机器学习笔记18-相似度/距离计算方法总结
1.曼哈顿距离和欧式距离

图中红线代表曼哈顿距离,绿色代表欧式距离,也就是直线距离,而蓝色和黄色代表等价的曼哈顿距离。

2.杰卡德相似系数(Jaccard)
两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。杰卡德相似系数是衡量两个集合的相似度一种指标。如CV领域中的IOU。
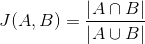
3.余弦相似度及扩展
相似度度量(Similarity),即计算个体间的相似程度,相似度度量的值越小,说明个体间相似度越小,相似度的值越大说明个体差异越大。对于多个不同的文本或者短文本对话消息要来计算他们之间的相似度如何,一个好的做法就是将这些文本中词语,映射到向量空间,形成文本中文字和向量数据的映射关系,通过计算几个或者多个不同的向量的差异的大小,来计算文本的相似度。下面介绍一个详细成熟的向量空间余弦相似度方法计算相似度。
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
上图两个向量a,b的夹角很小可以说a向量和b向量有很高的的相似性,极端情况下,a和b向量完全重合。如下图:

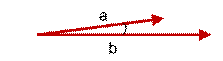
如上图二:可以认为a和b向量是相等的,也即a,b向量代表的文本是完全相似的,或者说是相等的。如果a和b向量夹角较大,或者反方向。如下图
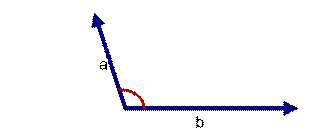
如上图三: 两个向量a,b的夹角很大可以说a向量和b向量有很低的的相似性,或者说a和b向量代表的文本基本不相似。那么是否可以用两个向量的夹角大小的函数值来计算个体的相似度呢?
向量空间余弦相似度理论就是基于上述来计算个体相似度的一种方法。下面做详细的推理过程分析。
在任意三角形中,余弦定理的公式是

在向量表示的三角形中,假设a向量是(x1, y1),b向量是(x2, y2),那么可以将余弦定理改写成下面的形式:
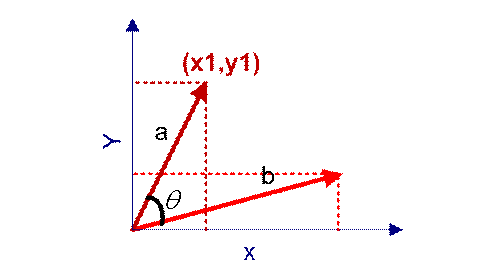
向量a和向量b的夹角 的余弦计算如下

扩展,如果向量a和b不是二维而是n维,上述余弦的计算法仍然正确。假定a和b是两个n维向量,a是 ,b是 ,则a与b的夹角的余弦等于:

【下面举一个例子,来说明余弦计算文本相似度】
举一个例子来说明,用上述理论计算文本的相似性。为了简单起见,先从句子着手。
句子A:这只皮靴号码大了。那只号码合适
句子B:这只皮靴号码不小,那只更合适
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,列出所有的词。
这只,皮靴,号码,大了。那只,合适,不,小,很
第三步,计算词频。
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第四步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
到这里,问题就变成了如何计算这两个向量的相似程度。我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合,这是表示两个向量代表的文本完全相等;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
使用上面的公式(4)

计算两个句子向量
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)的向量余弦值来确定两个句子的相似度。
计算过程如下:

计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
由此,我们就得到了文本相似度计算的处理流程是:
- 找出两篇文章的关键词;
- 每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频
- 生成两篇文章各自的词频向量;
- 计算两个向量的余弦相似度,值越大就表示越相似。
参考:http://blog.csdn.net/u012160689/article/details/15341303
4.Pearson相似系数
关于协方差的理解:https://blog.csdn.net/beechina/article/details/51074750
Pearson相似系数值域:https://www.jianshu.com/p/a88697d759c6
如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
(1)、当相关系数为0时,X和Y两变量无关系。
(2)、当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
(3)、当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
相关系数的绝对值越大,相关性越强,相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
首先放上公式:

公式定义为: 两个连续变量(X,Y)的pearson相关性系数P(x,y)等于它们之间的协方差cov(X,Y)除以它们各自标准差的乘积(σX,σY)。系数的取值总是在-1.0到1.0之间,接近0的变量被成为无相关性,接近1或者-1被称为具有强相关性。
皮尔逊相关系数其实就是减去平均值(中心化)后做余弦相似性
所以, 从本质上, 皮尔逊相关系数是余弦相似度在维度值缺失情况下的一种改进。
实际我们做数据挖掘的过程中, 向量在某个维度的值常常是缺失的, 比如v2=(3, -1, null), v2数据采集或者保存中缺少一个维度的信息, 只有两个维度. 那么, 我们一个很朴素的想法就是, 我们在这个地方填充一个值, 不就满足了"两个向量必须所有维度上都有数值"的严格要求了吗? 填充值的时候, 我们一般这个向量已有数据的平均值, 所以v2填充后变成v2=(3, -1, 2), 接下来我们就可以计算cos
5.相对熵(K-L散度)

![]()
参考:https://www.cnblogs.com/kyrieng/p/8694705.html
https://blog.csdn.net/u013829973/article/details/80936272