目标侦测(YOLO-V3)
yolo:you only look once.(只看一次,速度快)
数据处理
筛选建议框(根据目标筛选形状和大小)
在数据集中有一堆框,用 K-Means 聚类算法找到 9 个框,代表整个数据集。
IMG_HEIGHT = 416
IMG_WIDTH = 416
CLASS_NUM = 10
ANCHORS_GROUP = {
13: [[51, 22], [52, 22], [53, 22]],
26: [[54, 22], [55, 22], [56, 22]],
52: [[57, 22], [58, 22], [59, 22]]
}
ANCHORS_GROUP_AREA = {
13: [x * y for x, y in ANCHORS_GROUP[13]],
26: [x * y for x, y in ANCHORS_GROUP[26]],
52: [x * y for x, y in ANCHORS_GROUP[52]],
}
设计标签
(cls,cx,cy,w,h)→(cls,cx_offset,cy_offset,w_p,h_p)
中心点:与缩放比例有关。
cx_offset = cx / 缩放比例 = 前边有几个格子.cx 相对于当前格子的偏移量
cy_offset = cy / 缩放比例 = 前边有几个格子.cy 相对于当前格子的偏移量
宽高:与建议框有关。
w_p = log(实际w / 建议w)
h_p = log(实际h / 建议h)
from torch.utils.data import Dataset
from torchvision import transforms
from PIL import Image
import numpy as np
import os
import cfg
def one_hot(cls_num, v):
result = np.zeros(cls_num)
result[v] = 1.
return result
class MyDataset(Dataset):
def __init__(self, path, label_path):
self.path = path
self.transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
with open(label_path) as label:
self.data = label.readlines()
def __len__(self):
return len(self.data)
def __getitem__(self, index):
# key:13, 26, 52
# value:[13, 13, 3, 15] [26, 26, 3, 15] [52, 52, 3, 15]
labels = {}
# img1 cls1 cx1 cy1 w1 h1 img2 cls2 cx2 cy2 w2 h2
infos = self.data[index].strip().split(" ")
img = Image.open(os.path.join(self.path, infos[0]))
img = self.transform(img)
# cls1 cx1 cy1 w1 h1 cls2 cx2 cy2 w2 h2
boxes = np.array([float(box) for box in infos[1:]])
# [cls cx cy w h]
boxes = np.split(boxes, len(boxes) // 5)
# 3(建议框尺寸[13, 26, 52])
# feature_size:13, 26, 52
# anchors:每个尺寸的 3 个建议框
for feature_size, anchors in cfg.ANCHORS_GROUP.items():
labels[feature_size] = np.zeros((feature_size, feature_size, 3, 5 + cfg.CLASS_NUM))
# 目标数
for box in boxes:
cls, cx, cy, w, h = box
# cx_index:整数部分,第几个格子
# cx_offset:小数部分,中心点的偏移量
# 缩放比例(每个格子的尺寸)= IMG_WIDTH/feature → cx/缩放比例 = cx/(IMG_WIDTH/feature) = cx·feature/IMG_WIDTH
cx_offset, cx_index = np.modf(cx * feature_size / cfg.IMG_WIDTH)
cy_offset, cy_index = np.modf(cy * feature_size / cfg.IMG_HEIGHT)
# 3(每种尺寸有 3 个建议框)
for i, anchor in enumerate(anchors):
anchor_area = cfg.ANCHORS_GROUP_AREA[feature_size][i]
# 标签相对于建议框的偏移量
p_w, p_h = w / anchor[0], h / anchor[1]
p_area = p_w * p_h
# 置信度
iou = min(anchor_area, p_area) / max(anchor_area, p_area)
# 给 key 为 feature_size 的标签赋值
# 索引:w, h, i
# 值:c, cx_offset, cy_offset, p_w, p_h, cls
labels[feature_size][int(cy_index), int(cx_index), i] = np.array(
[iou, cx_offset, cy_offset, np.log(p_w), np.log(p_h), *one_hot(cfg.CLASS_NUM, int(cls))])
return labels[13], labels[26], labels[52], img
计算偏移量
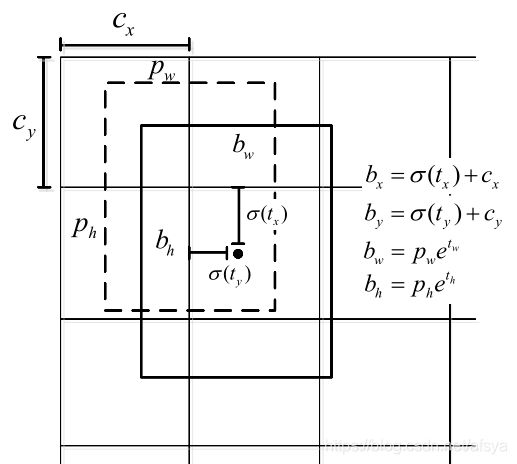
tx、ty:网络输出的中心点偏移量。(中心点相对于当前格子的偏移量)
bx、by:实际的中心点坐标。
cx、cy:一个格子的宽高。
bx = cx * 前边有几个格子 + tx
by = cy * 前边有几个格子 + ty
pw、ph:建议框宽高。
bw、bh:实际框宽高。
w=log(bw/pw) → exp(w)=bw/pw → bw=pw·exp(w)
h=log(bh/ph) → exp(h)=bh/ph → bh=pw·exp(h)
网络(darknet53)

import torch
from torch import nn
from torch.nn import functional as F
# 卷积层
class conv_layer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=False):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, bias=bias),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1)
)
def forward(self, x):
return self.conv(x)
# 残差块
class residual(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.conv = nn.Sequential(
conv_layer(in_channels, in_channels // 2, 1, 1, 0),
conv_layer(in_channels // 2, in_channels, 3, 1, 1)
)
def forward(self, x):
return x + self.conv(x)
# 卷积块
class conv_set(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
conv_layer(in_channels, out_channels, 1, 1, 0),
conv_layer(out_channels, in_channels, 3, 1, 1),
conv_layer(in_channels, out_channels, 1, 1, 0),
conv_layer(out_channels, in_channels, 3, 1, 1),
conv_layer(in_channels, out_channels, 1, 1, 0)
)
def forward(self, x):
return self.conv(x)
# 上采样(线性插值)
class up_sampling(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return F.interpolate(x, scale_factor=2, mode='nearest')
class Net(nn.Module):
def __init__(self):
super().__init__()
# 52 × 52
self.net_52 = nn.Sequential(
conv_layer(3, 32, 3, 1, 1),
conv_layer(32, 64, 3, 2, 1),
residual(64),
conv_layer(64, 128, 3, 2, 1),
residual(128),
residual(128),
conv_layer(128, 256, 3, 2, 1),
residual(256),
residual(256),
residual(256),
residual(256),
residual(256),
residual(256),
residual(256),
residual(256)
)
self.up_52 = nn.Sequential(
conv_layer(256, 128, 1, 1, 0),
up_sampling()
)
self.conv_set_52 = nn.Sequential(
conv_set(256 + 128, 128)
)
self.detect_52 = nn.Sequential(
conv_layer(128, 256, 3, 1, 1),
conv_layer(256, 45, 1, 1, 0)
)
# 26 × 26
self.net_26 = nn.Sequential(
conv_layer(256, 512, 3, 2, 1),
residual(512),
residual(512),
residual(512),
residual(512),
residual(512),
residual(512),
residual(512),
residual(512)
)
self.up_26 = nn.Sequential(
conv_layer(512, 256, 1, 1, 0),
up_sampling()
)
self.conv_set_26 = nn.Sequential(
conv_set(512 + 256, 256)
)
self.detect_26 = nn.Sequential(
conv_layer(256, 512, 3, 1, 1),
conv_layer(512, 45, 1, 1, 0)
)
# 13 × 13
self.net_13 = nn.Sequential(
conv_layer(512, 1024, 3, 2, 1),
residual(1024),
residual(1024),
residual(1024),
residual(1024)
)
self.conv_set_13 = nn.Sequential(
conv_set(1024, 512)
)
self.detect_13 = nn.Sequential(
conv_layer(512, 1024, 3, 1, 1),
conv_layer(1024, 45, 1, 1, 0)
)
def forward(self, x):
out52 = self.net_52(x)
out26 = self.net_26(out52)
out13 = self.net_13(out26)
# 13 × 13
conv_set13 = self.conv_set_13(out13)
result13 = self.detect_13(conv_set13)
# 26 × 26
up26 = self.up_26(conv_set13)
conv_set26 = self.conv_set_26(torch.cat((up26, out26), dim=1))
result26 = self.detect_26(conv_set26)
# 52 × 52
up52 = self.up_52(conv_set26)
conv_set52 = self.conv_set_52(torch.cat((up52, out52), dim=1))
result52 = self.detect_52(conv_set52)
return result13, result26, result52
训练
import torch
from torch.utils.data import DataLoader
import os
from dataset import MyDataset
from darknet53 import Darknet53
net_path = r"modules/net.pth"
# 自定义损失
# output:[n,c,h,w]
# target:[n,h,w,3,15]
# alpha:权重,没有目标的格子多,有目标的损失需要加强计算
def loss_fn(out, label, alpha):
# [n,c,h,w] → [n,h,w,c]
out = out.permute(0, 2, 3, 1)
# [n,h,w,c] → [n,h,w,3,iou+cx+cy+w+h+cls]
out = out.reshape(out.size(0), out.size(1), out.size(2), 3, -1)
# 根据置信度区分正样本和负样本
mask_obj = label[..., 0] > 0
mask_noobj = label[..., 0] == 0
# 均方差
loss_obj = torch.mean((label[mask_obj] - out[mask_obj]) ** 2)
# 负样本只算置信度
loss_noobj = torch.mean((label[mask_noobj][0] - out[mask_noobj][0]) ** 2)
loss = alpha * loss_obj + (1 - alpha) * loss_noobj
return loss
if __name__ == '__main__':
dataset = MyDataset(r"data/img", r"data/person_label.txt")
train_loader = torch.utils.data.DataLoader(dataset, batch_size=2, shuffle=True)
net = Darknet53()
if os.path.isfile(net_path):
net.load_state_dict(torch.load(net_path))
opt = torch.optim.Adam(net.parameters())
for target_13, target_26, target_52, img_data in train_loader:
output_13, output_26, output_52 = net(img_data)
loss_13 = loss_fn(output_13, target_13, 0.9)
loss_26 = loss_fn(output_26, target_26, 0.9)
loss_52 = loss_fn(output_52, target_52, 0.9)
loss = loss_13 + loss_26 + loss_52
opt.zero_grad()
loss.backward()
opt.step()
print("loss:{:.5}".format(loss.item()))