python爬虫实战(1)抓取网页图片自动保存
随便抓取个桌面吧的图片。网址如下:http://tieba.baidu.com/p/2970106602
找到源代码中的图片网址,由正则表达式可构建出规则:rule=r‘src="(.+?\.jpg)" pic_ext’
代码如下,简单明了
import re
import urllib.request
url='http://tieba.baidu.com/p/2970106602'
data=urllib.request.urlopen(url).read().decode()#读取并解码,默认应该是utf-8?
rule=r'src="(.+?\.jpg)" pic_ext'
compiled_rule=re.compile(rule)
list1=re.findall(compiled_rule,data)
x=1
path='d://python//grab//photo'#构建本地保存路径
for element in list1:
pathnew=path+'//'+str(x)+'.jpg'
urllib.request.urlretrieve(element,pathnew)
x=x+1
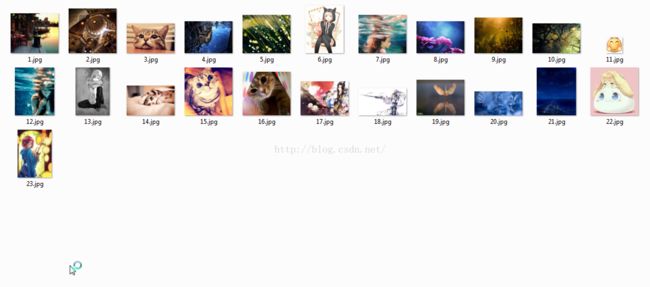
最后效果: