Python 深度学习(第三章神经网络入门)
Python 深度学习-神经网络入门
第一次写博客,也是刚刚接触神经网络的小白,所以想将自己的学习到的一点点知识分享给大家,同时也可以加深对神经网络的理解
详细信息
语言:python
框架:Keras
IDE:jupyter notebook
处理问题:电影评论分类(二分类)、新闻主题分类(多分类)、预测房价(回归问题)
一、 电影评论分类(二分类):
本节使用IMDB数据集,它包含来自互联网电影数据库(IMDB)的50 000 条严重两极分化的评论。数据集被分为用于训练的25 000 条评论与用于测试的25 000 条评论,训练集和测试集都包含50% 的正面评论和50% 的负面评论。
步骤:
1. 加载IMDB数据集
import keras #导入库
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000) #num_words 表示仅保留训练数据集中常出现的10000个词
2. 将评论编码,并将某条评论迅速解码为英文单词
train_data[0]
train_labels[0]
max([max(sequence) for sequence in train_data]) #测试最大单词索引为9999
#word_index是一个将单词映射为整数索引的字典
word_index = imdb.get_word_index()
# 键值颠倒,将整数索引映射为单词
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
#将评论解码
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
#测试将某条评论迅速转化为英文单词
decoded_review
3. 准备数据集
不能将整数序列直接输入神经网络,需要将列表转化为张量
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
# 创建一个形状为 (len(sequences), dimension)的零矩阵
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
# 将训练数据向量化
x_train = vectorize_sequences(train_data)
# 将测试数据向量化
x_test = vectorize_sequences(test_data)
#输出转化后的样本,0 1序列
x_train[0]
#标签向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
4. 构建网络
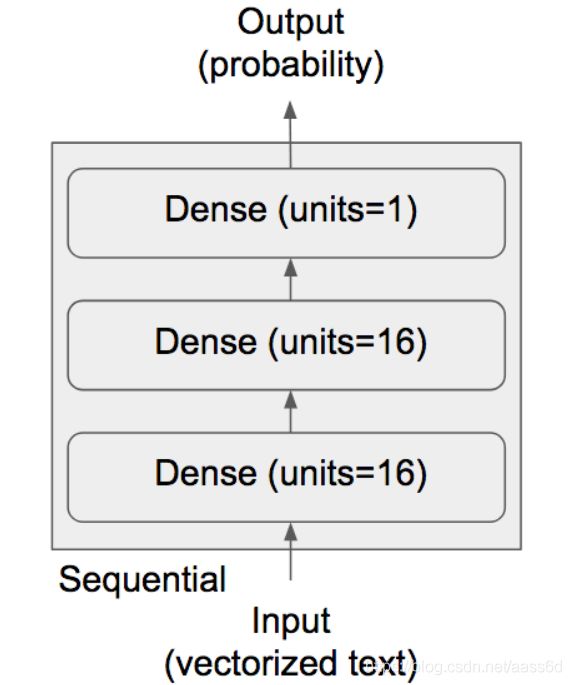
模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
编译模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
配置优化器
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
使用自定义的损失和指标
from keras import losses
from keras import metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
注意:
Optimizer(优化器):常用rmsprop
Loss(损失函数):视情况而定,对于二分类问题的 sigmoid标量输出,可用binary_crossentropy损失函数。对于多分类问题,可用categorical_crossentropy(分类交叉熵)
Metriucs: 测试参数 ,可选择精度
5.验证
留出验证集:
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20, #20次迭代
batch_size=512,
validation_data=(x_val, y_val))
history_dict = history.history
history_dict.keys()
绘制训练损失和验证损失:
import matplotlib.pyplot as plt
acc = history.history['binary_accuracy']
val_acc = history.history['val_binary_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
结果图:
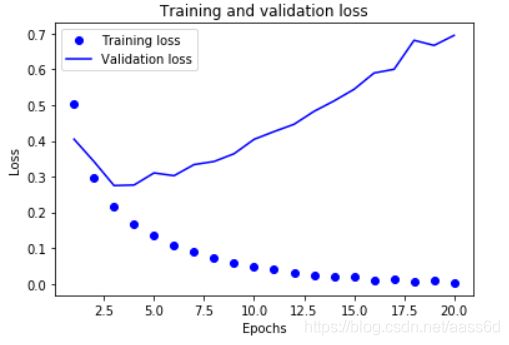
绘制训练精度和验证精度:
plt.clf() # clear figure
acc_values = history_dict['binary_accuracy']
val_acc_values = history_dict['val_binary_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
结果图:
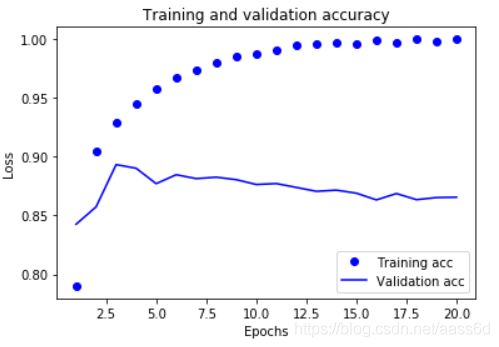
二、新闻主题分类(多分类):
处理多分类和二分类的方式类似,主要区别在于神经网络的全连接层,所以没有详细的介绍,程序及结果如下:
1.加载路透社数据集:
import keras
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
#分别输出测试验证样本的数目
len(train_data)
len(test_data)
train_data[10]
将索引解码为新闻文本(共有46个类别,则解码后为0-45 这个数字):
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# Note that our indices were offset by 3
# because 0, 1 and 2 are reserved indices for "padding", "start of sequence", and "unknown".
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
#输出测试文本的英文内容
decoded_newswire
#随机检测某一样本所属于的类别
train_labels[10]
2.编码数据:
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
#将索引对应位置编码为1 其他位置置零
results[i, sequence] = 1.
return results
#训练和测试数据全部向量化
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
向量化:
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
#将训练和测试lable进行onehot编码
one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels)
3.构建网络:
模型定义:
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
编译模型:
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
4.验证
留出验证集:
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
训练模型:
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
绘制训练损失和验证损失:
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
绘制训练精度和验证精度:
plt.clf() # clear figure
acc = history.history['acc']
val_acc = history.history['val_binary_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
三、预测房价(回归问题):
1.加载波士顿房价:
import keras
from keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
#验证集和测试集大小
train_data.shape
test_data.shape
train_targets
2.准备数据集
数据标准化(由于 回归问题 各个特征的取值范围很可能不同 所以需要归一化处理)
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
3.构建网络
模型定义:
from keras import models
from keras import layers
def build_model():
#因为需要将同一个模型多次实例化,所以用同一个函数来构建模型
model = models.Sequential()
model.add(layers.Dense(64, activation='relu',
input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
K折验证:
import numpy as np
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
print('processing fold #', i)
# 准备验证数据:第K个分区的数据
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
# 准备训练数据,其他所有分区的数据
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
# 构建Keras模型
model = build_model()
# 训练模型 (in silent mode, verbose=0)
model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs, batch_size=1, verbose=0)
# 在验证数据上评估模型
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
保存每折的验证结果:
from keras import backend as K
K.clear_session()
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
# Prepare the validation data: data from partition # k
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
# Prepare the training data: data from all other partitions
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
# Build the Keras model (already compiled)
model = build_model()
# Train the model (in silent mode, verbose=0)
history = model.fit(partial_train_data, partial_train_targets,
validation_data=(val_data, val_targets),
epochs=num_epochs, batch_size=1, verbose=0)
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)
计算所有轮次中的K折验证平均值
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
绘制验证分数:
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
绘制验证分数(删除前十个点)
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smooth_mae_history) + 1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
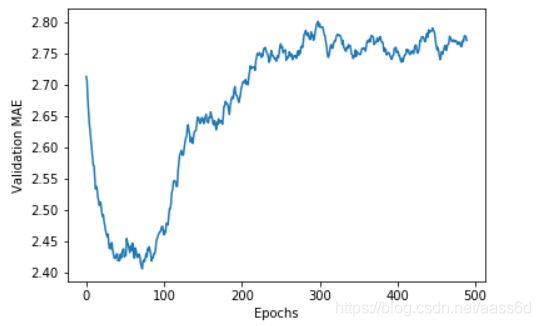
训练最终模型:
model = build_model()
# Train it on the entirety of the data.
model.fit(train_data, train_targets,
epochs=80, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
最终结果如下:
test_mae_score
2.5532484335057877
代码参考了python深度学习一书中的源代码并加有部分注释。