddle/PaddleHub
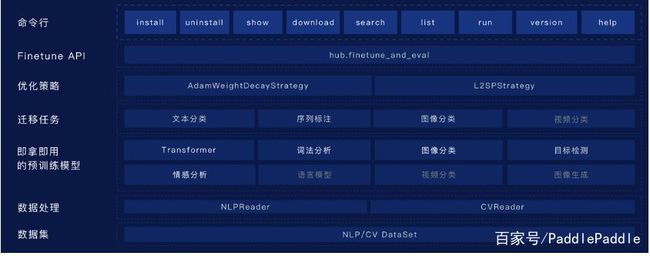
以下展示了 PaddleHub 的完整架构图,百度封装了一系列 NLP 和 CV 的数据集,还提供了 Reader 以快速便捷地处理数据。除了数据集,更多的就是预训练模型了,包括拿来就用的 Transformer 和目标检测等模型。此外,还能针对不同的任务实现迁移学习,包括文本分类、序列标注、图像分类等。
在用 pip 安装 paddlehub 后,我们可以快速体验 PaddleHub 无需代码、一键预测的命令行功能:
通过命令行,我们可以快速使用预训练模型进行预测。同时借助 PaddleHub Finetune API,使用少量代码就能完成迁移学习。例如我们可以使用 PaddleHub Finetune API 以及图像分类预训练模型完成分类任务,当然,我们也可以只调整几个超参数。
令人期待的动态计算图
除了会上介绍的新特性,我们在最新版的 Paddle Fluid 1.4 文档中还发现一种全新的动态计算图模块 DyGraph。目前 DyGraph 还处于预览阶段,但它标志着 PaddlePaddle 也开始同时兼顾静态计算图与动态计算图。
DyGraph 文档地址:http://paddlepaddle.org/documentation/docs/zh/1.4/user_guides/howto/dygraph/DyGraph.html
我们一般认为静态计算图在高效训练和部署上有非常大的优势,而动态计算图在开发效率与易用性上也无可替代。只有将动态计算图与静态计算图之间的兼容性做好,才能兼顾训练速度与简单易用两大特点。
总的来说,PaddlePaddle 的 DyGraph 模式是一种动态的图执行机制,可以立即执行结果,无需构建整个图。同时,和以往静态的执行计算图不同,DyGraph 模式下您的所有操作可以立即获得执行结果,而不必等待所构建的计算图全部执行完成,这样可以让您更加直观地构建 PaddlePaddle 下的深度学习任务,以及进行模型的调试,同时还减少了大量用于构建静态计算图的代码,使得您编写、调试网络的过程变得更加便捷。
下面我们可以简单地体会一下 DyGraph 的魅力,我们可以在 fluid.dygraph.guard() 上下文环境中使用 DyGraph 的模式运行网络,DyGraph 将改变以往 PaddlePaddle 的执行方式,现在这些代码可以立即执行,并且将计算结果返回给 Python。如下所示,在最后打印损失函数的梯度时,可以直接获得结果:
目前 DyGraph 还是预览版,PaddlePaddle 计划在今年 7 月份完善动态图的基本功能、新增流水线并行的能力,与此同时还要优化显存占用与静态计算图的训练速度。PaddlePaddle 计划在今年 11 月完成动态图实现与静态图的灵活转换,并全面优化动态图的训练速度。

所以对于 PaddlePaddle 的进一步发展,我们还是非常期待的。