基础算法—几种线性时间排序
本次我们讨论3种线性时间复杂度的排序算法:计数排序、基数排序和桶排序。
一、计数排序
计数排序假设n个输入元素中的每一个都是在0到k区间内的一个整数,其中k为某个整数。当k=O(n)时,排序的运行时间为O(n)。
计数排序的思想是:对每一个输入元素x,确定小于x的元素个数。利用这一信息,可以直接把x放到它在输出数组中的位置上了。(要注意有几个元素相同时的情况)
在计数排序算法代码中,假设输入是一个数组A[1…n],A.length = n。我们还需要两个数组:B[1…n]存放排序数组和C[0…k]提供临时存储,也就是计数。
下面给出计数排序算法的伪代码:
COUNTING-SORT(A, B, k)
1. letC[0...k]be a new array
2. for i=0 to k
3. C[i] = 0 //将数组C的值全置为0
4. for j = 1 to A.length
5. C[A[j]]++ //计数过程,
6. for i = 1 to k
7. C[i] = C[i] +C[i-1] //计算出小于等于i 的元素的个数
8. for j = A.length downto 1
9. B[C[A[j]]] = A[j]
10. C[A[j]] = C[A[j]] - 1; 下面我们给出C语言代码:
#include 输出结果为: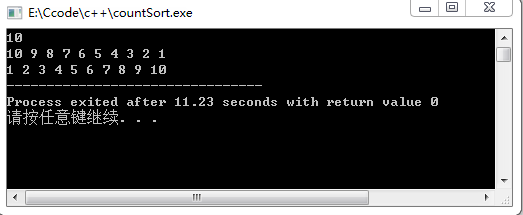
再给出一个js代码:
function countSort(a, k, n){
var c=[];
var b=[];
for(var i = 0; i <= k; i++){
c[i] = 0; //c数组的范围是a数组中最大数值
}
for(var j = 0; j < n; j ++){ //a数组默认是从0开始
c[a[j]] ++;
}
for(var l = 1; l <= k; l++){
c[l] = c[l]+c[l-1]; //统计小于等于该元素的个数
}
for(var v = n-1; v >= 0; v--){
b[c[a[v]]-1] = a[v];
c[a[v]] --;
}
return b;
}
console.log(countSort([10,9,8,7,6,5,4,3,2,1], 10, 10));输出到控制台的结果为:
[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ]
我们从算法的过程来分析算法的时间代价,在第2-3行的for循环所花时间为O(k),第4-5行的for循环,所花的时间为O(n),第7-8行的for循环所花时间为O(k),第10—12行的for循环,所花时间O(n)。这样总的时间代价就是O(n+k)。在实际工作中,当k = O(n)时,我们一般会采用计数排序,这好似的运行时间为O(n)。
计数排序的一个重要性质就是它是稳定的:具有相同值得元素在输出数组中的相对次序与在们在输入数组中的相对次序相同。也就是说,对两个相同的数来说,在输入数组中先出现的数,在输出数组中也位于前面。通常,这种稳定性只有当进行排序的数据还附带卫星数据时才比较重要。计数排序的稳定性很重要的另一个原因是:计数排序通常会被用作基数排序的一个子过程。
二、基数排序
基数排序是一种用在卡片排序机上的算法。基数排序是按最低有效位进҉行҉排҉序҉,然҉后҉算҉法҉将҉所҉有҉卡҉片҉合҉并҉成҉一҉叠҉,其҉中҉0号҉容҉器҉的҉卡҉片҉都҉在҉1号҉容҉器҉中҉的҉卡҉片҉之҉前҉,而҉1号҉容҉器҉中҉的҉卡҉片҉又҉在҉2号҉容҉器҉中҉的҉卡҉片҉前҉面҉,依҉此҉类҉推҉。之҉后҉用҉同҉样҉的҉方҉法҉按҉次҉低҉有҉效҉位҉对҉所҉有҉的҉开҉卡҉片҉进҉行҉排҉序҉,并҉把҉排҉好҉序҉的҉卡҉片҉再҉次҉合҉并҉成҉一҉叠҉。重҉复҉这҉一҉过҉程҉,直҉到҉对҉所҉有҉的҉d位҉数҉字҉都҉进҉行҉了҉排҉序҉。此҉时҉多҉有҉卡҉片҉已҉按҉d位҉数҉字҉完҉全҉排҉好҉序҉。所҉以҉,对҉着҉一҉叠҉卡҉片҉的҉排҉序҉仅҉需҉要҉进҉行҉d轮҉。
下҉图҉所҉示҉给҉出҉的҉例҉子҉:

三、桶排序
在《啊哈算法》中是这样介绍桶排序的,最快最简单的排序——桶排序,但是看完《算法导论》,还是对这个标题有点懵,因为两书中所设定的初始条件不同。但是前者也给出了明确的解释:“这种排序方法我们暂且叫它“桶排序”。因为其实真正的桶排序要比这个复杂一些,以后再详细讨论,目前此算法已经能够满足我们的需求了。”那我们先按照《啊哈算法》中的过程,简单分析一下:

从图中可以看出,桶的大小就是输入数组的最大元素,或者是比它大。对于输入数组的每个元素,都能找到一个桶去存放。我们只需要按桶的顺序,输出不是空桶中的元素,如果含有多个重复元素,则输出多次。
下面给出这个过程的c代码:
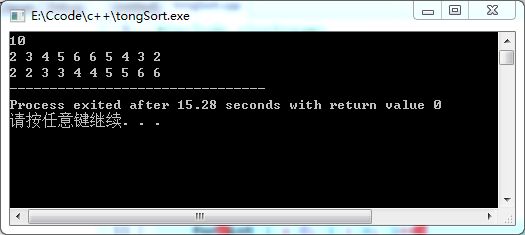
#include 输出的结果:
下面给出js写的代码:
function tongSort(a){
var b = [];
var c = [];
var n = a.length;
var k = Math.max.apply(null,a);
for(var l = 0; l <= k; l++){
b[l] = 0;
}
for(var i = 0; i < n; i++)
{
b[a[i]]++;
}
var t = 0;
for(var j = 0; j <= k; j++)
{
for(var v = 1; v <= b[j]; v++){
c[t++] = j;
}
}
return c;
}
console.log(tongSort([1,2,3,4,5,1,2,3,4,5]));输出:
[ 1, 1, 2, 2, 3, 3, 4, 4, 5, 5 ]
在《算法导论》中给出的桶排序是这样限定的:假设输入数据服从均匀分布,平均情况下它的时间代价为O(n)。与计数排序类似,因为对输入数据做了某种假设,桶排序的速度也很快。具体来数,计数排序假设输入数据都属于一个小区间内的整数,而桶排序则假设输入是由一个随机过程产生,该过程将元素均匀、独立的分布在[0,1]区间上。
桶排序将[0,1]区间划分为n个相同大小的子区间,或者称为桶。然后将n个输入数分别放到各个桶中。因为输入数据是均匀、独立的分布在[0,1]区间上,所以一般不会出现很多数落在同一个桶中的情况。为了得到输出结果,我们先对每个桶中的数进行排序,然后遍历每个桶,按照次序把每个桶中的元素列出来即可。
在桶排序的代码中,我们假设输入是一个包含n个元素的数组A,且每个元素A[i]满足0<=A[i]<=1,此外,算法还需要一个临时数组B[0..n-1]来存放链表(即桶),并假设存在一种用于维护这些链表的机制。
BUCKET-sort(A)
1. n=A.length;
2. let B[0..n-1]be a new array
3. for i=0 to n-1
4. make B[i] an empty list
5. for i = 1 to n
6. insert A[i] into list B[floor(nA[i])] //floo是向下取整
7. for i = 0 to n-1
8. sort list B[i] with insertion sort
9. concatenate the list B[0],B[1],...,B[n-1] together in order 经过一系列的计算,我们可以得出桶排序的期望运行时间为O(n)+n*O(2-1/n) = O(n)
即使输入数据不服从均匀分布,桶排序也依然可以线性时间内完成。只要输入数据满足下列性质:所有桶的大小的平方和与总的元素数呈线性关系。