Python Numpy计算各类距离的方法
用Python Numpy计算各类距离真的是简洁迅速的方法。
下面对我在使用过程中能解答我疑惑的几篇博文加以总结
一.首先要明白np.linalg.norm到底执行了什么样的计算
np.linalg.norm
linalg=linear+algebra
norm则表示范数,首先需要注意的是范数是对向量(或者矩阵)的度量,是一个标量(scalar):
首先help(np.linalg.norm)查看其文档:
norm(x, ord=None, axis=None, keepdims=False)
ord 为设置具体范数值, axis 向量的计算方向, keepdims 设置是否保持维度不变
范数理论的一个推论: L1>=L2>=L∞
import numpy as np
from numpy import linalg as LA
a = np.array([-3, -5, -7, 2, 6, 4, 0, 2, 8])
b = a.reshape((3, 3))
print(b)
'''
[[-3 -5 -7]
[ 2 6 4]
[ 0 2 8]]
'''
print( LA.norm(b))
#14.38749456993816
print(np.linalg.norm(b, ord=2))
#13.686302989309274
print(np.linalg.norm(b, ord=1))
#19.0
print(np.linalg.norm(b, ord=np.inf))
#15.0
保持维度:
a=np.array([0,3,4,2,6,4]);
b = a.reshape((2, 3))
print(b)
print(np.linalg.norm(b,axis=1,keepdims=True))
#[[5. ]
#[7.48331477]]
求取向量二范数,并求取单位向量(行向量计算)

import numpy as np
x=np.array([[0, 3, 4], [2, 6, 4]])
y=np.linalg.norm(x, axis=1, keepdims=True)
z=x/y
x 为需要求解的向量, y为x中行向量的二范数, z为x的行方向的单位向量。
其中二范数的一个等价方法:
import numpy as np
x=np.array([[0, 3, 4], [2, 6, 4]])
y2=np.sum(x**2, axis=1, keepdims=True)**0.5
z2=x/y2

二.接着最重要的来了
Python Numpy计算各类距离的方法
详细:
1.闵可夫斯基距离(Minkowski Distance)
2.欧氏距离(Euclidean Distance)
3.曼哈顿距离(Manhattan Distance)
4.切比雪夫距离(Chebyshev Distance)
5.夹角余弦(Cosine)
6.汉明距离(Hamming distance)
7.杰卡德相似系数(Jaccard similarity coefficient)
8.贝叶斯公式
1.闵氏距离的定义:
两个n维变量A(x11,x12,…,x1n)与 B(x21,x22,…,x2n)间的闵可夫斯基距离定义为:

其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
np.linalg.norm #是适合使用这个公式2.欧氏距离(Euclidean Distance)
欧氏距离(L2范数)是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式(如图1.9)。

python实现欧式距离公式的:
vector1 = np.array([1,2,3])
vector2 = np.array([4,5,6])
op1=np.sqrt(np.sum(np.square(vector1-vector2)))
op2=np.linalg.norm(vector1-vector2)
print(op1)
print(op2)
#输出:
#5.19615242271
#5.196152422713.曼哈顿距离(Manhattan Distance)
从名字就可以猜出这种距离的计算方法了。想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个“曼哈顿距离”(L1范数)。而这也是曼哈顿距离名称的来源,曼哈顿距离也称为城市街区距离(City Block distance)(如图1.10)。

python实现曼哈顿距离:
vector1 = np.array([1,2,3])
vector2 = np.array([4,5,6])
op3=np.sum(np.abs(vector1-vector2))
op4=np.linalg.norm(vector1-vector2,ord=1)
#输出
#9
#9.04.切比雪夫距离(Chebyshev Distance)
国际象棋玩过么?国王走一步能够移动到相邻的8个方格中的任意一个(如图1.11)。那么国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?自己走走试试。你会发现最少步数总是max(| x2-x1| , |y2-y1| ) 步。有一种类似的一种距离度量方法叫切比雪夫距离(L∞范数)。

Python实现切比雪夫距离:
vector1 = np.array([1,2,3])
vector2 = np.array([4,7,5])
op5=np.abs(vector1-vector2).max()
op6=np.linalg.norm(vector1-vector2,ord=np.inf)
print(op5)
print(op6)
#输出:
#5
#5.05. 夹角余弦(Cosine)
几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异(如图1.12)。

(1)在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:

(2) 两个n维样本点A (x11,x12,…,x1n)与 B(x21,x22,…,x2n)的夹角余弦
类似的,对于两个n维样本点A(x11,x12,…,x1n)与 B(x21,x22,…,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度。

夹角余弦取值范围为[-1,1]。夹角余弦越大表示两个向量的夹角越小,夹角余弦越小表示两向量的夹角越大。当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1。
python实现夹角余弦
vector1 = np.array([1,2,3])
vector2 = np.array([4,7,5])
op7=np.dot(vector1,vector2)/(np.linalg.norm(vector1)*(np.linalg.norm(vector2)))
print(op7)
#输出
#0.9296696802016. 汉明距离(Hamming distance)
(1)汉明距离的定义
两个等长字符串s1与s2之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。例如字符串“1111”与“1001”之间的汉明距离为2。
应用:信息编码(为了增强容错性,应使得编码间的最小汉明距离尽可能大)。
(2) python实现汉明距离:
v1=np.array([1,1,0,1,0,1,0,0,1])
v2=np.array([0,1,1,0,0,0,1,1,1])
smstr=np.nonzero(v1-v2)
print(smstr) # 不为0 的元素的下标
sm= np.shape(smstr[0])[0]
print( sm )
#输出
#(array([0, 2, 3, 5, 6, 7]),)
#67. 杰卡德相似系数(Jaccard similarity coefficient)
(1) 杰卡德相似系数
两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。

(2) 杰卡德距离
与杰卡德相似系数相反的概念是杰卡德距离(Jaccard distance)。杰卡德距离可用如下公式表示:

杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
(3) 杰卡德相似系数与杰卡德距离的应用
可将杰卡德相似系数用在衡量样本的相似度上。
样本A与样本B是两个n维向量,而且所有维度的取值都是0或1。例如:A(0111)和B(1011)。我们将样本看成是一个集合,1表示集合包含该元素,0表示集合不包含该元素。
P:样本A与B都是1的维度的个数
q:样本A是1,样本B是0的维度的个数
r:样本A是0,样本B是1的维度的个数
s:样本A与B都是0的维度的个数
那么样本A与B的杰卡德相似系数可以表示为:
这里p+q+r可理解为A与B的并集的元素个数,而p是A与B的交集的元素个数。
而样本A与B的杰卡德距离表示为:

Python实现杰卡德距离:
import scipy.spatial.distance as dist
v1=np.array([1,1,0,1,0,1,0,0,1])
v2=np.array([0,1,1,0,0,0,1,1,1])
matv=np.array([v1,v2])
print(matv)
ds=dist.pdist(matv,'jaccard')
print(ds)
#输出
#[[1 1 0 1 0 1 0 0 1] [0 1 1 0 0 0 1 1 1]]
# [ 0.75]8. 经典贝叶斯公式
原: P(AB)=P(A | B)·P(B)=P(B | A)·P(A)
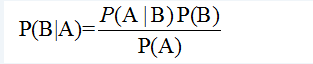
本例,我们不去研究黄色的苹果与黄色的梨有什么差别。而承认其统计规律:苹果是红色的概率是0.8,苹果是黄色的概率就是1-0.8=0.2,而梨是黄色的概率是0.9,将其作为先验概率。有了这个先验概率,就可以利用抽样,即任取一个水果,前提是抽样对总体的概率分布没有影响,通过它的某个特征来划分其所属的类别。黄色是苹果和梨共有的特征,因此,既有可能是苹果也有可能是梨,概率计算的意义在于得到这个水果更有可能的那一种。
条件: 10个苹果10个梨子
用数学的语言来表达,就是已知:
# P(苹果)=10/(10+10),P(梨)=10/(10+10),P(黄色|苹果)=20%,P(黄色|梨)=90%,P(黄色)= 20% * 0.5 + 90% * 0.5 = 55%求P(梨|黄色):
# = P(黄色|梨)P(梨)/P(黄色)
# = 81.8%
以上就是本文的全部内容,希望对大家的学习有所帮助。
原文:https://blog.csdn.net/flyfish1986/article/details/79596389
原文:https://www.cnblogs.com/devilmaycry812839668/p/9352814.html
原文:https://m.jb51.net/article/164673.htm